Learning to Predict Context-adaptive Convolution for Semantic Segmentation
Learning to Predict Context-adaptive Convolution for Semantic Segmentation
2020-04-20 17:41:35
Paper: https://arxiv.org/pdf/2004.08222.pdf
Code:
1. Background and Motivation:
本文提出一种新的方法来学习背景信息,以辅助语义分割。不同于常规的 channel attention的思路,本文利用动态卷积核的做法来搞。但是不同于最基本的卷积核方法(即 Dynamic Filter Network),因为这种方法有太多 FC layer,从而导致参数量过大。而是通过一种 matrix multiplication 的方法来得到 kernel parameters。这种 kernel 不但完全编码了输入特征图的全局内容,而且通过 depth-wise convolution 在 输入特征上,对每一个空间位置都产生了 context-aware spatially-varying feature weighting factors。此外,我们利用了一系列的空洞卷积,以及不同空洞率的方法,来有效地捕获多尺寸的信息。
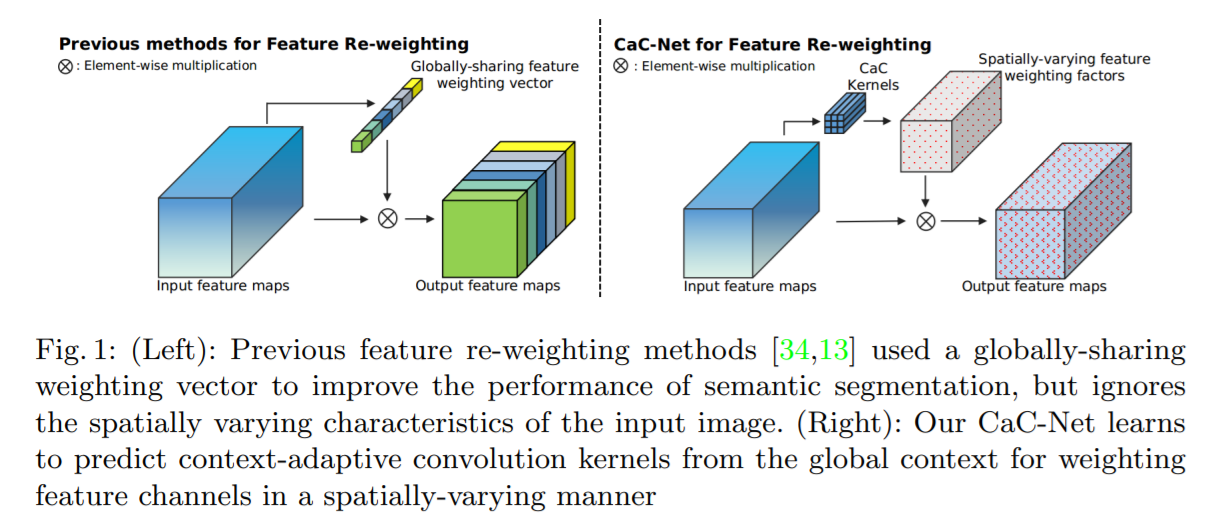
