
Video Object Grounding using Semantic Roles in Language Description
Video Object Grounding using Semantic Roles in Language Description
2020-03-25 17:44:59
Paper:https://arxiv.org/pdf/2003.10606.pdf
Code: https://github.com/TheShadow29/vognet-pytorch
1. Background and Motivation:

2. The Proposed Method:
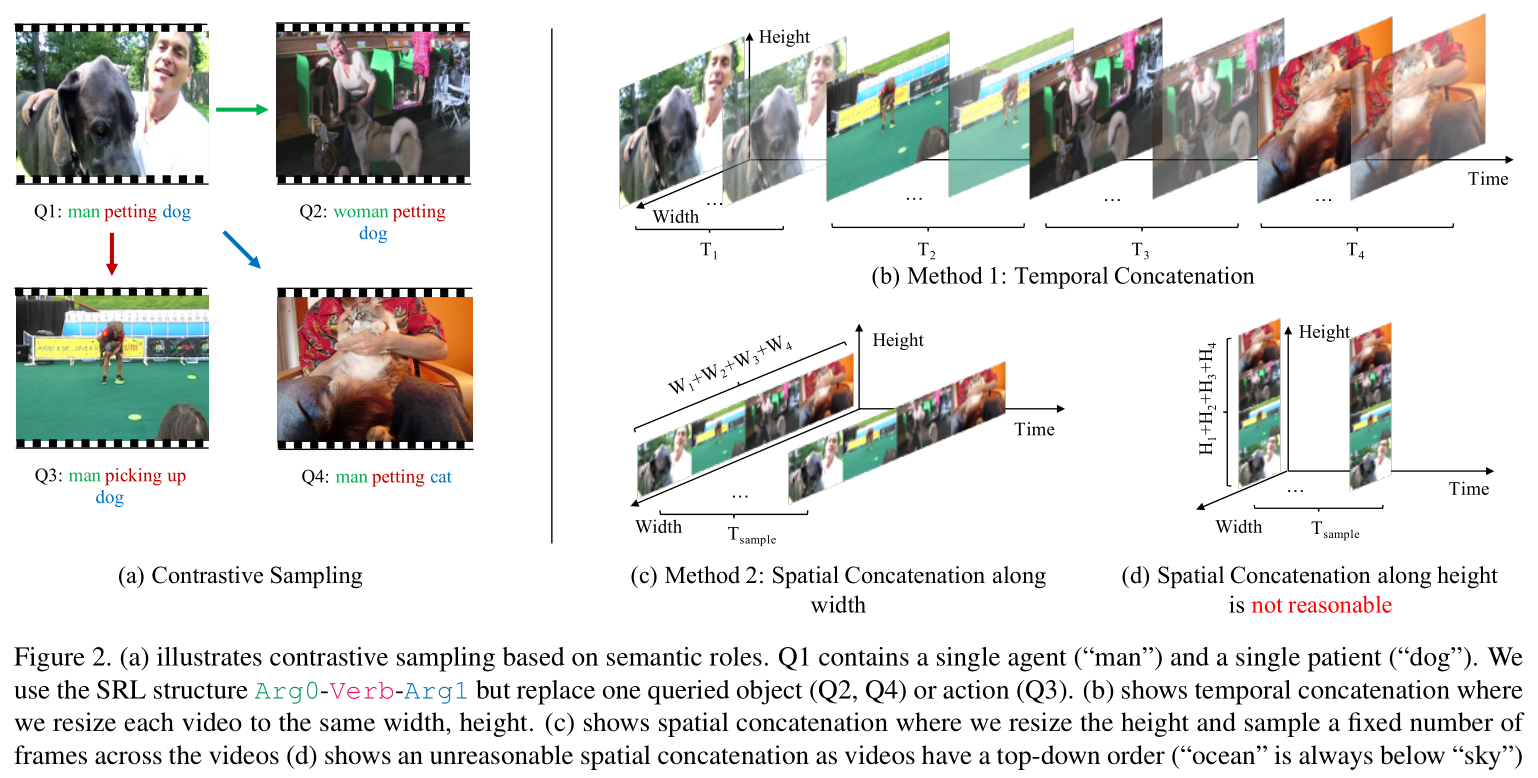
2.1. Contrastive Sampling
大部分大型的视频数据集,都是来自于互联网,例如 YouTube,其实这种视频在同一个 video 上很少包含同一个目标的多个实例。在这种视频上利用物体检测方法很难解决的很好。为解决这个问题,作者提出一种 two-step contrastive sampling method。首先,对每一个语言描述赋予一个语义角色标签,然后通过替换每一个角色来采样其他的描述,如图 1 和 2 (a) 所示。
在第二步中,作者将样本进行组合。一种简单地组合方法是将每一个 video 单独的进行处理。但是,这种思路无法学习物体之间的关系。另外,作者通过将这些样本在时序(TEMP)和空间维度上(SPAT)进行拼接,以得到新的数据。对于 TEMP,作者将采样的视频进行 resize,以得到相同的宽和高。
2.2. Framework:

Object Transformer:是一个 transformer 模型,即:在 P*F proposals 上执行 self-attention。
Multi-modal Transformer:作者将 self-attended features 和 language features 进行组合,以得到多模态特征 m。作者采用 self-attention with relative position encoding 得到 self-attended multi-modal feature。然而,由于硬件的限制,在所有的 proposals 上都进行这些操作是非常耗时的。所以,作者每一帧用一次 self-attention。所以,得到的特征然后输入到 2-layered MLP 以得到每一个 proposal-role pair 的预测。
2.3. Relative Position Encoding:
相对位置的编码利用了两个 proposal 之间的相对距离,作为额外的信息进行 attention 操作。作者将 proposal $p_{a, b}$ 的位置进行归一化处理,得到 [xtl, ytl, xbr, ybr, j] with $pos_{a, b} = [xtl/W, ytl/H, xbr/W, ybr/H, j/F]$。作者将 Proposal A 和 B 之间的相对位置编码为:![]()
假设 Transformer 包含 nl layers 和 nh heads,

作者将其改为了:

需要注意的是:![]() 和
和 ![]() 拥有相同的维度,并且可以进行简单的矩阵相加。
拥有相同的维度,并且可以进行简单的矩阵相加。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号