What's new for Transformers at the ICLR 2020 Conference?
What’s new for Transformers at the ICLR 2020 Conference?
2020-05-07 10:51:22
Source: https://towardsdatascience.com/whats-new-for-transformers-at-the-iclr-2020-conference-4285a4294792
Transformers are attention-based neural architectures that propelled the field of NLP to new highs after their introduction. The International Conference on Learning Representations has a healthy dose of them, so here’s a curated collection of related publications that will help you navigate them.
The International Conference on Learning Representations (ICLR) is one of the most beloved stages for the Machine Learning community. Nowadays, conferences in the field often serve as a quality trademark and a spotlight for publications that already exist in pre-print servers. Still, the volume of work presented is growingly overwhelming, which makes it hard to keep up.
At Zeta Alpha, we keep a close eye at the forefront of Natural Language Processing (NLP) and Information Retrieval (IR) research. In this spirit, and with the help of our semantic search engine, we’ve curated a selection of 9 papers — out of more than 40! — related to Transformers that are making an appearance at ICLR 2020 from 3 main angles: architecural revisions, innovations for training and spin-off applications. Enjoy!
🏛 Architectural Revisions
Meet the latest reincarnations of Transformer models.
1. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations | ICLR session
Transformers have largely become overparametrized, as this has been a successful recipe for achieving state-of-the-art in several NLP tasks. Alternatively, ALBERT is an already influential example about how BERT can be made way less resource hungry while maintaining the impressive performance that made it famous.
These optimizations include:
- Factorized embedding parameterization: by using different hidden size than the wordpiece-embedding size, the embedding parametrization can be factorized, decreasing its size from O(Vocab × Hidden) to O(Vocab × Emb + Emb × Hidden), which can be substantial if Hidden ≫ Emb.
- Cross-layer parametrization sharing: reusing parameters for different transformer blocks, such as the FFN and/or attention weights.
- Sentence Ordering Objective: the authors argue that next sentence prediction from the original BERT is not challenging enough, introducing this new sentence-level self supervised objective.
The result? 18x fewer parameters compared to BERT-large at comparable performance and slightly faster inference.
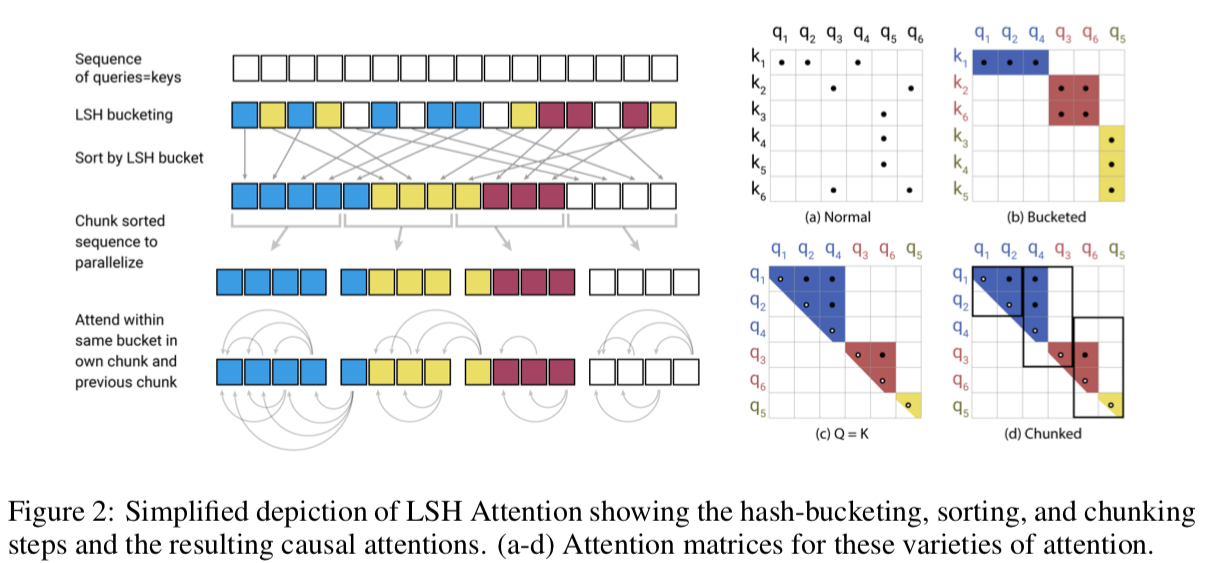
2. Reformer: The Efficient Transformer | ICLR session
One of the limitations of early Transformers is the computational complexity of the attention mechanism scaling quadratically with sequence length. This work introduces some tricks to allow for more efficient computation, which enables modeling attention for longer sequences (up from 512 to 64k!). To do so, the backbone of the model includes:
- Reversible layers that enable storing only a single copy of activations in the whole model.
