TransVG: End-to-End Visual Grounding with Transformers
TransVG: End-to-End Visual Grounding with Transformers
2021-04-20 10:37:54
Official Code: Not available yet
Unofficial Code: https://github.com/nku-shengzheliu/Pytorch-TransVG
1. Background and Motivation:
本文提出了首个基于 Transformer 模型的 Visual Grounding 算法框架,从下图可以看到,主要包含四个模块:language-Transformer,Image-Transformer,Vis-Lang-Transformer,以及 prediction 模块。作者的实验表明结构化的融合模块并不是必须的,因为简单地进行 Transformer 编码层的堆叠就可以得到较好的效果。因为,attention layer 已经建模了模态内和模态间的对应关系,尽管不用任何特定的融合模块。此外,作者也发现直接回归矩形框位置,比之前任何一种方法,效果都要好。

2. Approach:
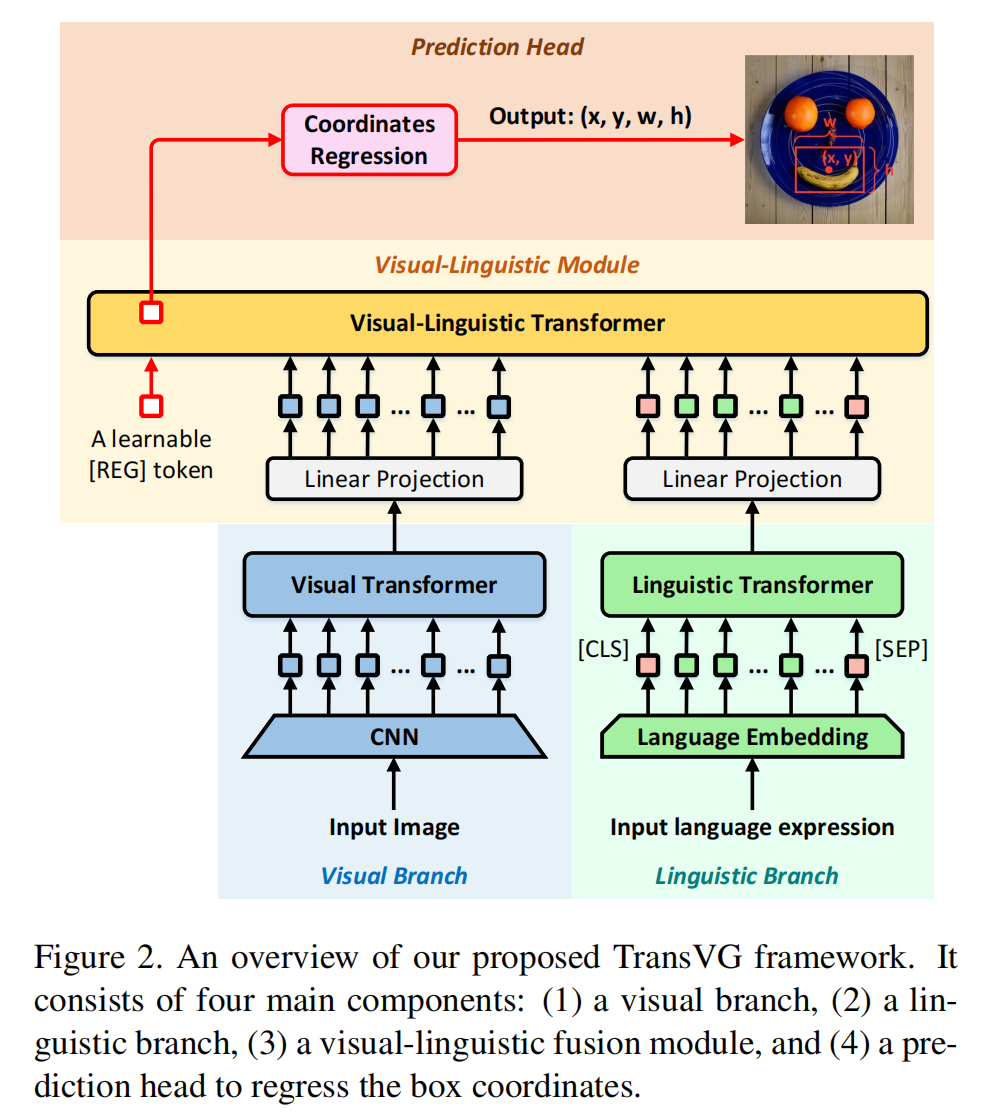
2.1. Visual Transformer:
给定输入图像,作者首先用 resnet 提取 CNN feature,然后用 1*1 conv 进行降维处理,得到 256-D 的特征。然后将这些特征图 reshape 为特征向量,因为标准的 Transformer 仅接收向量。然后用多头注意力机制进行处理。此外,作者也考虑了 sine spatial position encodings 进行位置编码,作为特征图的辅助输入。
2.2. Linguistic Branch:
这部分的结构和上面 Vis-Transformer 类似,但是为了更好的利用 pre-trained BERT model,作者这里尽量保持不动。利用了 12 个 transformer encoder layers,输出的特征维度为 768-D。
