Know Your Surroundings: Exploiting Scene Information for Object Tracking
Know Your Surroundings: Exploiting Scene Information for Object Tracking
2020-03-25 17:52:24
Code: 尚无
1. Background and Motivation:
本文将背景的信息建模到单目标跟踪框架中,在 DiMP 跟踪器的基础上又得到了提升。其实这个想法很直接,就是想借助场景中的其他物体来协助定位真正的目标物体。因为现有的 Siamese network 虽然在常规的 video 上效果很好。但是,他们并么有考虑到场景中的其他物体,这导致相似性物体存在时,有可能使得模型漂移。
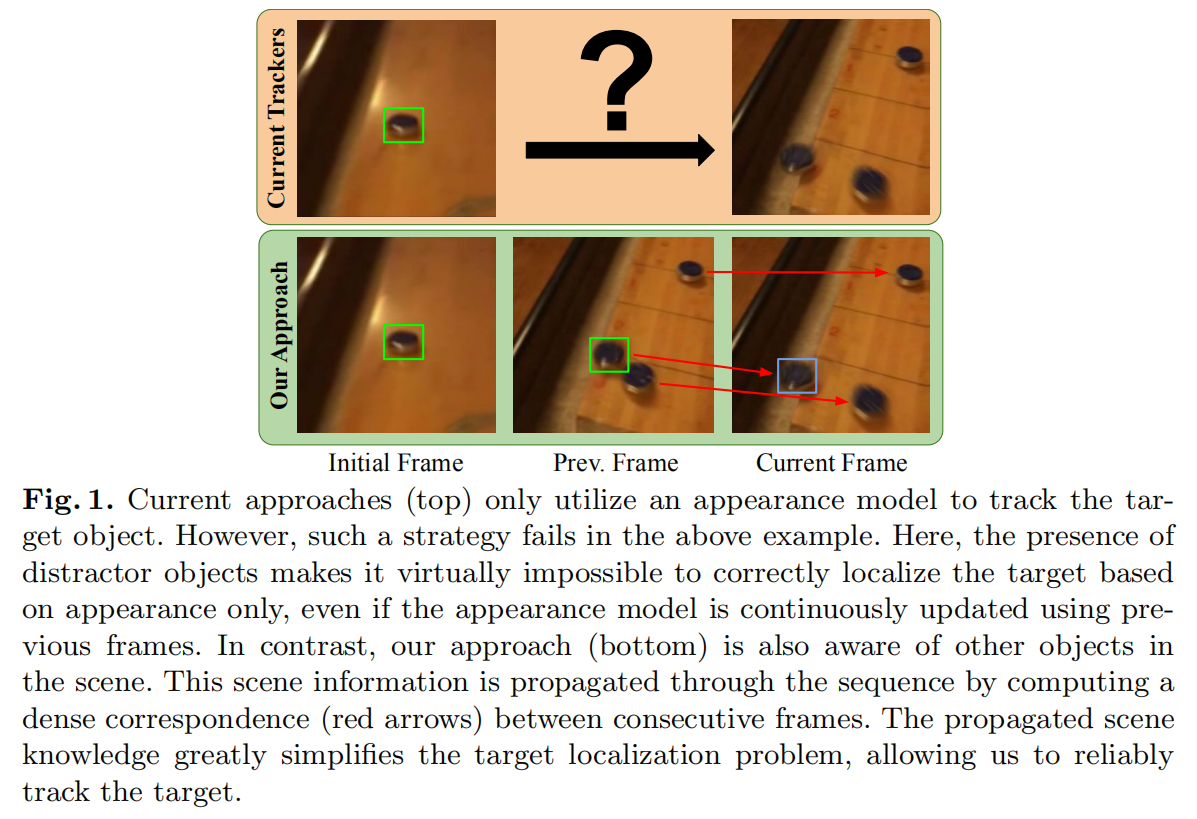
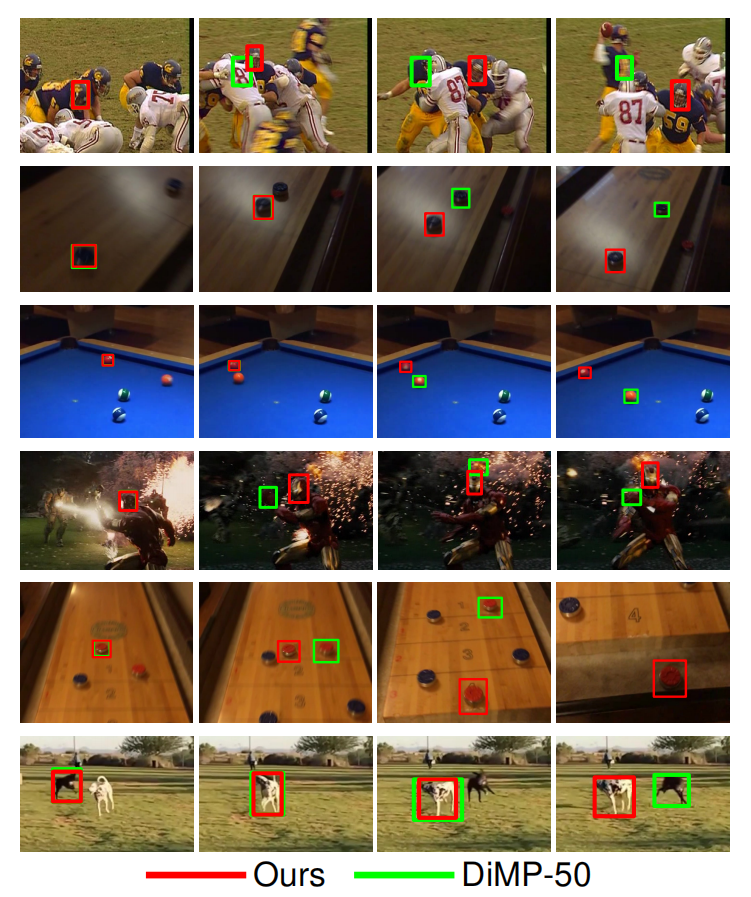
如上图所示,如果仅仅根据第一帧,根本无法判别到底哪一个黑色的物体才是真正的目标物体。但是如果有了临近的视频帧,通过对比背景物体,就可以知道了。
2. The Proposed Method:
本文提出一种新的跟踪框架可以探索场景信息来改善跟踪的结果。当前顶尖的跟踪器仅仅依赖于物体的外观模型来独立的处理每一帧,本文的方法可以从前面的视频帧上传递场景信息。这提供了丰富的环境因素,例如 相似物体的位置,可以明显的改善物体的定位。
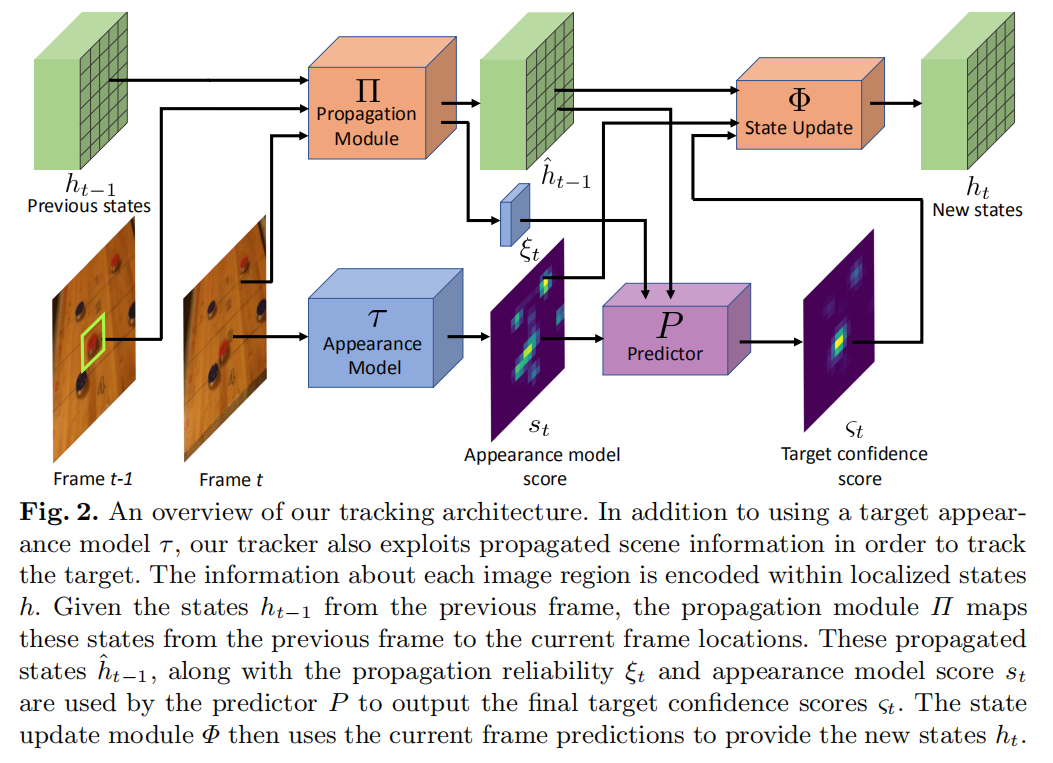
如图 2 所示,本文的跟踪器会tracking 场景中的所有物体,然后传递任何关于他们的信息来帮助目标物体的定位。而达到这个目标,作者是通过维持一个目标近邻的每一个区域的 state vector。该 state vector 可以编码是否一个特定的 patch 块对应目标物体,背景 或者是 相似物体。随着目标物体的移动,状态向量通过预测连续两帧之间的稠密对应关系来实现传递。传递的状态向量随后和目标外观模型进行融合,以预测最终的目标置信得分进行定位。最终,预测器的输出和目标模型用 ConvGRU 来更新状态向量。
2.1. Tracking with Scene Propagation:
跟踪期的预测包含两个信息:1). 当前帧的外观;2). 随着时间传递的场景信息。
外观模型的目标是区分背景中的目标物体。目标模型有能力从遮挡中恢复和提供长期的鲁棒性。然而,这种模型却忽略了场景中的其他物体。为了提取场景信息,作者对目标近邻的每一个区域都保持了一个状态向量。 