- Approximating the attention calculation by fast nearest neighbors using Locality-Sensitive Hashing (LSH). This replaces the O(L²) factor in attention layers with O(L log L).
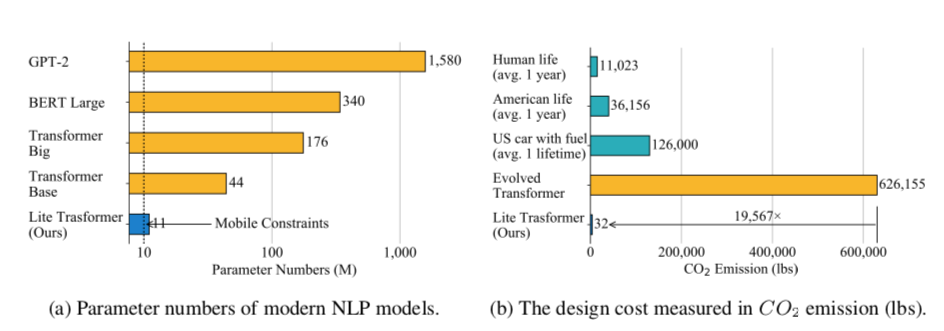
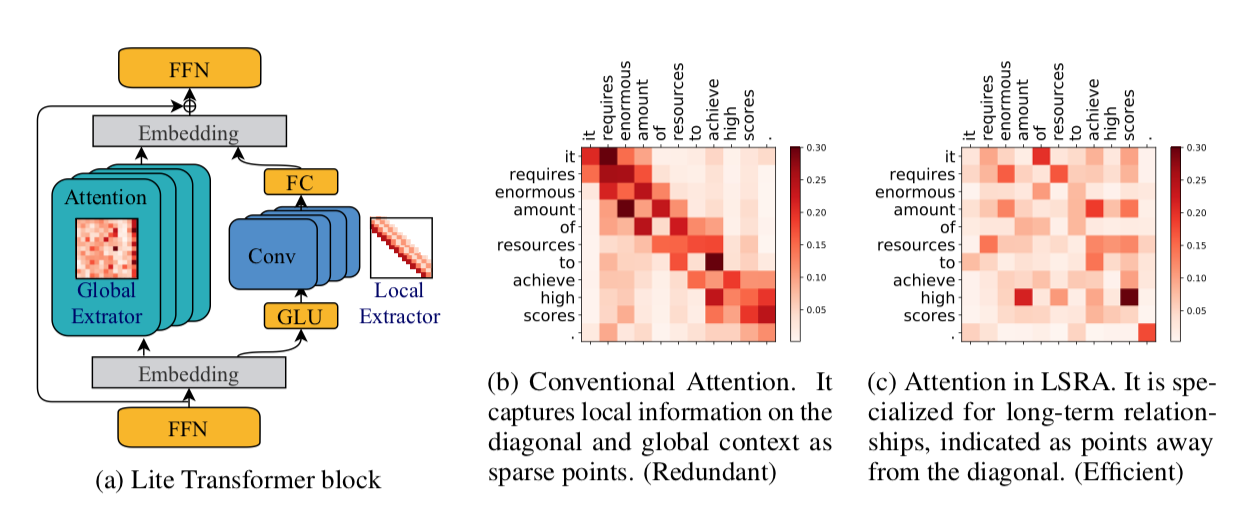
3. Lite Transformer with Long-Short Range Attention (LSRA) | ICLR session
Here’s another proposal to overcome long range dependencies and high resource demands in Transformers by imposing what they call “mobile constraints”. This time, using convolutions for short term dependencies and selective attention for long range ones, they create a new transformer LSRA building block that’s more efficient.
