YOLOv4: Optimal Speed and Accuracy of Object Detection
YOLOv4: Optimal Speed and Accuracy of Object Detection
2020-04-26 11:28:45
Paper: https://arxiv.org/abs/2004.10934
Code: https://github.com/AlexeyAB/darknet
Other collection for the Implementation: link
1. Background and Motivation:
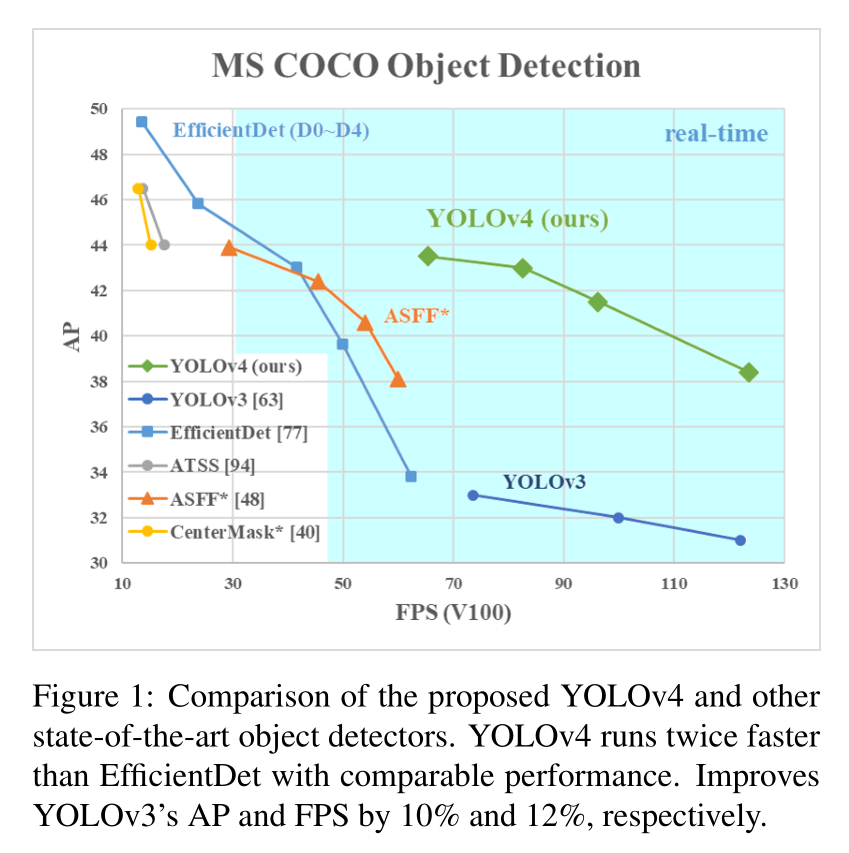
如图 1 所示,本文 YOLO-v4 在精度和速度上,取得了较好的平衡。
大部分基于 CNN 物体检测算法仅适用于推荐系统。例如,通过城市视频摄像头来搜索免费的停车位,这个过程是通过 slow accurate models 来实现的,而车辆碰撞警告是通过快速的不准确模型来实现的。因此一个实时的准确的物体检测模型,是非常重要的。本文就想构建一种物体检测模型来实现一个快速的算法,但是还要求能在单个普通的 GPU 上进行训练。为了上述目标,作者提出如下的贡献:
1). 作者开发了一种有效地、强大的物体检测模型。其可以利用 1080TI 或者 2080TI 显卡来训练一个超级快速和准确地物体检测器;
2). 作者验证了顶尖的 Bag-of-Freebies 和 Bag-of-Specials 方法的影响;
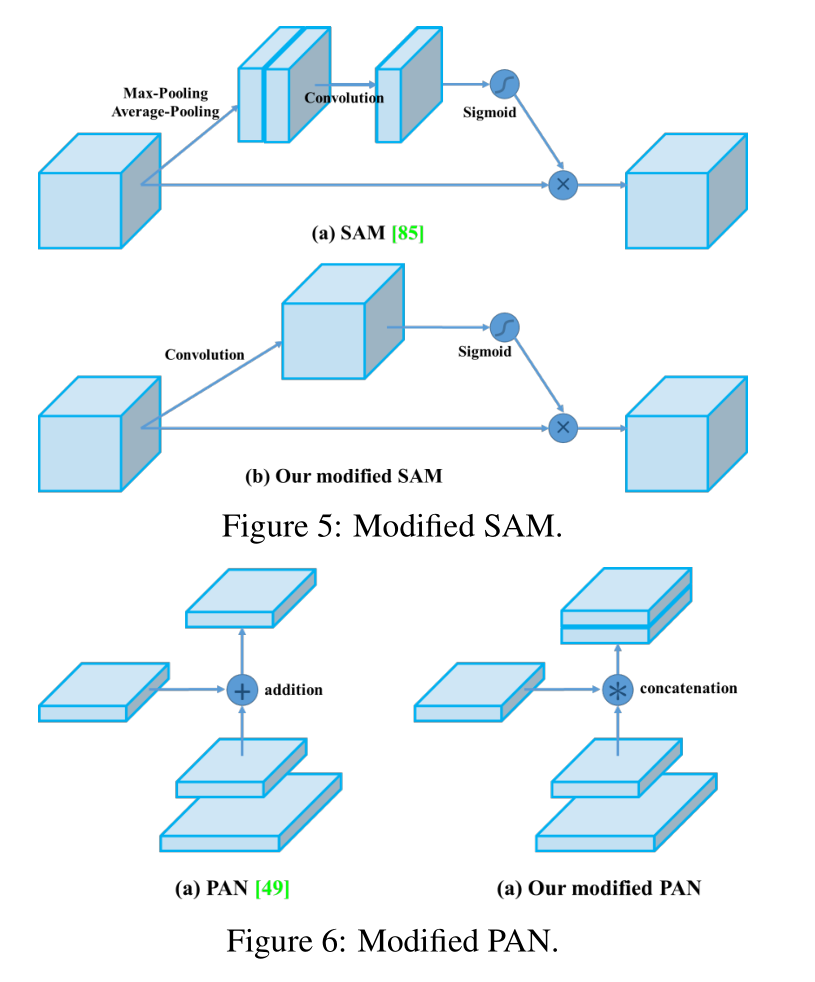
