NeurIPS 2019: Computer Vision Recap
NeurIPS 2019: Computer Vision Recap
2020-02-07 18:47:12
Source:https://medium.com/@dobko_m/neurips-2019-computer-vision-recap-ddd26b13337c
Recap of some papers from 33rd Conference on Neural Information Processing Systems
Conference website . Papers
This is an overview (notes) of NeurIPS 2019 that was held during 9–14 of December in Vancouver. Over 13,000 participants. 2 days of workshops, a day of tutorials and 3 days of main conference.
In this post I shortly describe some of the papers which were presented and caught my attention. All the works mentioned in this post are in Computer Vision domain, which is my field of research.
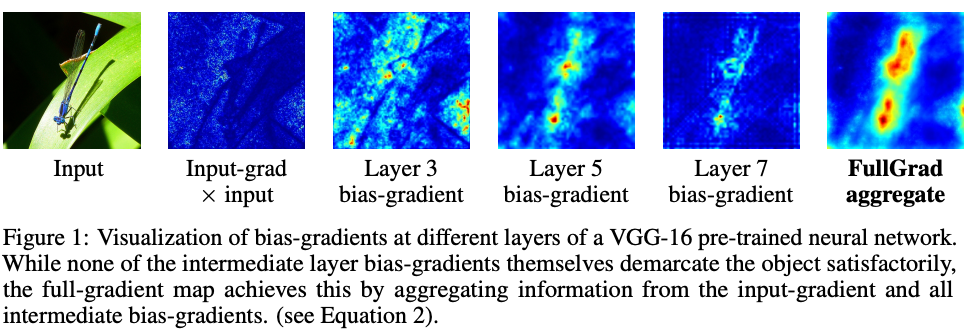
Full-Gradient Representation for Neural Network Visualization
Suraj Srinivas, François Fleuret
Exploring how the importance of an input part is captured by saliency maps. Authors show that any neural network’s output can be decomposed into an input-gradient term and per-neuron gradient-terms. They prove that aggregating these gradient maps in convolutional networks improves the saliency maps. Paper proposes FullGrad saliency which incorporates both input-gradients and feature-level bias-gradients, thus, satisfies two notions of importance: local (model sensitivity to input) and global (completeness of saliency map).
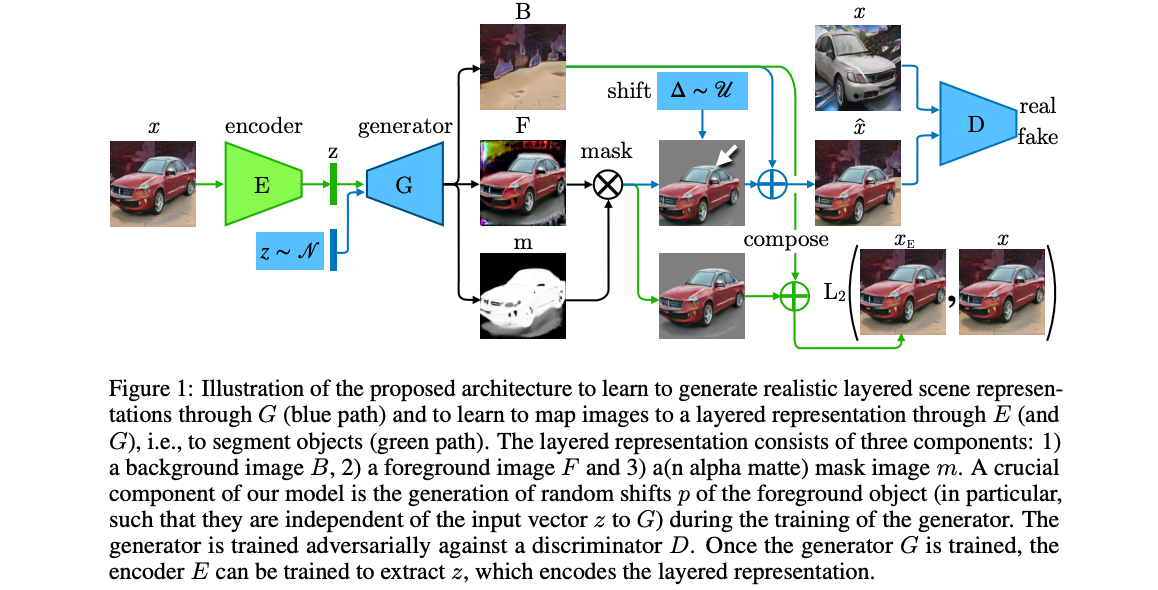
Emergence of Object Segmentation in Perturbed Generative Models
Adam Bielski, Paolo Favaro
A framework is introduced which learns object segmentation from a collection of images without any manual annotation. The main idea is build on the observation that the location of object segments can be perturbed locally relative to a given background without affecting the realism of a scene. A generative model is trained that produces a layered image representation: background, mask, and foreground. Authors use small random shift to expose invalid segmentation. They train StyleGAN with two generators, separate for a background and a foreground with a mask. It is trained so that the composite images with a shifted foreground render valid scenes. There are also two loss terms on generated masks to encourage binarization and assert minimum mask coverage, both added to WGAN-GP generator loss. They also train encoders with a fixed generator to get segmentation for real images. The approach was tested on 4 categories of LSUN object dataset: car, horse, chair, bird. Paper
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, Zhifeng Chen
To address the need for efficient and task-independent model parallelism, GPipe is introduced, a scalable model-parallelism library for training giant neural networks that can be expressed as a sequence of layers. The proposed novel batch-splitting pipeline-parallelism algorithm uses synchronous gradient updates, allowing model parallelism with high hardware utilization and training stability. The main contributions include model scalability (almost linear speedup in throughput and size, support of very deep transformer with up to over 1k layers and 90B parameters), flexibility (scaling of any network), simple programming interface. GPipes provides a way to increase quality even for datasets with smaller sizes using transfer learning or multitask learning. The experiments showed that deeper networks transfer better while wider models memorize better.
