Learning Long-term Visual Dynamics with Region Proposal Interaction Networks
Learning Long-term Visual Dynamics with Region Proposal Interaction Networks
2021-04-08 16:24:36
Paper: ICLR2021
Code: https://github.com/HaozhiQi/RPIN
Project: https://haozhi.io/RPIN/
Youtube: https://www.youtube.com/watch?v=Fk5oPOcXIc0
1. Region Proposal Interaction Networks:

如上图所示,本文将 N帧视频和对应的物体矩形框作为输入,然后输出的是未来 T个时刻的矩形框及其掩模 Mask。对于每一帧,作者利用 CNN 来提取其特征,然后采用 RoIPooling 提取物体的特征。这些特征然后被输入到 CIN 模块中,即 Convolutional Interaction Networks 来进行物体的交互推理,然后用于预测未来的物体矩形框位置及其掩模。整个框架可以做到 E2E 训练。
1.1. Object-Centric Representation:
作者这里用的是 houglass network来提取图像特征。相对比其他 CNN 骨干网络,该模型可以得到较大的感受野,然后用 ROI POOLING 操作,得到物体级别的特征图,维度为 h*w*d。
1.2. Convolutional Interaction Networks:
作者在这里首先介绍了前人基于 MLP 的交互网络,然后提出利用 convolutional 的方式来替换 MLP 的方法。大致思路如下所示:
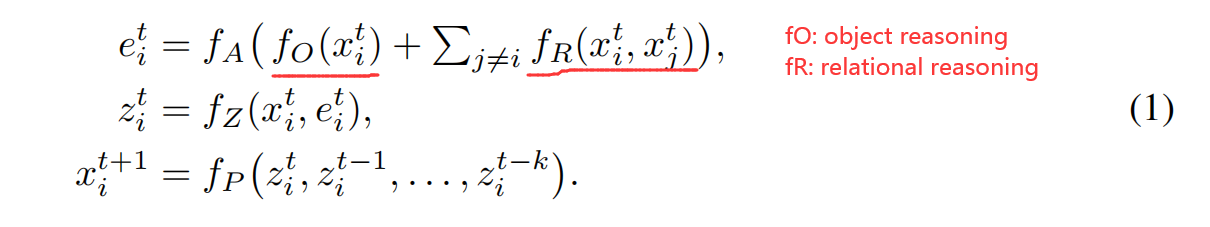