2.3. Visual-linguistic Fusion Module:
给定上述两个输入的特征,作者首先对 vis-feature 进行处理,使得两个模态的输入长度保持一致,即 256-D。然后,作者引入了一个可学习的 embedding,即 [REG] token, 并且将联合特征学习模块的输入调整为:

2.4 Prediction Head:
作者将 visual grounding 看做是一种回归问题。直接引入了 L1 smooth loss 和 GIoU loss function,进行损失方面的统计:

3. Experimental Results:
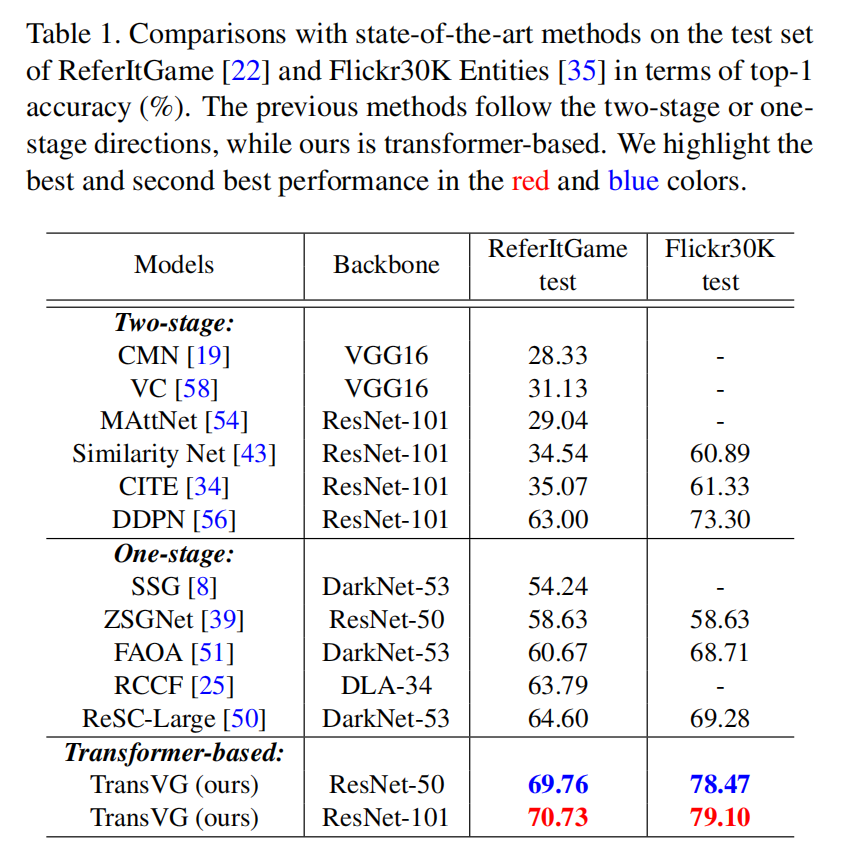
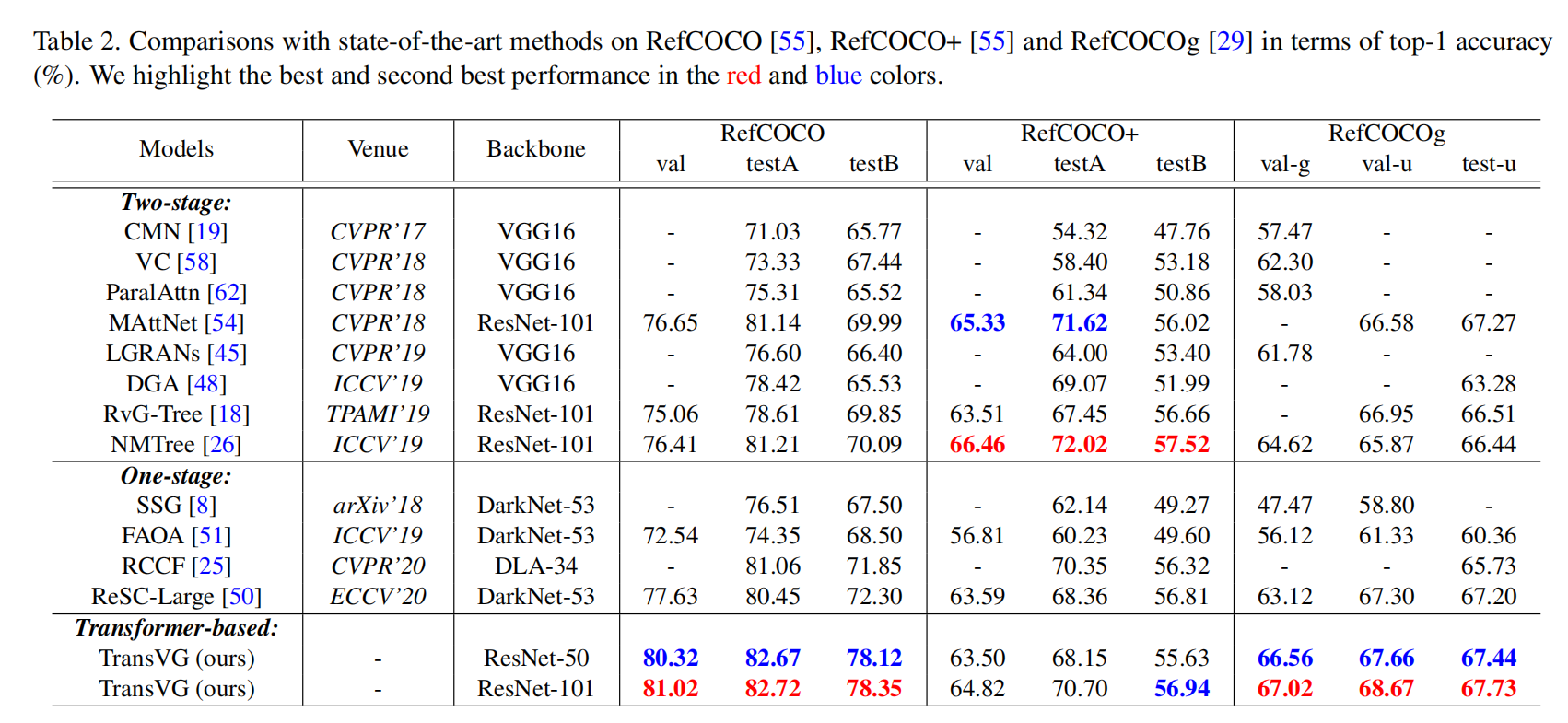

==
Stay Hungry,Stay Foolish ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号