3). 修改了顶尖的算法,使得他们更加适合单张 GPU 训练,包括 CBN, PAN, SAM, 等。
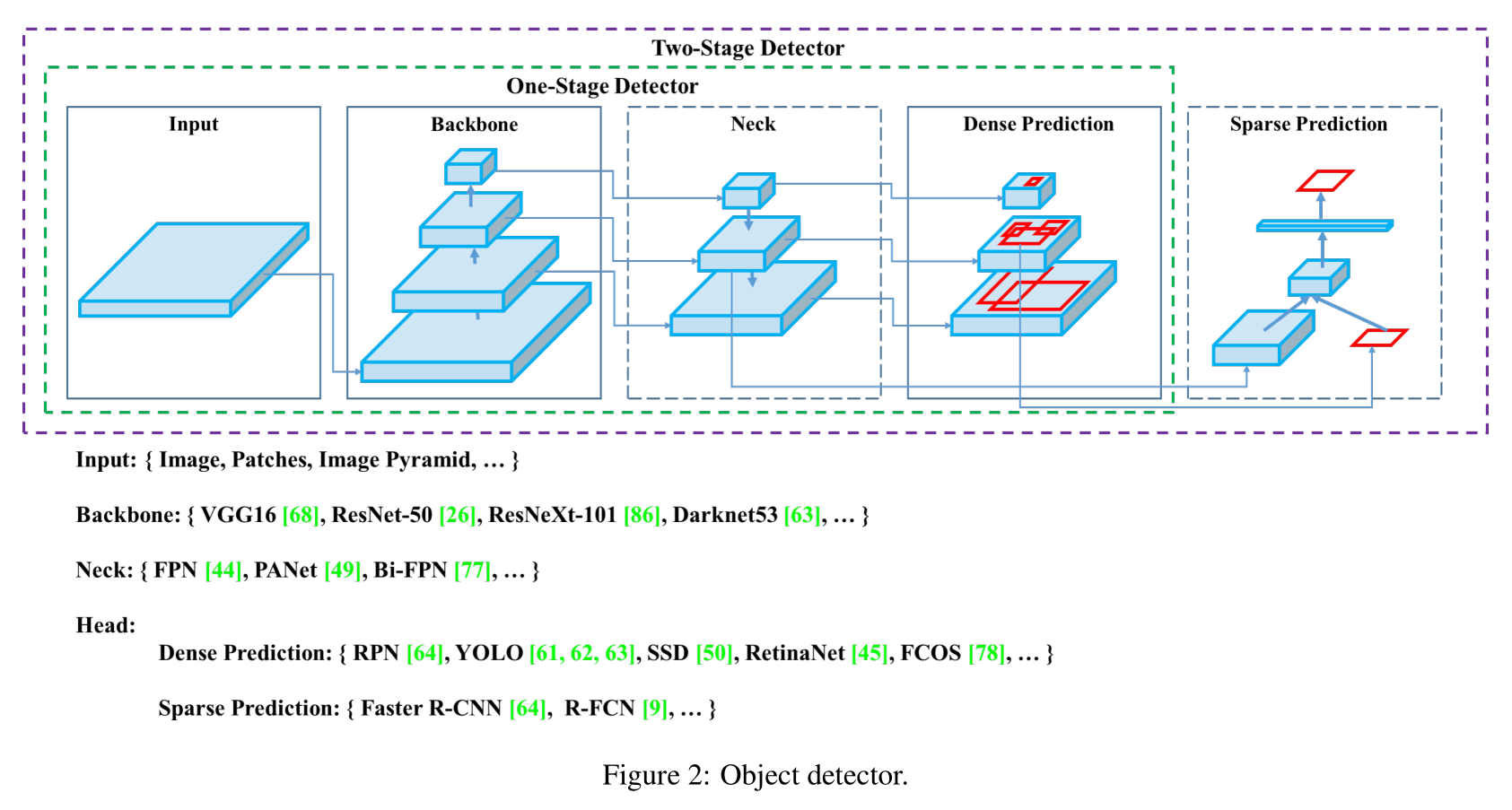
2. Related Work:
作者在 related work 中提到了众多的改进技巧,并且分为两个部分进行介绍:Bag of freebies 和 Bag of specials。
Bag of freebies:
data augmentation, semantic distribution bias, BBox regression;
Bag of specials:
enhanced receptive field, attention module, feature integration, multi-scale, good activation function, NMS;
3. The Proposed Method:
3.1. Selection of architecture:
作者给出了多个骨干网络,并且讲了选择的几个重要标准:

3.2. Selection of BoF and BoS:

3.3. Additional Improvements:

其中,比较有意思的是自我攻击训练:Self-Adversarial Training (STA) 这种方法提供了一种新的数据增广的技术,涉及到两个前向和后向阶段。
在第一个阶段,神经网络会修改原始的图像;这样神经网络就可以进行对抗攻击,改变原始图像来创造一些欺骗性的东西。
在第二个阶段,神经网络被训练按照常规的方式进行物体检测。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号