Although results are not competitive with other full-fledged flagship Transformers, the principled architectural design and thoughtful motivations behind it make this a worthy mention.
Honorable mentions: Transformer-XH, Depth-Adaptive Transformer, Compressive Transformer.
🧠 About Learning
How models learn is just as crucial as how models look, so here are some refreshing publications pushing the boundaries of how Transformers do so.
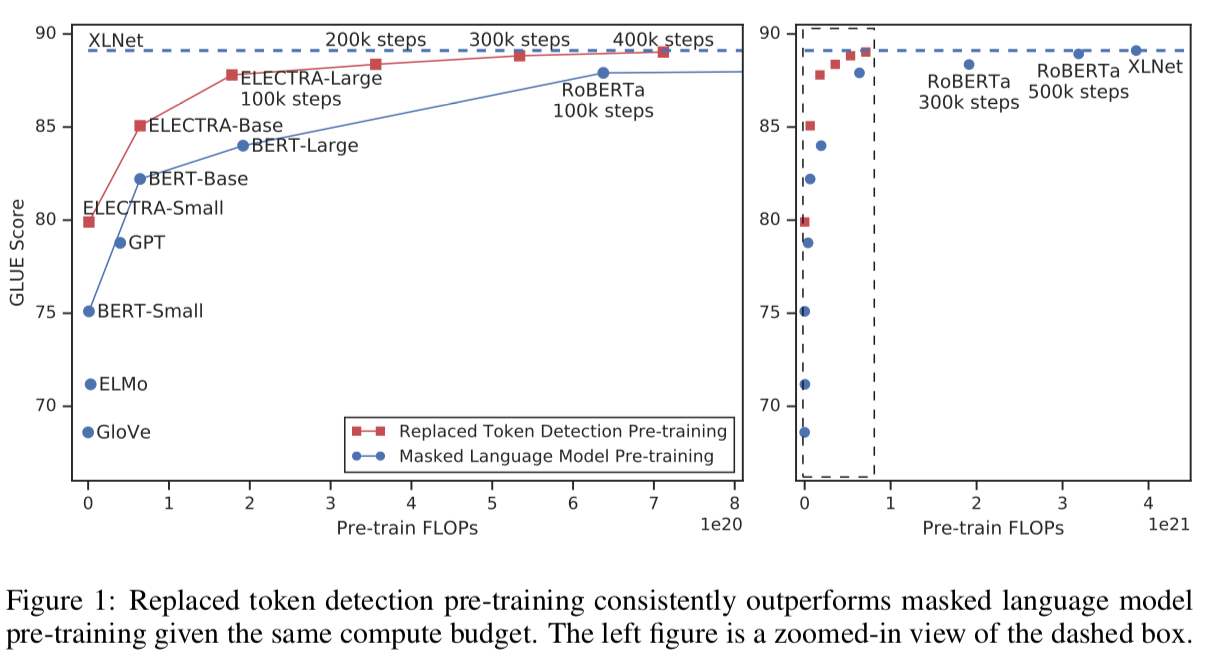
1. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators | ICLR session
Masked Language Modeling (MLM) has been the learning foundation of pre-training objectives for models since the introduction of BERT. This paper proposes an alternative that could be cheaper and faster: Replaced Token Detection.
The main idea is very simple: instead of making the model guess masked tokens, it needs to discriminate which ones were replaced by a small generator network that proposes plausible but wrong tokens. The authors claim that this objective is more sample-efficient than MLM, as the task is defined over all the sequence instead of only the masked tokens. If these results prove themselves to be easily reproducible, this task has the potential to become a new standard for unsupervised pre-training.
