Generating Adversarial Examples with Adversarial Networks
Generating Adversarial Examples with Adversarial Networks
2020-03-08 22:40:38
Paper: IJCAI-2018
Code: https://github.com/mathcbc/advGAN_pytorch
1. Background and Motivation:
为了更加高效的生成对抗样本,本文提出:1). 一个前向网络来生成干扰,从而得到多样性的对抗样本; 2). 一个判别器网络来确保得到的样本是真实的。本文在 GAN 的基础上,在 semi-whitebox 和 black-box 的设定下产生对抗样本。由于 conditional GAN 可以产生高质量的图像,作者将这种对抗思想接入到对抗样本生成流程中,并且起名为 AdvGAN。第一个对抗攻击的网络 FGSM 在进行攻击的时候,需要时刻访问被攻击模型的结构和参数。然而,通过AdvGAN,一般前向网络被训练出来,就可以立刻产生干扰图像,而不需要访问模型本身,作者将这种攻击设定称为 semi-whitebox。
2. The Proposed Method:
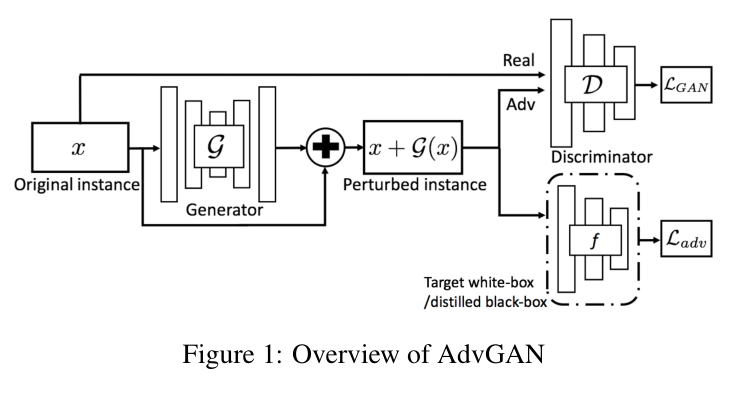
2.1. AdvGAN Framework:
如图 1 所示,本文模型主要包含三个部分:a generator G, a discriminator D, and the target neural network f. 此处,产生器 G 将原始输入数据 x 当做是输入,并且产生一个干扰图像 G(x)。然后将 x + G(x) 传送到判别器 D 中,用于判断给定的数据是来自产生的数据还是真实数据。G 的目标是使得产生的数据 和 真实的数据不可区分。为了愚弄学习的模型,作者首先进行 white-box attack,假设目标模型是 f。f 将 x + G(x) 作为输入,然后输出 loss $L_{adv}$,表示预测和目标类别 t 之间的距离,或者说 预测和真实类别距离的相反数。具体来说,对抗损失可以表示为:
![]()
用于愚弄目标模型 f 的损失可以记为:
![]()
其中,t 是 target class, $l_f$ 表示损失函数,本文用的是交叉熵损失,来训练原始模型 f。这个损失的目标是鼓励模型将 对抗生成的样本 误分类为 class t。为了约束 perturbation,作者在 L2 norm 的基础上添加了一个 hinge loss:
![]()
其中,c 代表一个用户指定的 bound,这也可以稳定 GAN 的训练。最终,模型总的训练目标是:
![]()
2.2. Black-box Attacks with Adversarial Networks:
Static Distillation: 为了进行 black-box attack,作者假设 adversaries 没有训练数据的先验知识或者模型本身。在本文实验中,作者随机的选择 data that is disjoint from the training data of the black-box model to distill it,因为作者假设:对抗样本没有训练数据或者模型的相关先验知识。为了达到黑盒攻击的目标,作者首先基于 black-box model b 的输出来构建一个 distilled network f。一旦得到 distilled network f, 就可以进行类似 white-box setting 下的攻击策略。此处,作者最小化如下的网络蒸馏目标:
![]()
其中,f(x) 和 b(x) 分别表示 distilled model 和 black-box model 的输出,H 表示常用的交叉熵。通过在所有的训练数据上,优化目标,我们可以得到一个模型 f,该模型可以和 black-box model b 非常类似(原文说的是 which behaves very close to the black-box model b)。然后就可以对 distilled network 进行攻击。需要注意的是,跟 discriminator D 训练不同的是,这里不仅仅利用 original class 得到的 real data 来使得产生的 instance 和 original class 尽可能的接近,此处,我们从所有类别的数据来训练蒸馏模型。

3. Experiments:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号