具体的,对于每一个空间位置 r,作者保持了一个 S-维的状态向量 h。该状态向量包含了 cell 中的信息,可以用于单目标跟踪。其可以编码是否一个特定的 cell 对应前景,背景,或者是干扰物体。需要注意的是,作者没有显示的强调这种编码,但是让 h 是 generic representation,这种编码是通过最小化跟踪损失来端到端训练出来的。
在第一帧的时候进行状态向量的初始化,利用的是一个小的网络,其将第一帧中目标标注 B0 作为输入。该网络输出一个 single-channel label map 来指定目标的位置。这是通过两个卷积层来实现的,以得到初始的状态向量 h0。状态向量包含定位信息,特别是们对应的图像区域。所以,随着物体在序列中移动,也要随着进行状态的更新和传递。给定一个新的视频帧 t,作者将状态 $h_{t-1}$ 从前一帧到当前帧进行传递。这是通过一个状态转移模型实现的:
此处,$x_t, x_{t-1}$ 是当前帧和前一帧的深度特征表达。输出 $\hat{h_{t-1}}$ 代表了空间传递状态,弥补了物体和背景的运动。传递可靠性图 表明了状态传递的可靠性。即,一个较高的值表明:the state at r has been confidently propagated。在定位的时候,可靠性图可以用于决定是否可以相信传递的状态向量。