本文的主要创新点如下:
1). 为了更好的利用全局场景信息来正则化语义分割,作者提出通过预测 spatially-varying feature weighting factors 的方法来有效地加权不同的特征。从而改善语义分割的性能。
2). 从输入图像的全局场景中,预测 context-adaptive convolutional kernels 来有效地训练神经网络。
3). 在三个数据集上取得了不错的效果。
2. The Proposed Approach:
特征的再加权已经被证明是非常有效地捕获长距离语义信息的方法,该方法利用 channel-wise 的加权因子来进行加权处理。虽然在不同任务中,都取得了提升,但是这种方法的一个问题是:在 2D feature map 上,所有的空间位置上 weight vector 是共享的。作者认为,对于语义分割来说,一个全局共享的加权向量并非是最优的选择,因为不同的空间位置基本上是属于不同类别物体的。所以,需要学习一种全局背景内容,但是不同位置上要有差异性,从而捕获到其特有的性质,才能改善语义分割的效果。作者认为从全局的角度来预测的 kernels 有更好的场景结构,从而更好的加权不同位置的特征。
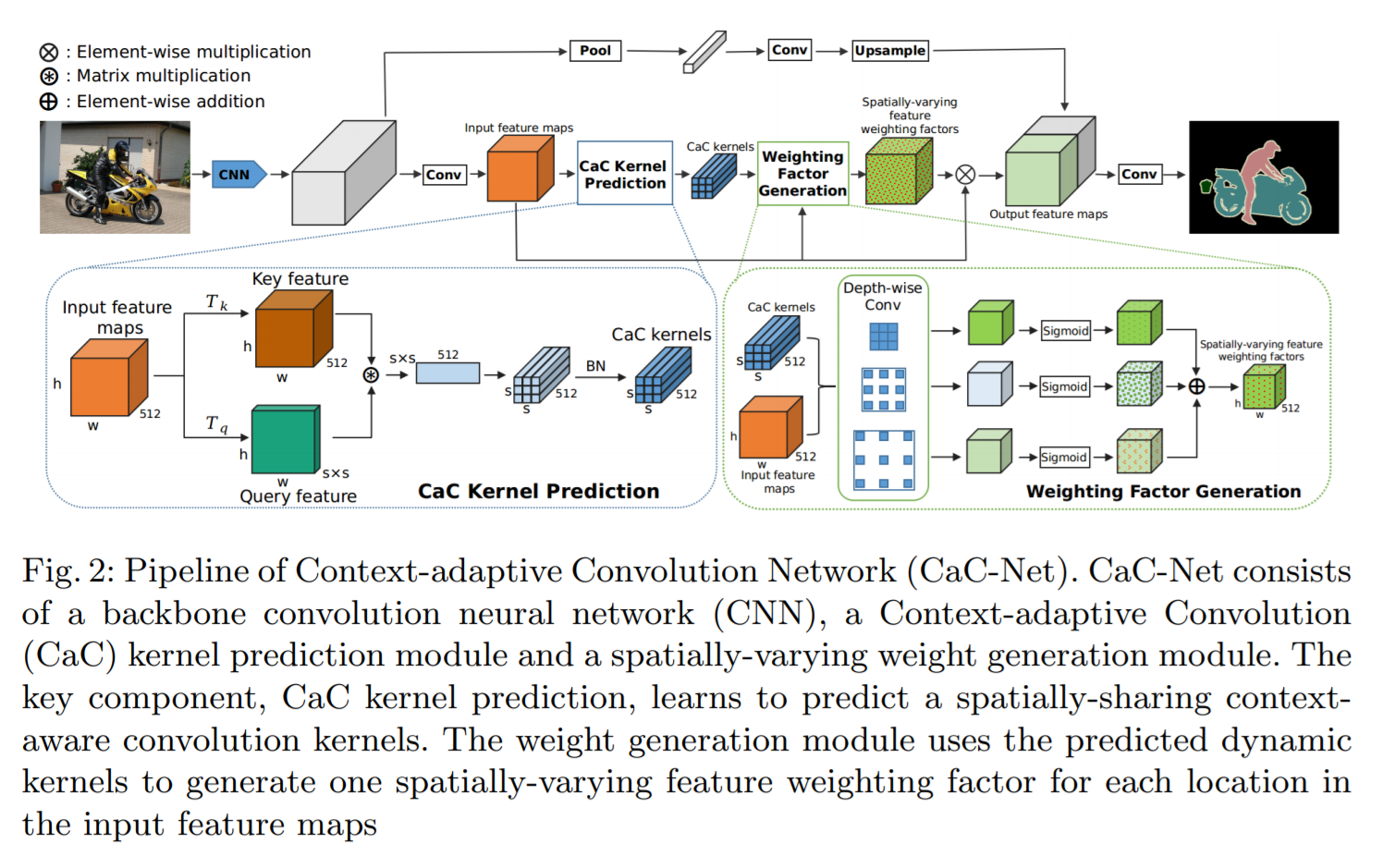