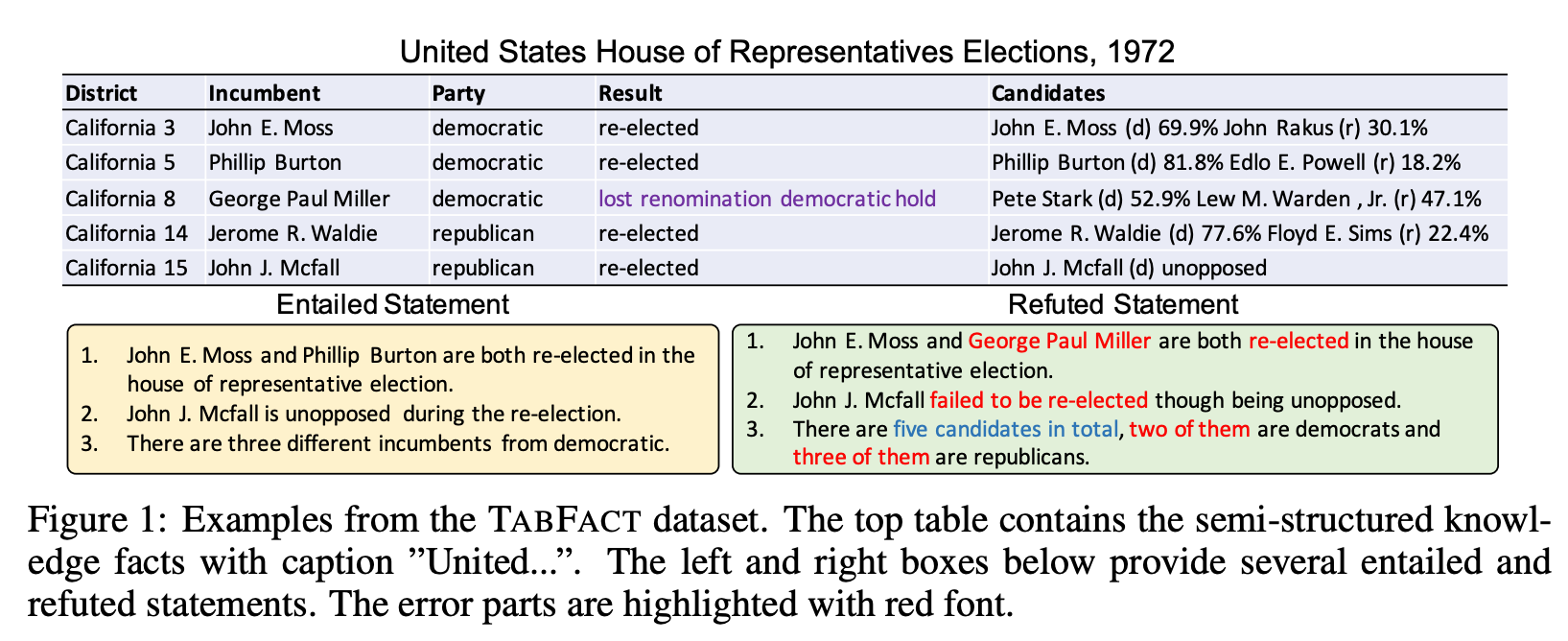
2. TabFact: A Large-scale Dataset for Table-based Fact Verification | ICLR session
Many of the classical NLP datasets are becoming obsolete as modern Transformers close the gap with human performance, which means new more challenging benchmarks need to be created to stimulate progress. In this case, a new dataset is proposed to tackle the problem of modeling fact-based information expressed on natural language.
It consists of 16k tables from wikipedia and 118k human anotated statements with ENTAILMENT or REFUTED labels that refer to the factual data. Performance of the baselines is still mediocre, so it’s an exciting time to innovate solving this task!
