Trear --- Transformer-based RGB-D Egocentric Action Recognition
Trear --- Transformer-based RGB-D Egocentric Action Recognition
2021-01-13 13:05:44
Paper: https://arxiv.org/pdf/2101.03904.pdf
1. Network Architecture:

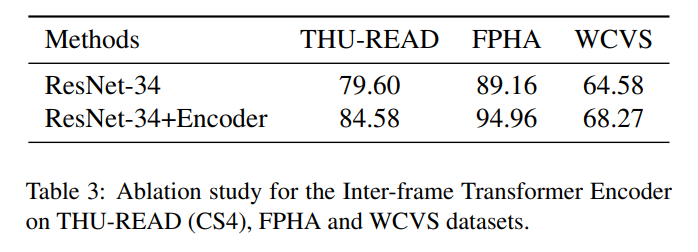
- Inter-frame Transformer Encoder:
给定一个 action clip,作者首先对每一个图像的 feature map 进行 average pooling,得到 feature embedding,其大小为 512。为了得到序列中每一个 frame 的位置编码,作者利用别人提出的编码方法【First person action recognition using deep learned descriptors,cvpr-2016】,进行位置编码:
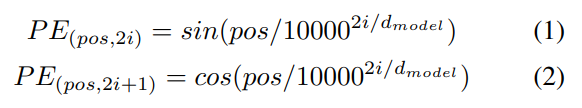
其中,pos 是位置,i 是维度。位置编码和特征映射具有相同的维度,因此这两个值可以相加。剩下的结构服从标注的 transformer 结构,如图 2 所示。在得到特征映射后,执行多头注意力。具体来说,feature 首先映射为一系列的向量 query Q,key K,value V。然后利用如下的公式,得到每一个 head 的输出:
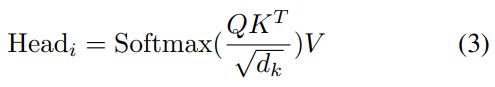
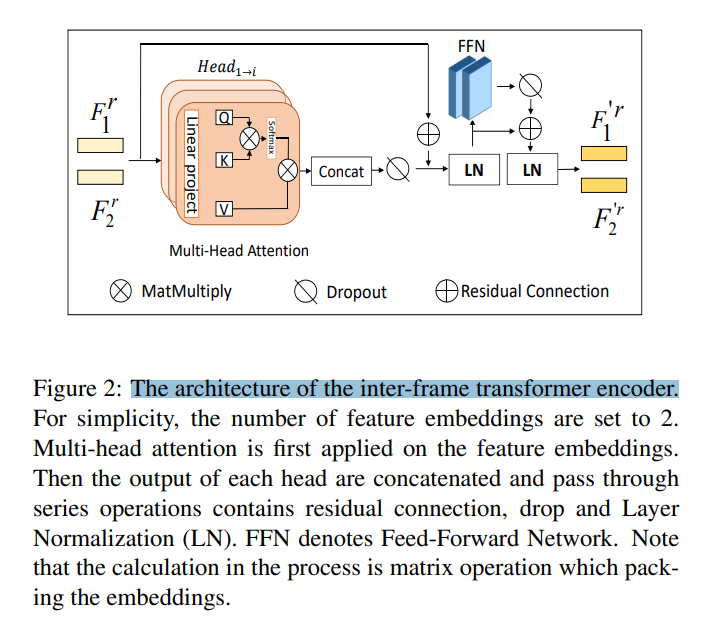
每一个 head 的输出都进行堆叠,然后输入到一组序列中,包括:dropout,residual connection,以及 layerNorm:

其中,Fr 是输入特征映射的组合,F'r 是 transformer encoder 的输出特征。Feed-Forward Networks (FFN) 是由两组卷积核为 1 的卷积层构成的。整个计算过程是基于 matrices calculation。
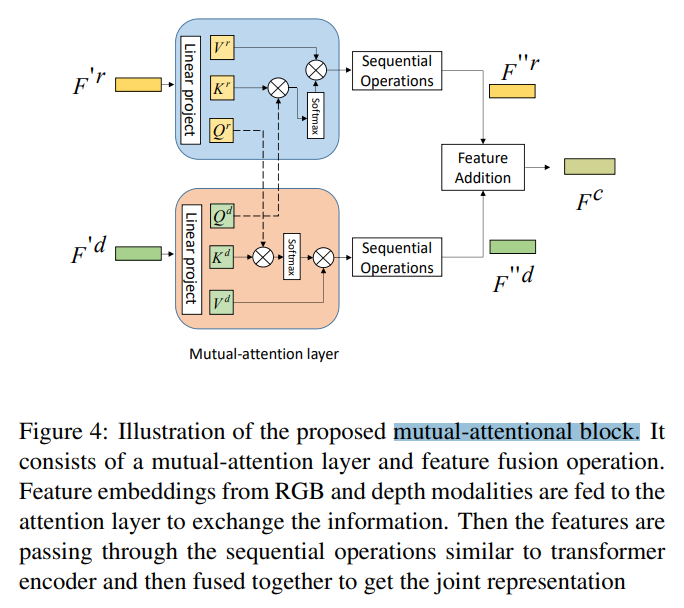
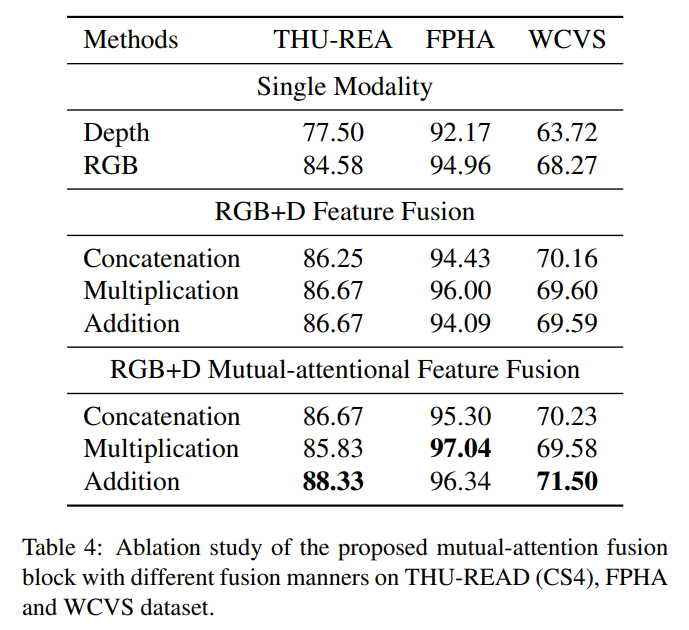
- Mutual-attentional Feature Fusion:
在分别对两个模态 RGB 和 Depth image 进行处理后,作者引入 Mutual-attention 来进行特征融合。这里的思路类似 co-attention,即:利用某一个模态去引导另外一个模态的特征学习,反之亦然。Specifically, it calculates the RGB feature attention in depth modality and depth feature attention in RGB modality and produces corresponding cross-modality features, respectively.
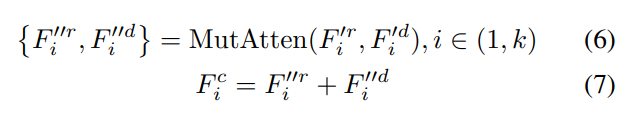
可以看到,得到的两个模态的特征直接相加,得到最终融合后的特征。
作者给出了与 co-attention 机制的不同:
1) the two modalities data RGB and depth are restricted aligned, RGB frames and depth maps are one-to-one correspondence. For vision-and-language tasks, words and visual inputs often suffer from mismatch issues, which affects the attention computation among inputs.
2) the modality gap between visual feature and word embedding is much complex. While both RGB and depth are image-level visual features, which makes them interacted with each other through the mutual-attention layer more effective and straightforward.
但是,感觉这里说的两点,不是本文 mutual-attention 和 co-attention 的区别,而是 RGB-Depth 与 RGB-Language 两者模态数据的不同及其影响。看起来,如果说区别的话,最好还是说,这是一种基于多头注意力机制实现的 co-attention,而用于 RGB-language 任务的 co-attention 更像是常规 attention 的实现方式。我觉得这里的 mutual-attention 仍然属于 co-attention,算作是一种新的 co-attention 实现方式吧。毕竟都是两个模态相互加权,相互融合的过程。
2. Experimental Results:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号