为了达到上述目标,作者提出一种 Context-adaptive Convolution network (CaC) 来利用全局内容来学习 channel-wisely re-weight 。一系列的 context-adaptive convolutional kernels 从 CaC 模块中学习出来。跟之前 Dynamic filter 的做法不同,作者这里通过简单地 matrix multiplication 来进行有效的参数估计。更重要的是,CaC kernels 是从 2D feature map 上得到的。
2.1. Context-adaptive Convolution Kernel Prediction:
作者利用 pre-trained ResNet 作为骨干网络来提取图像的特征。为了构建空间变化的特征加权,有两种 naive 的方法:
1). 一种方法是直接预测 c 个 s*s*c 的卷积核,s*s 是卷积核。然后利用这 c 个卷积核进行卷积操作。但是这种方法需要利用 fc 层来预测 kernel weights,参数量很大;
2). 另外一种方式是:从 global average pooled features 上,利用 fc layers 来捕获 global context。特征加权图可以用预测的 kernels 在输入 feature maps 上进行卷积得到。但是这种方法丢失了所有的空间信息,所以效果不是很大。
为了解决上述挑战,本文提出一种 Context-adaptive Convolutional module 来预测一系列的 s*s*c 的 CaC convolutional kernels。输入的特征图 X 首先被转换为 2D query feature map Q,和 key feature map K,这里用的是两个不同的转换函数 Tk and Tq。这两个函数是通过独立的 1*1 卷积操作得到的。总的来说,key feature K 捕获了 c 个不同性质,query feature Q 捕获了全局空间特征。
为了达到这个目标,query feature 和 key feature 被首先 reshape 以得到 Q' 和 K'。对于 Q(:, i)' 第 i 个 列的 query feature,可以用于捕获总的空间分布。这个结果可以用于衡量两个空间分布之间的差异性。如果我们重复该过程 c 次,我们可以得到一个 c-维的向量,可以刻画每一个特征通道的空间分布。由于我们有 $s^2$ 个 query vectors,我们可以捕获 $s^2$ 个特性:
![]()
然后,可以将上述 $\hat{D}$ reshape 为 s*s*c,然后用 BN 来得到预测的 D 作为 CaC kernels,并且可以用于和输入特征 X 进行卷积操作,以得到空间变化的特征加权因子。
2.2. Spatially-varying Weight Generation:
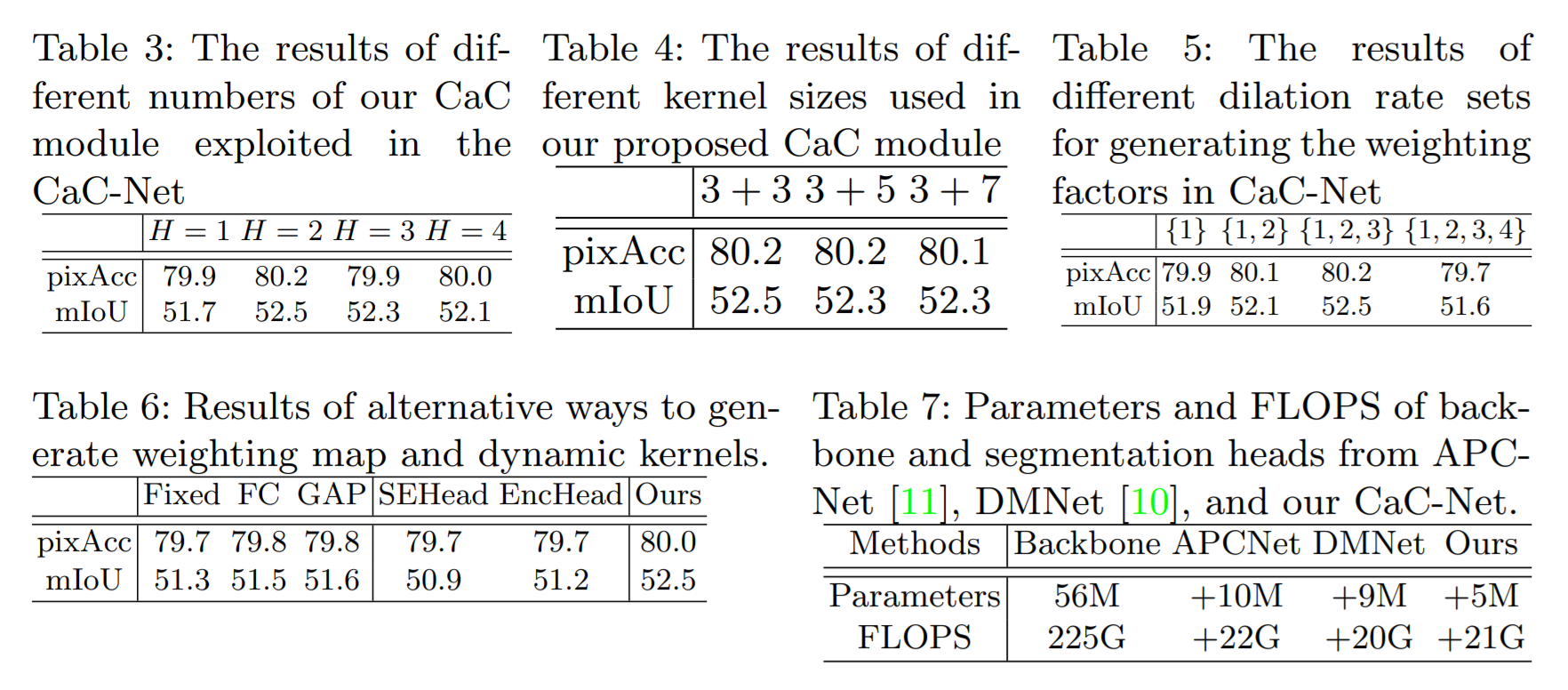