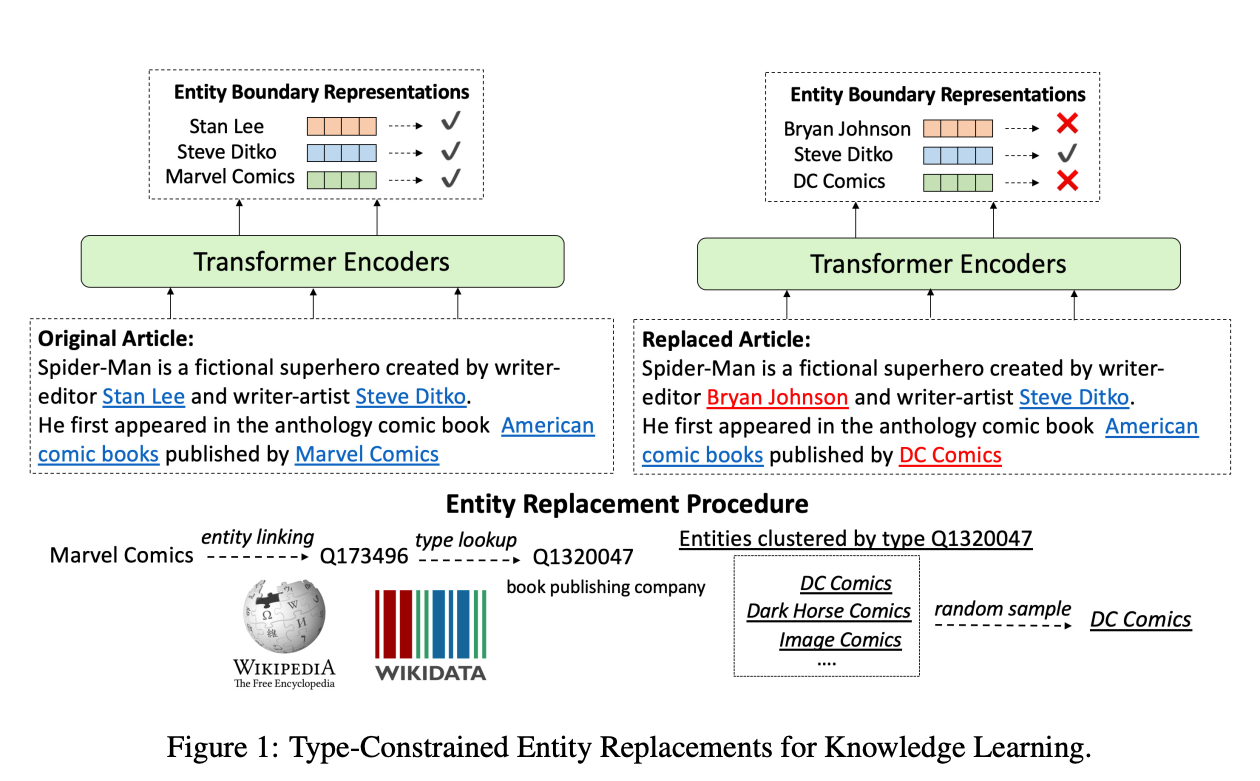
3. Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model | ICLR session
Instead of applying the vanilla MLM objective, this work explores the power of self-supervised training from slightly more structured data: Wikipedia and its entities. They replace entities in text with other similar-type entities (a la ELECTRA) and the model learns to discern the replaced instances by context. Using this method, the model is forced to learn information about real world entities and their relationships.
When this task is combined with classical MLM in pre-training, it results in a substantial increase in performance for zero-shot fact completion and improved performance in entity-centric tasks such as Question Answering and Entity Typing.
Honorable mentions: A Mutual Information Maximization Perspective of Language Representation Learning; Improving Neural Language Generation with Spectrum Control; Large Batch Optimization for Deep Learning: Training BERT in 76 minutes.
🤖 Spin-off Usages
Transformers are not only about Language Modelling. Here are some works that cleverly use the power of these models to solve related problems.
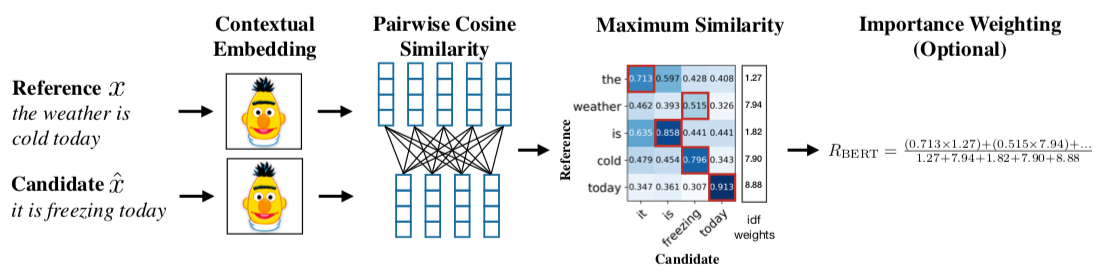
1. BERTScore: Evaluating Text Generation with BERT | ICLR session
Objectively measuring quality under loosely defined environments (i.e. generation of coherent text) is intrinsically challenging. In language, BLUE score is widely used as a proxy for text similarity that correlates fairly well with human judgement for text generation tasks such as Translation or Question Answering, but it’s still far from perfect.
This work addresses this problem and shows how a Bert-based scoring function for sequence pairs can be designed for text generation that correlates better with human judgement. The process is very straightforward and does not involve any fine-tuning: only pre-trained contextualized embeddings, cosine similarities and frequency-based importance weighting.
