Large-Scale Adversarial Training for Vision-and-Language Representation Learning
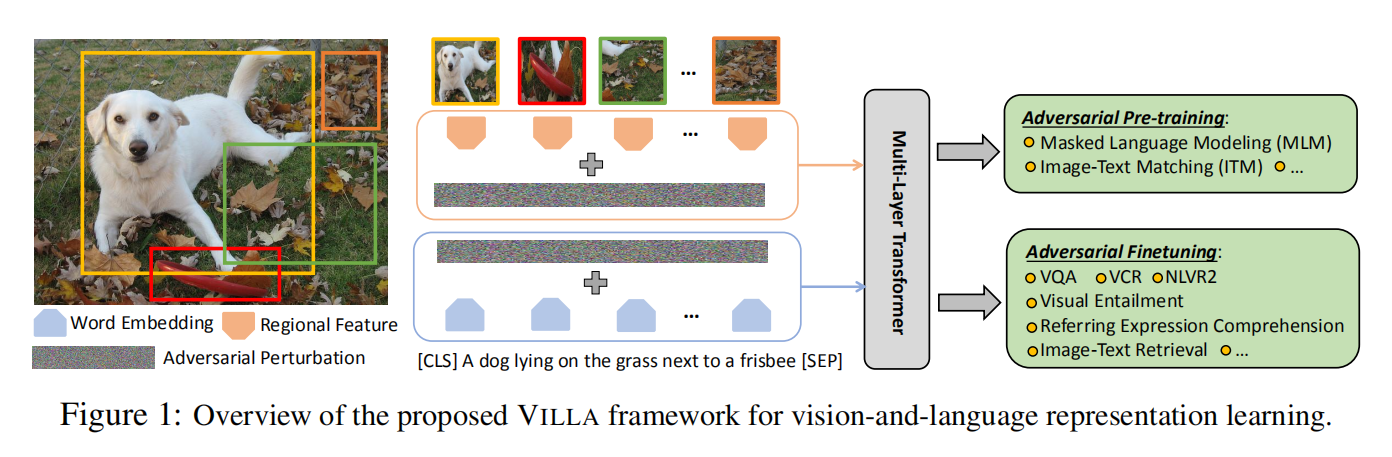
该方法的核心部分有如下三点:
- 对抗的预训练和微调机制;
- 在映射空间添加干扰;
- 增强的对抗训练方法;
1. 对抗预训练与微调:
Pre-training:
给定预训练数据集,包含 image-text pairs,训练的目标就是在这个大型数据集上学习一些与任务无关的特征。常用的预训练方法有三种:
- Masked language modeling
- Masked region modeling
- Image-Text matching
Finetuning:
给定具体的任务和监督学习数据集,可以在上面预训练模型参数的基础上针对不同的任务进行微调。
Two-stage Adversarial Trainer:
预训练和微调在本质上是紧密联系的。模型的训练需要掌握本质的推理技巧,从而促使模态融合,进行跨模态的联合理解。作者认为:
- 通过在 pre-training stage,执行对抗训练, 改善的泛化能力对微调阶段也是有益的;
- 在微调阶段,任务相关的微调信号变得可用,对抗微调可以用于进一步的改善性能。
由于 pre-training 和 finetuning 共享同一个数学表达式,同样的对抗算法可以在两个阶段都采用。
2. Perturbations in the Embedding Space:
对于 image modality,由于最新的 V-L 模型通过将 pre-trained object detectors 作为输入,作者就直接在特征空间添加干扰。在预训练的 V+L model 中,位置映射是用于编码图像区域的位置和单词的索引。本文的方法仅仅改变了 image 和 word embedding 的映射,其他的多模态特征未变。此外,由于 image 和 text 模态的不同,作者仅对其中的一个模态添加扰动。这里加的扰动不能太大,否则会改变原始的语义信息,这是不能接受的。
3. “Free” Multimodal Adversarial Training:
实验中用的总体损失函数为:
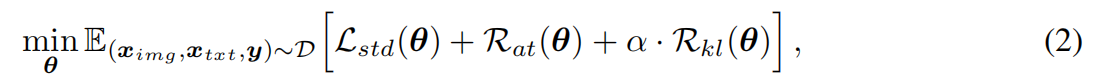
其中,第一项为交叉熵损失函数,第二个为 label-preserving AT loss,第三个是细粒度对抗正则化项。具体来说,AT 损失为:
![]()
其中,L 是对抗映射的 交叉熵损失。正则化项为:
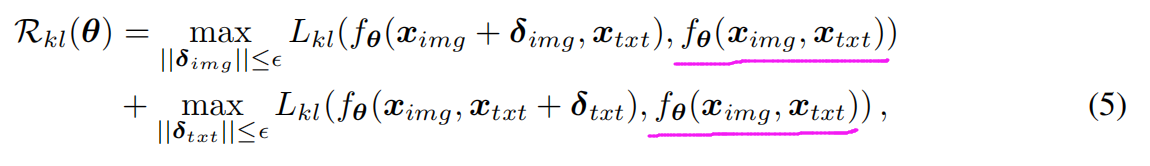
这里是想使得原始特征 和 添加干扰后的特征,尽可能保持一致。总体算法流程见 Algorithm 1

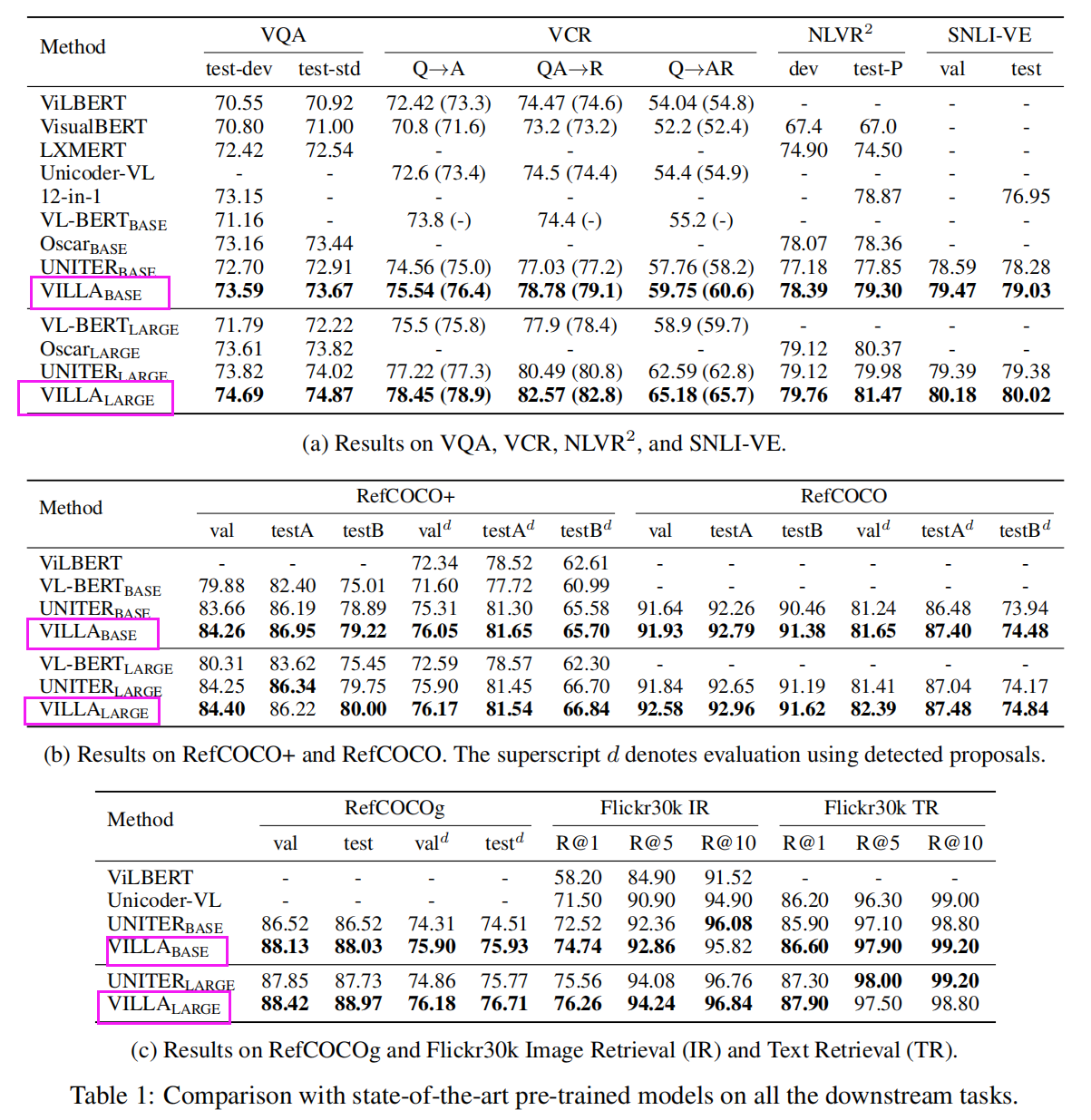
在各种主流 V-L 任务上,都取得了一定程度上的提升:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号