我们利用得到的 CaC kernel 来预测 spatial-varying weighting map 来对输入特征图进行加权处理。得到的 kernels D 可以用于进行 depth-wise convolution。所以,D 的每一个通道可以用于调节输入特征图的一个通道。为了新一步的改善预测 kernel D 的尺寸不变性,以及捕获多尺度内容。作者将原始预测的 kernels 记为 D1,并且预测了另外两个 CaC kernels,但是空洞率设置为 3 和 5,分别记为 D2 and D3。
如图 2 所示,对于预测的 CaC kernels 的每一个集合 D1, D2, D3,他们被用于在输入特征图 X 上分别执行 depth-wise convolution。每一个都会产生一个独立的权重图 W1, W2, W3,这些图可以融合得到 W:
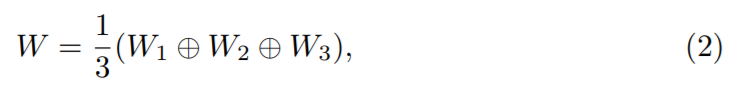
给定W之后,作者利用这个 W 对原始输入的特征进行加权处理:![]() 。
。
2.3. Global Pooling and Multi-head Ensembles:
作者引入 global pooling branch 来进行全局平均处理。
Multi-head 的意思是:并行的执行多次 CaC 模块,以得到多个输出特征图。
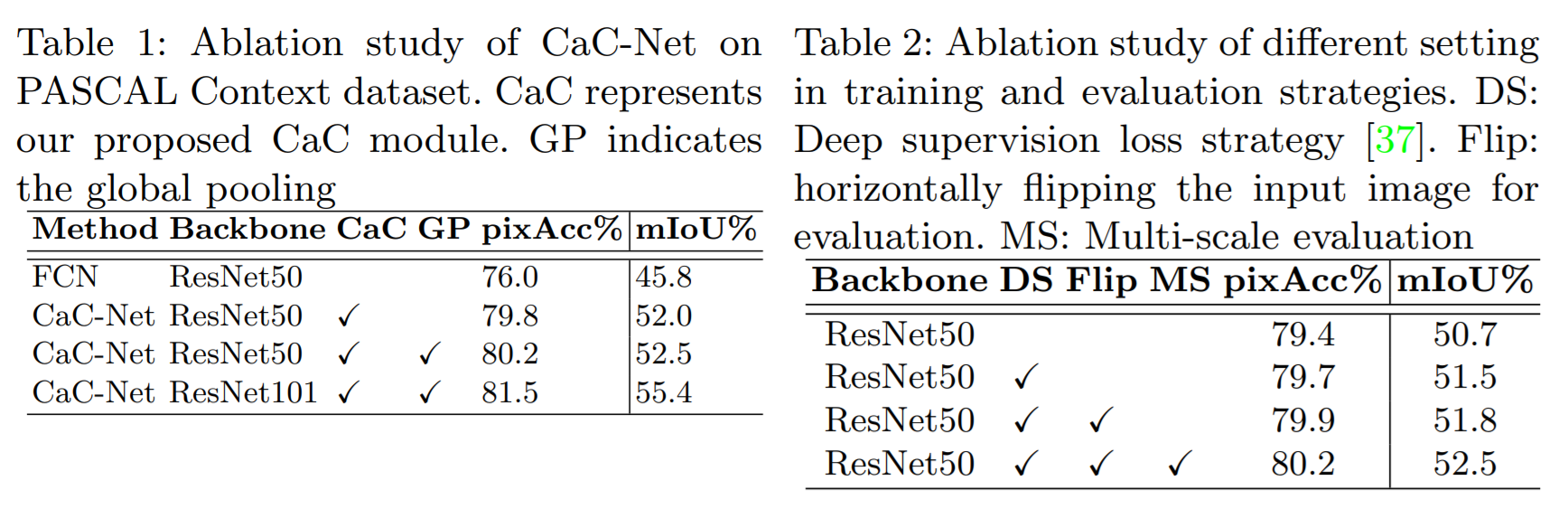
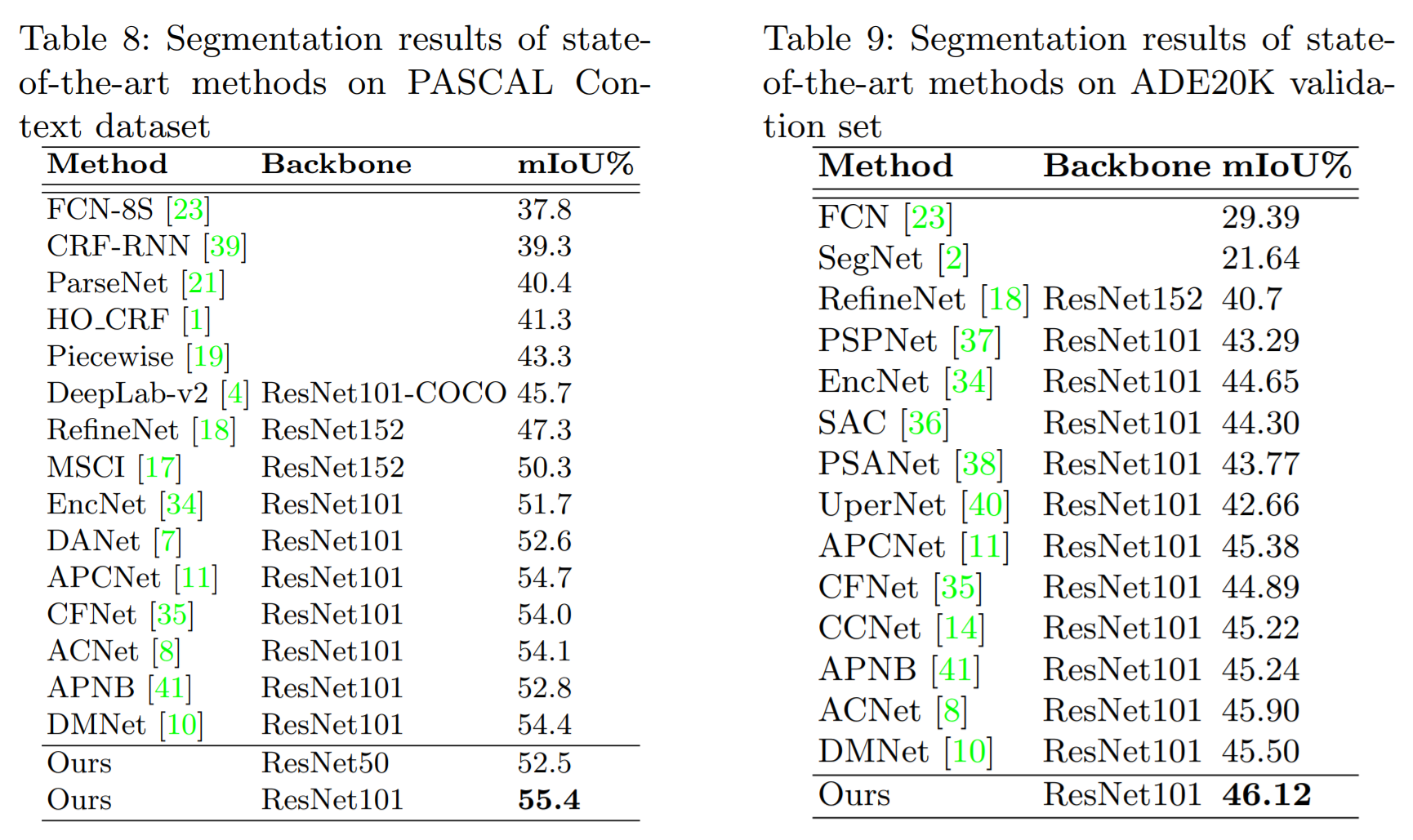
3. Experiments:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号