为了预测目标物体的位置,作者利用了外观模型和传递向量。后者捕获了场景中所有物体的有价值的信息,补充了 target-centric information。作者将状态向量,和 可靠性得分 以及 外观模型的预测输入到 预测模块 P 中。该预测器组合了这些信息来提供融合后的目标置信度得分:

通过选择最高置信度的位置来定位第 t 帧的目标位置。最终,作者利用融合后的置信度得分,以及外观模型输出来更新状态向量:

循环状态更新模块可以利用当前帧 score map 的信息,即:重新设置不准确的状态向量,或者建立一个新进入场景的相似性物体。这些更新后的状态向量 ht 然后被用于跟踪下一帧的物体。跟踪的整个过程可以参考算法 1。


3. Experiment:

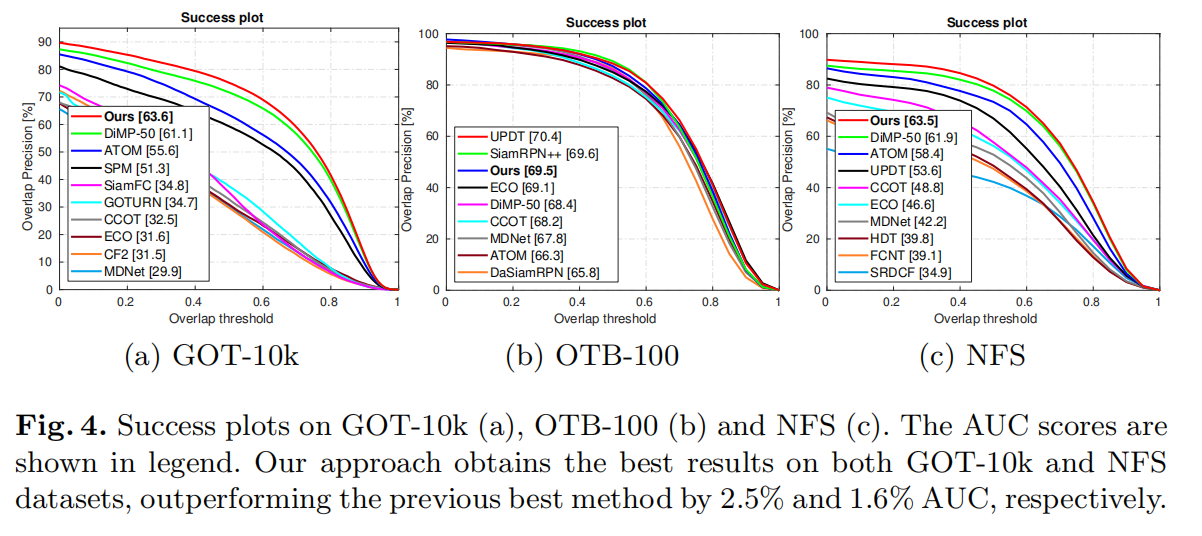
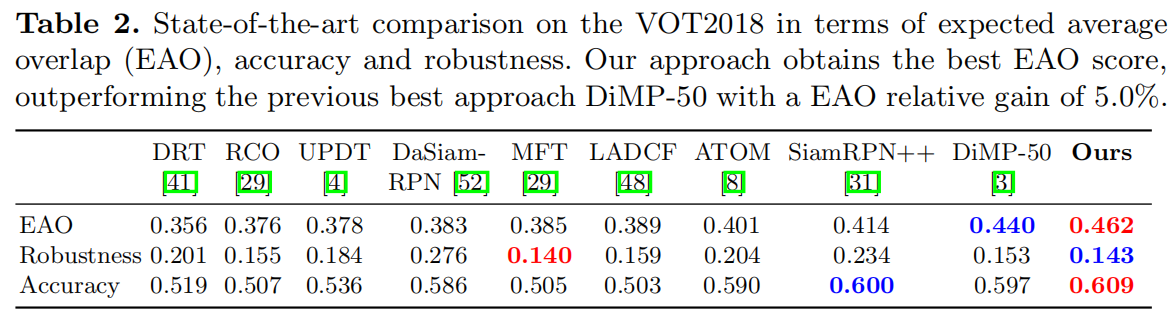
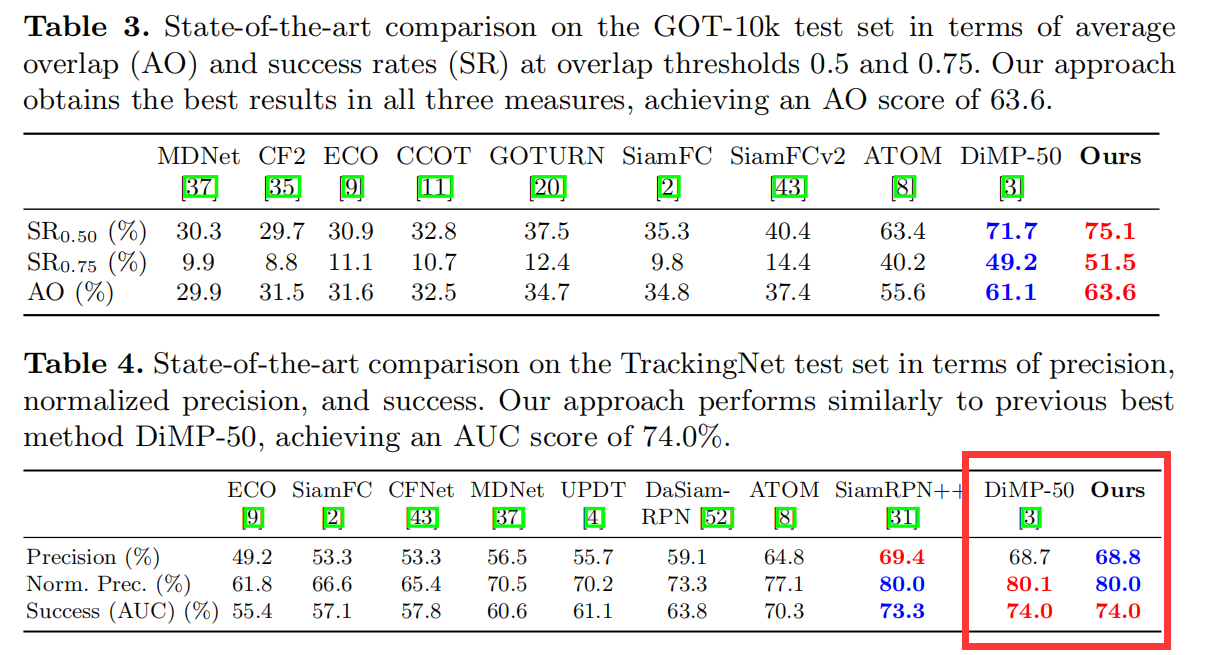
速度:RTX-2080 上达到 20 FPS。
Stay Hungry,Stay Foolish ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号