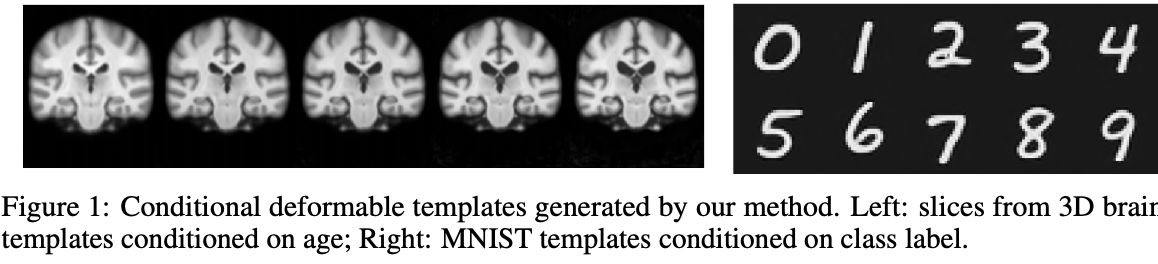
Learning Conditional Deformable Templates with Convolutional Networks
Adrian Dalca, Marianne Rakic, John Guttag, Mert Sabuncu
Learning framework to estimate deformable templates (atlases) together with alignment network. Enables conditional template generating functions based on desired attributes. This method jointly learns registration network and atlas. We develop a learning framework for building deformable templates, which play a fundamental role in many image analysis and computational anatomy tasks. In conventional methods for template creation and image alignment, templates are constructed using an iterative process of template estimation and alignment, which is often computationally very expensive. The introduced approach consists of a probabilistic model and efficient learning strategy that yields either universal or conditional templates, jointly with a neural network that provides efficient alignment of images to these templates. This is particularly useful for clinical applications. Paper. Code.
Learning to Predict Layout-to-image Conditional Convolutions for Semantic Image Synthesis
The proposed method predicts convolutional kernels conditioned on the semantic label map and generates the intermediate feature maps from the noise maps to eventually generate the images. Authors argue that for generator: convolutional kernels should be aware of the distinct semantic labels at different locations, while for discriminator, it’s important to enhance fine details and semantic alignments between the generated images and the input semantic layouts. Thus, image generator is used for predicting conditional convolutions (efficiently predicts depthwise separable convolutions, only predicts weights for depthwise convolutions, is a global-context-aware weight prediction network). The introduced Feature Pyramid Semantics-Embeddings Discriminator is used for fine details such as textures and edges, while also for semantic alignment with layout map. Paper. Code.

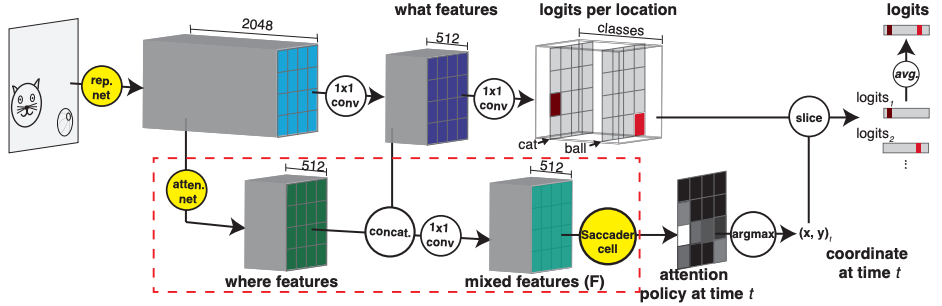
Saccader: Improving Accuracy of Hard Attention Models for Vision
Gamaleldin F. Elsayed, Simon Kornblith, Quoc V. Le
In this work the improvements of hard attention models (they select salient regions in an image and use only them for prediction) are presented. The introduced model — Saccader has a pretraining step that requires only class labels and provides initial attention locations for policy gradient optimization. Saccader architecture: 1. Representation network (BagNet) 2. Attention network 3. Saccader cell (no RNN, predicts the visual attention location at each time). The best Saccader models narrow the gap to common ImageNet baselines, achieving 75% top-1 and 91% top-5 while attending to less than one-third of the image. Paper. Code.
