End-to-End Object Detection with Transformers
End-to-End Object Detection with Transformers
2020-05-27 11:05:14
Paper: https://arxiv.org/pdf/2005.12872.pdf
Code: https://github.com/facebookresearch/detr
Blog: https://ai.facebook.com/blog/end-to-end-object-detection-with-transformers
Youtube Tutorial: https://www.youtube.com/watch?v=T35ba_VXkMY
Extension:Deformable DETR: Deformable Transformers for End-to-End Object Detection, Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, Jifeng Dai [arXiv]
Facebook 的工作,构建了一种基于 transformer 的物体检测框架。大致结构如下图所示:
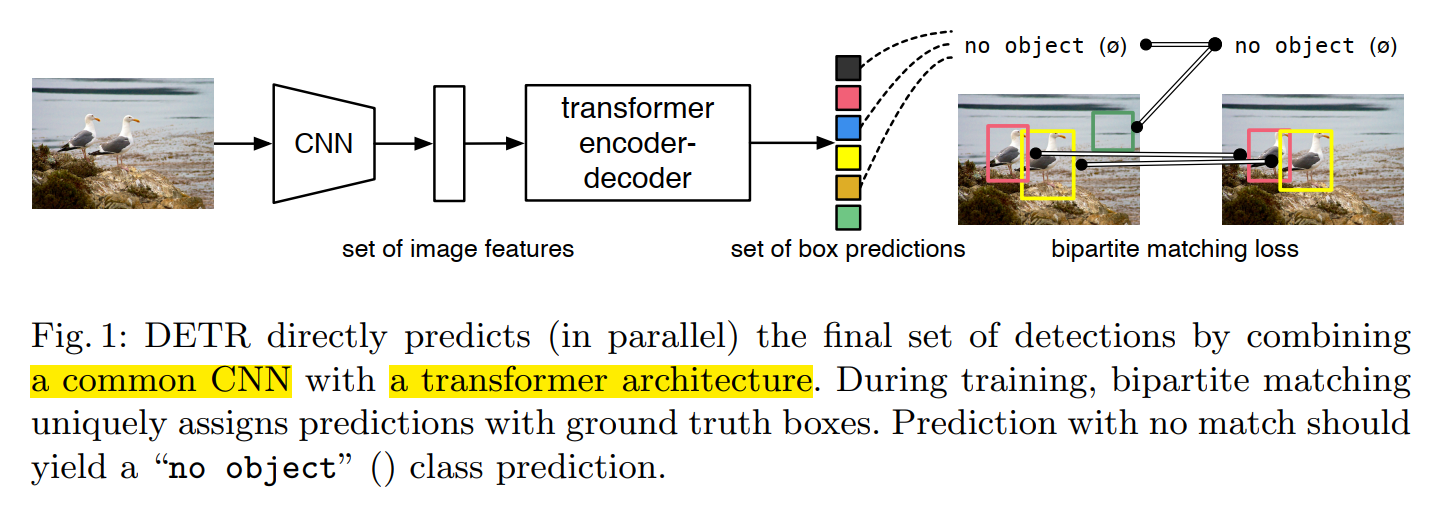
给定图像,先用 CNN 抽取其特征,然后用 transformer 结构来直接预测得到 BBox 的结果。一般来讲,作者会预测得到非常多的 框框,同时为了 loss 的计算,作者也对 GT 的 BBox 进行填充。
本文所提出的 DETR model 有两个不可缺少的部分:
1). a set prediction loss, 用于计算预测 和 真值 之间的差异;
2). an architecture, 预测一组物体并且建模他们之间的关系。
1. DETR 会直接推理出一组固定大小的 N 个预测结果,通过 decoder 可以一次搞定这个事情。这里的 N 会明显的比常规物体个数要多。训练的一个困难是,对预测的物体进行打分,关于 class, position, size 等。本文的 loss 产生了一个最优的二值匹配,然后优化一个 object-specific losses。
为了计算预测的 BBox 和 真值 BBox 两个集合之间的差异,作者利用如下的方式,得到 N 个元素的置换:
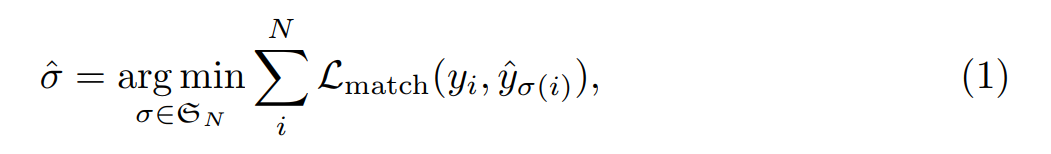
其中,$L_{match}$ 是一个 pair-wise matching cost。该最优的赋值是利用 Hungarian algorithm 来计算得到的。这个 matching cost 考虑到了 class prediction 和 similarity。
![]() 是
是 ![]()
其中,ci 是目标类别标签,bi 是向量代表了真值 BBox 中心点坐标及其宽高。作者提到这个寻找 matching 的过程类似于 匹配 proposal 或者 anchors 机制。这里主要的区别是,需要找一个 one to one matching,而不需要重复。
第二步是计算 loss function,在上一个步骤中,所有 pairs 的 Hungarian loss。
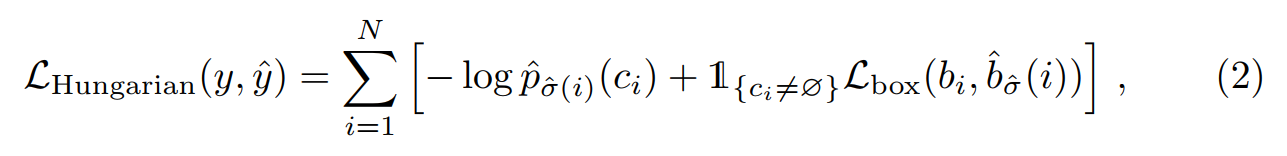
其中,$\hat{\delta}$ 是步骤 1 中得到的 optimal assignment。
公式 2 中的第二项是 matching cost 和 Hungarian loss,对 BBox 进行打分处理。作者这里采用了 L1 loss 和 generalized IoU loss。总体来说,本文的 BBox loss 定义为:
![]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号