Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
2021-01-02 00:19:30
Paper: https://arxiv.org/abs/2012.15840
Code: https://github.com/fudan-zvg/SETR
本文首次将 Transformer 模型用于替换语义分割的骨干模型,即连基础的 CNN 的模型都不用。纯粹的 transformer 模型做 CV 任务,ViT 是第一个工作:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale[J]. arXiv preprint arXiv:2010.11929, 2020. [Paper] [Code]。在此之前,ECCV-2020 也有一个工作:Axial-DeepLab: Stand-Alone Axial-Attention for Panoptic Segmentation 是纯粹基于 self-attention 来做的。但是这两个工作的主要区别在于:Axial-DeepLab 仍然是采用 encoder-decoder 的框架来做语义分割,即:首先降低分辨率,再提升分辨率的过程。那么,本文就思考,能够利用 transformer 模型,不进行类似降低分辨率的操作呢?
如下图所示,本文借鉴了 ViT 模型,对图像划分 patch 块,然后利用 fc 进行映射以及位置编码。得到对应的表达后,利用 transformer 模型,进行处理。这一块就是作者用到的 Encoder 模型。该过程中一直没有整副图的概念,均是在处理 local patch,所以没有 feature maps 分辨率降低的概念。得到这些 patch 块的表达后,进行 reshape,得到整个图的 feature map,然后利用 decoder模型进行上采样,得到预测结果。
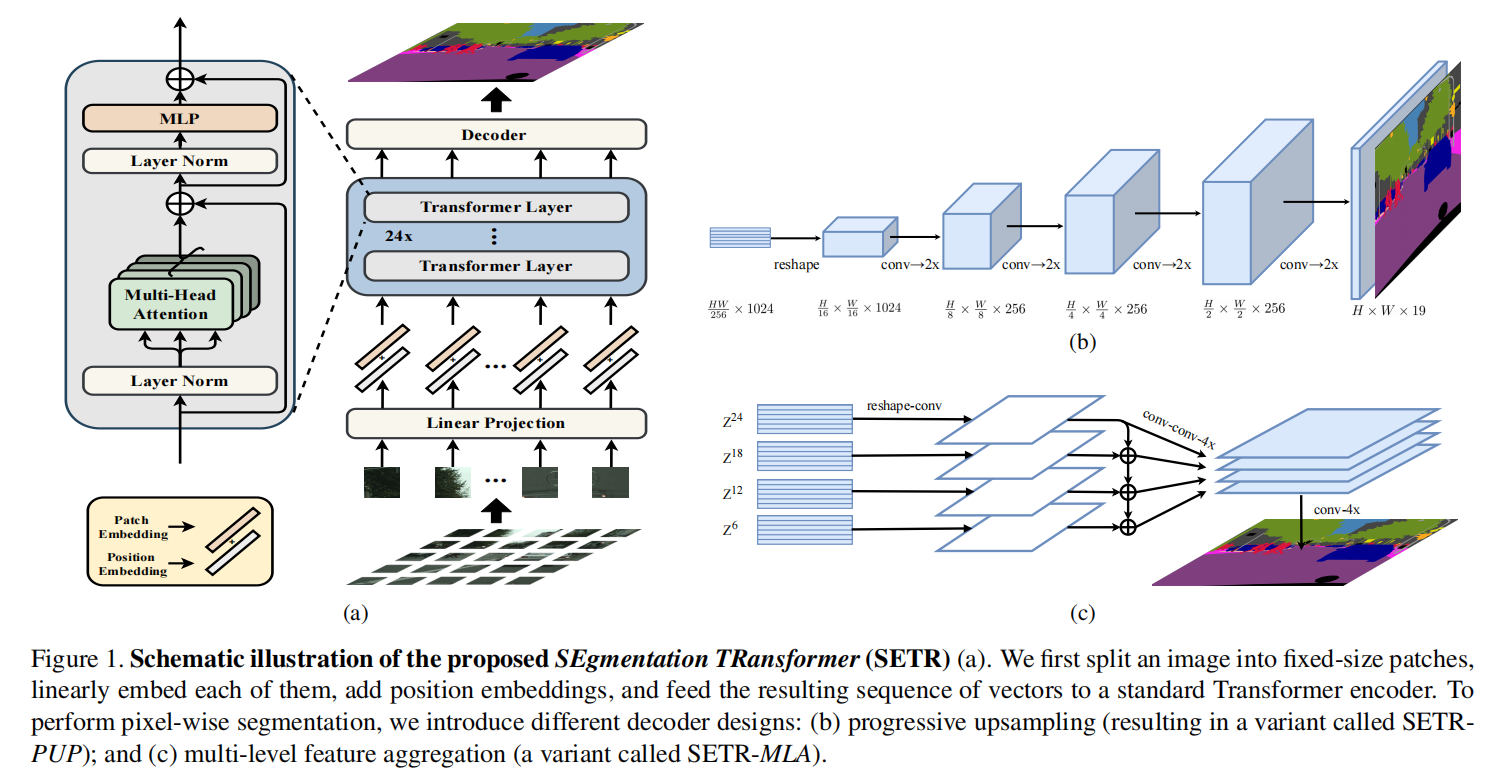
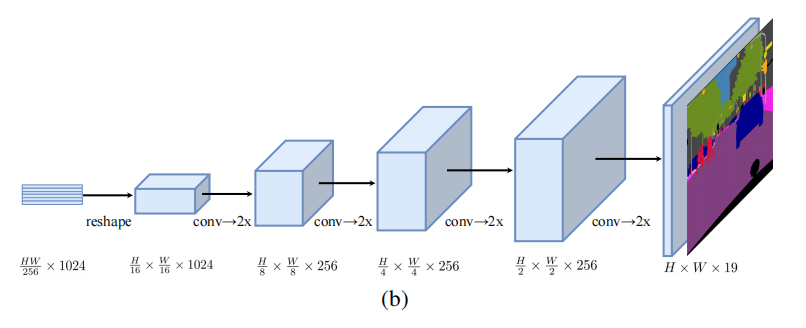
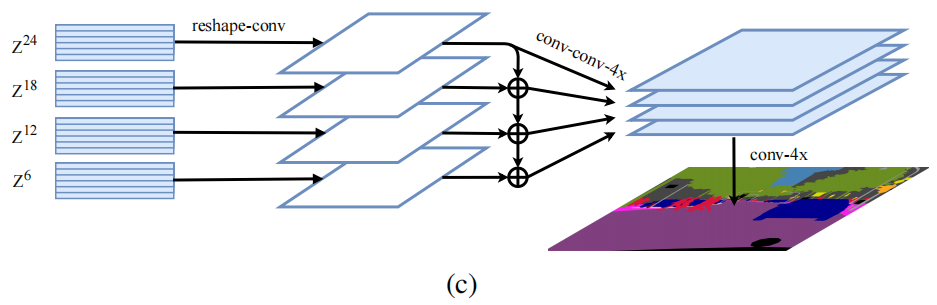
其中,作者设计了多种 decoder 模型,来进行实验,如下所示:
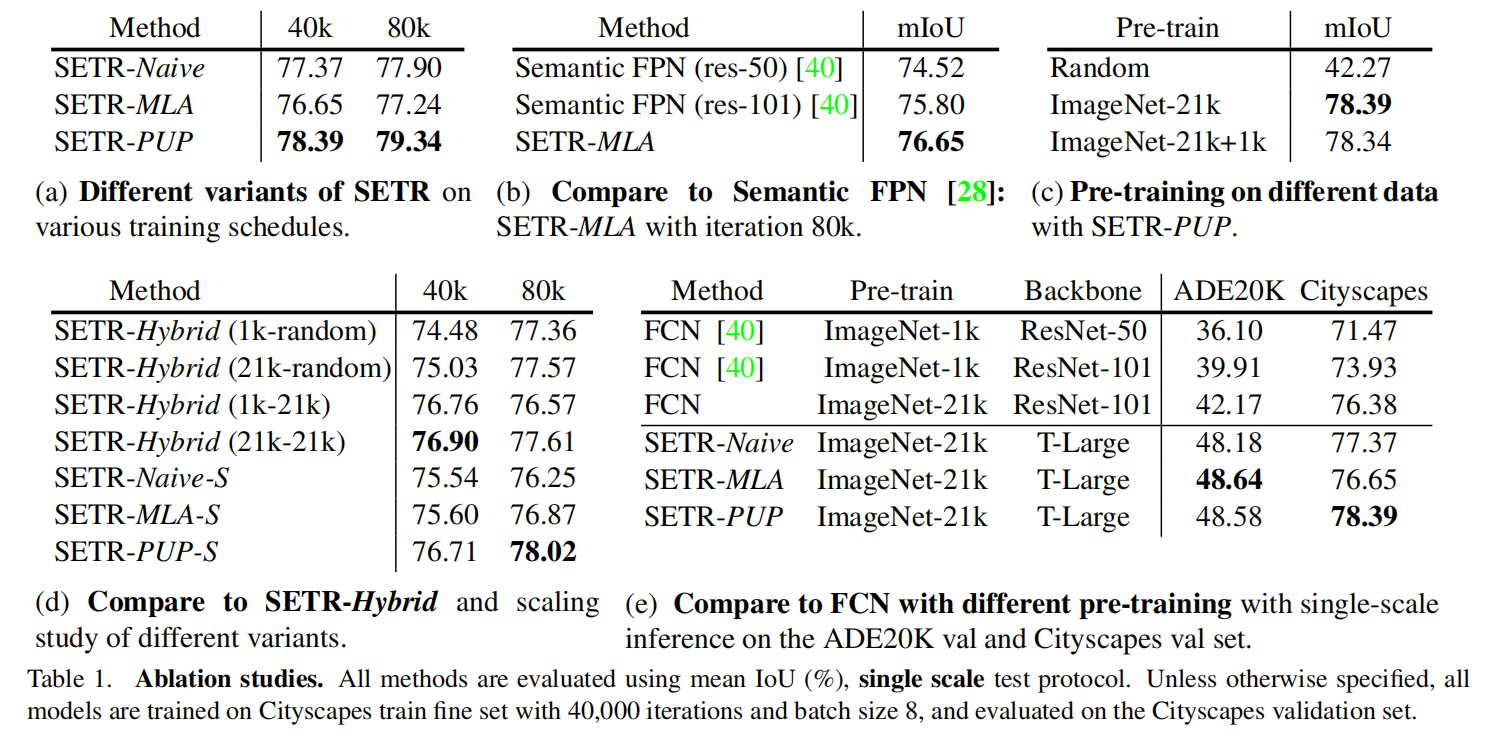
2. Experiment:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号