该网络将多个时刻的 m 个物体作为输入,然后进行 object reasoning fO 以及 relational raasoning fR。物体特征的更新就采用上述方式进行。此处,fA 是用于计算 fO, fR 结果的有效性。fZ 用于组合原始的状态和推理效果。最终,fP 在一个或者多个之前的物体状态上进行未来状态的预测。在 IN 中,所用到的网络结构都是 FC layers。
作者在这个工作中,将这个 MLP 改为 Convolutional 的方式,这样就可以充分利用空间信息来进行未来状态的推理。具体来说:
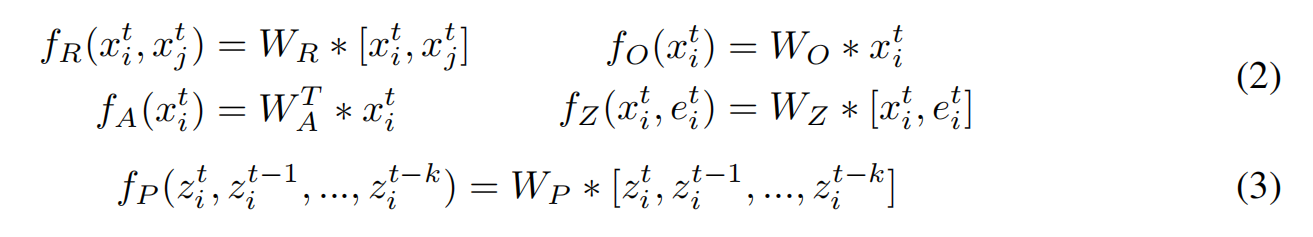
其中,* 代表卷积操作,[, ] 是 concatenate 操作,W 代表卷积核大小为 3*3 的可学习权重。在每一个卷积操作后,作者添加了 ReLU 激活函数。
1.3. Learning Region Proposal Interaction Network (RPIN):
作者提出的模型可以直接预测未来的 BBox 以及每一个物体的 mask。这个 mask 是可选择的。给定编码后的特征,作者利用两层简单地 MLP decoder 来预测矩形框的坐标和 mask。
矩形框解码器:将折叠后的物体特征图作为输入,首先将其映射为 d 维的向量,然后输出一个 4-d 的坐标;分别代表矩形框的中心点以及宽高;
掩模解码器:拥有和矩形框解码器相似的结构,但是输出的是 21*21 的维度,对应了空间大小为 21*21 的二值掩模。
作者这里利用 L2 损失函数来计算 BBox 之间的差异,用交叉熵损失函数来计算掩模的损失,总的来说,损失函数的计算可以总结为:
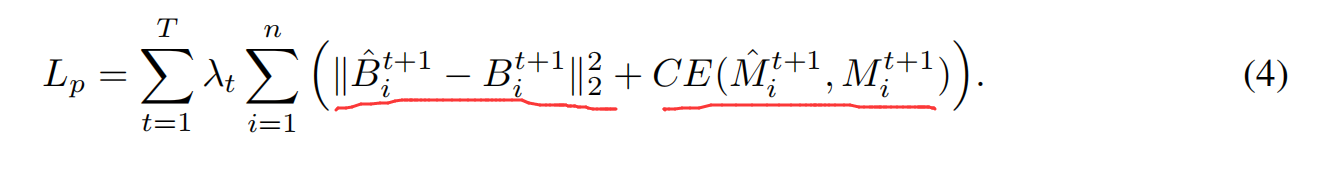
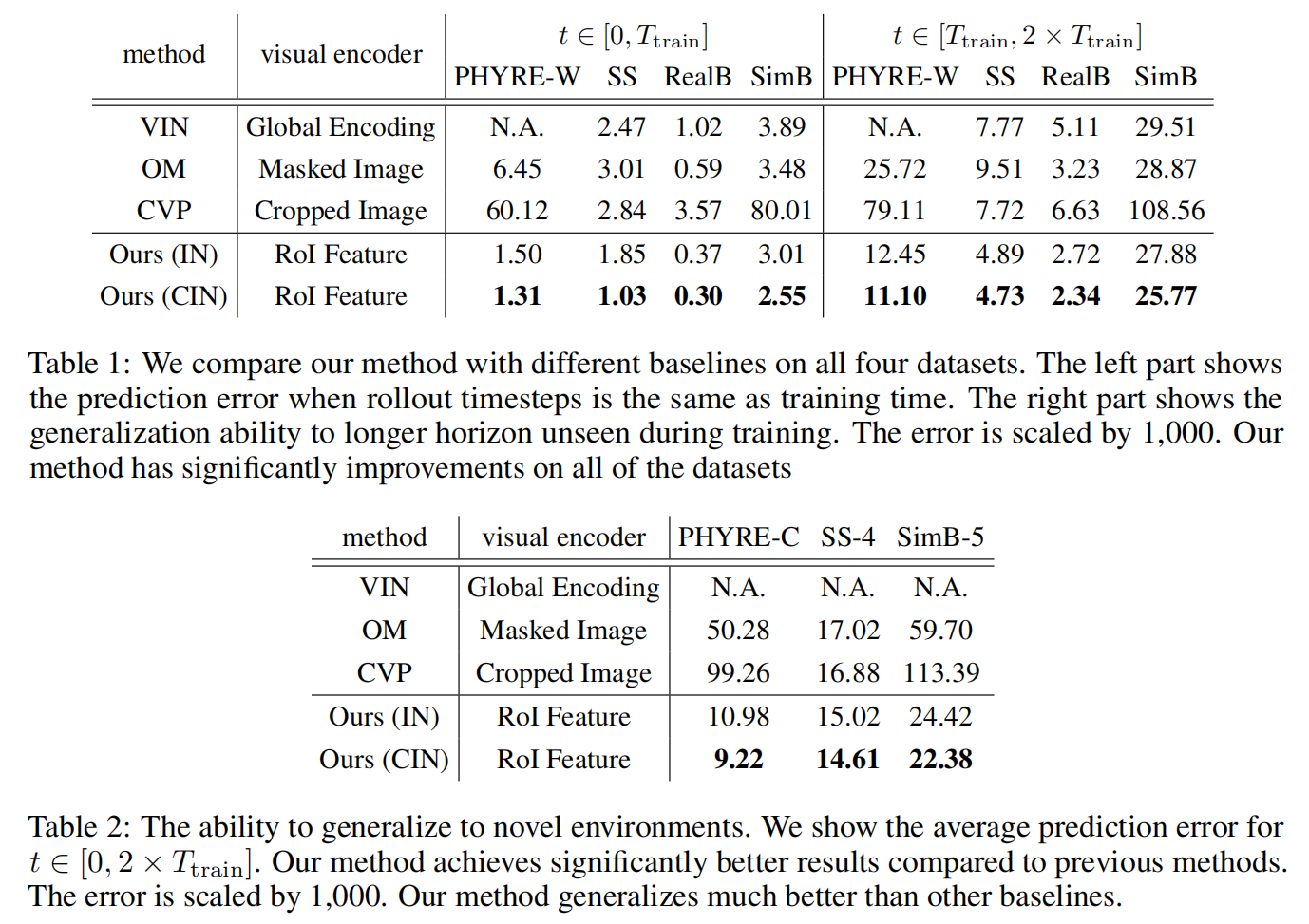
2. Experimental Results:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号