Despite some loss of explainability, could this kind of learned scoring become a new standard? Only time will tell.
2. Pre-training Tasks for Embedding-based Large-scale Retrieval | ICLR session
The field of Information Retrieval has been late to the neural revolution, given how strong and hard to beat simple baselines like BM25 are. Currently, most neural-enhanced SOTA approaches require two main steps: a first fast filtering over the whole document set — based on BM25-like algorithms — and a re-ranking step where the query and a small subset of documents are processed through a Neural Network. This approach presents many limitations because any documents missed in the first step will not be processed further and the computational cost of fully processing query and document pairs at inference time severely limits real-world applicability.
This work explores instead the constrained problem where the inference can only be done by an embedding similarity score of pre-calculated document representations, enabling large-scale end-to-end Transformer-based retrieval.
The key insight to be drawn is that pre-training with paragraph-level self-supervised tasks is essential, while token-level Masked Language Modeling has a negligible impact for this particular task. In the results section they show how BM25 can be beaten for Question Answering tasks even under relatively scarce supervised training data.

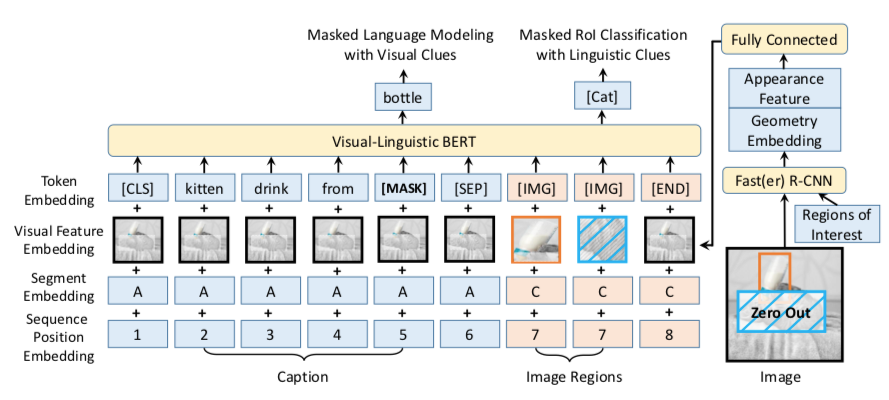
3. VL-BERT: Pre-training of Generic Visual-Linguistic Representations | ICLR session
How can the pre-training and fine-tuning framework be leveraged to jointly learn generic language and visual representations? Here we find a great example: Visual-Linguistic BERT takes the Transformer architecture as a backbone along with R-CNNs. Although this is not the first of its kind, it’s a refreshing improvement over existing models and set a new state-of-the-art for the Visual Commonsense Reasoning (VCR) benchmark (well, at the time of publication). The pre-training procedure relies on two main objectives:
- Masked Language Modeling with Visual Clues: similar to the original MLM task, but with the addition of representations for regions of the image being captioned.
- Masked Region of Interest Classification with Linguistic Clues: with a certain probability, regions of the image are masked and the objective is to predict the class of that region given the linguistic information.
🎉 Bonus: On the Relationship Between Self-Attention and Convolutional Layers | ICLR session
This unconventional paper presents a compelling analysis of what the attention mechanism and the convolution might have in common. Interestingly, they find more overlap than one might expect a priori: as their evidence suggests, attention layers often learn to attend “pixel-grid patterns” similarly to CNNs.
Using Computer Vision as a case study, along with detailed mathematical derivations they conclude that Transformer architectures might be a generalization of CNNs as they often learn equivalent patterns and might even present advantages thanks to the ability of learning local and global information simultaneously.

Honorable mentions: Deep Learning For Symbolic Mathematics; Logic and the 2-Simplicial Transformer (for Deep RL).
This year’s ICLR perfectly reflects how a vibrant active branch of Machine Learning matures: models, training techniques, datasets and applications get more refined and the understanding around them solidifies. Our Transformer-focused journey for this post ends here, but there’s still a lot more to explore for the conference. The team and I will be following relevant talks and workshops closely and reporting interesting insights live from our company twitter feed at @zetavector, so tune in if you don’t want to miss a thing!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号