Unsupervised Object Segmentation by Redrawing
Mickaël Chen, Thierry Artières, Ludovic Denoyer
ReDO (ReDrawing Objects) is an unsupervised data-driven object segmentation method. Authors assume that natural image generation is a composite process in which each object is generated independently. They put object segmentation task as the discovery of regions that can be redrawn without seeing the rest of the image. As mentioned in the paper, the approach is based on an adversarial architecture where the generator is guided by an input sample: given an image, it extracts the object mask, then redraws a new object at the same location. The generator is controlled by a discriminator that ensures that the distribution of generated images is aligned to the original one. The learned function is added that tries to reconstruct the noise vectors from the general image, then the output is tied to the input by only regenerating one region at a time, keeping the rest of the image unchanged. Paper.

Learning the full model for object segmentation. Learned neural networks are represented in bold colored lines
Approximate Feature Collisions in Neural Nets
Ke Li, Tianhao Zhang, Jitendra Malik
Feature collisions — two dissimilar examples sharing the same feature activation and therefore the same classification decision. In this paper the method of finding feature collisions is presented. In this paper, authors show that neural nets could be surprisingly insensitive to adversarially chosen changes of large magnitude. From this experiment they observe that this phenomenon can arise from the intrinsic properties of the ReLU activation function, resulting in two very different examples sharing the same feature activation and therefore the same classification decision. Possible applications include representative data collection, design of regularizers, identification of vulnerable training examples. Paper.

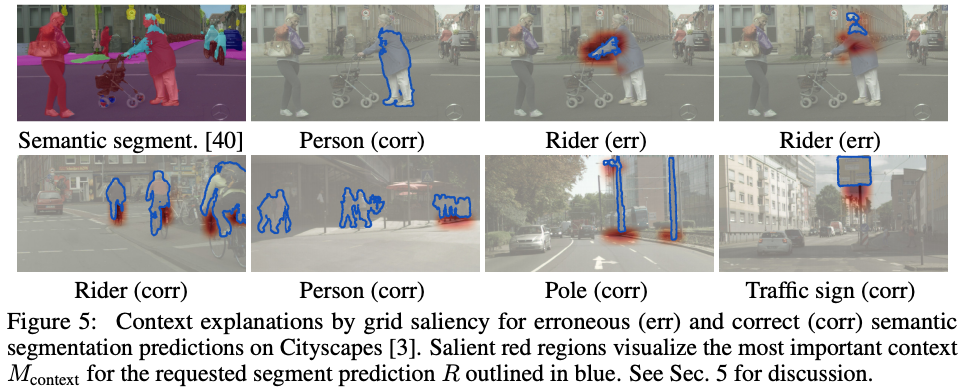
Grid Saliency for Context Explanations of Semantic Segmentation
Lukas Hoyer, Mauricio Munoz, Prateek Katiyar, Anna Khoreva, Volker Fischer
The results of this paper show that grid saliency can be successfully used to provide easily interpretable context explanations and, moreover, can be employed for detecting and localizing contextual biases present in the data. The main objective is to develop a saliency method that provides visual explanations of network predictions by extending the existing approaches to generate grid saliencies. This provides spatially coherent visual explanations for (pixel-level) dense prediction networks and produces context explanations for semantic segmentation networks. Paper.
Fooling Neural Networks Interpretations via Adversarial Model Manipulation
Juyeon Heo , Sunghwan Joo , Taesup Moon
Assumption: saliency map-based interpreters can be easily fooled without significant drops in accuracy. This paper shows that the state-of-the-art saliency map based interpreters, e.g., LRP, Grad-CAM, and SimpleGrad, can be easily fooled with adversarial model manipulation. Two types of fooling are proposed, Passive and Active, along with a quantitative metric — Fooling Success Rate (FSR). It gives intuition on why its adversarial model manipulation works, and what are some limitations. Paper.

A Benchmark for Interpretability Methods in Deep Neural Networks
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
An incorrect estimate of what is important to a model prediction can lead to decisions that adversely impact sensitive domains (healthcare, self-driving, etc.). Authors compare feature importance estimators and explore whether ensembling them improves accuracy. In order to compare methods, they remove a fraction of all pixels from each image that are estimated to contribute the most to the model prediction and retrain the model without them. The hypothesis is that best interpretability method should provide pixels whose removal weakens model performance the most. This approach of evaluation is called ROAR: RemOve And Retrain. The tested methods in this paper include base estimators (gradient heatmap, Integrated Gradients, Guided Backprop), ensembles of base estimators (SmoothGrad Integrated Gradients, VarGrad Integrated Gradients, etc.), and control variants (random, sobel edge filter).The most effective appear to be SmoothGrad-Squared and VarGrad.
HYPE -Human eYe Perceptual Evaluation: A benchmark for generative models
Sharon Zhou, Mitchell L. Gordon et al.
HYPE is a standardized, validated evaluation for generative models, which tests them for how realistic their images look to the human eye. As mentioned by the authors, it is consistent, inspired by psychophysics methods in perceptual psychology, reliable across different sets of randomly sampled outputs from a model, results in separable model performances, and efficient in cost and time.
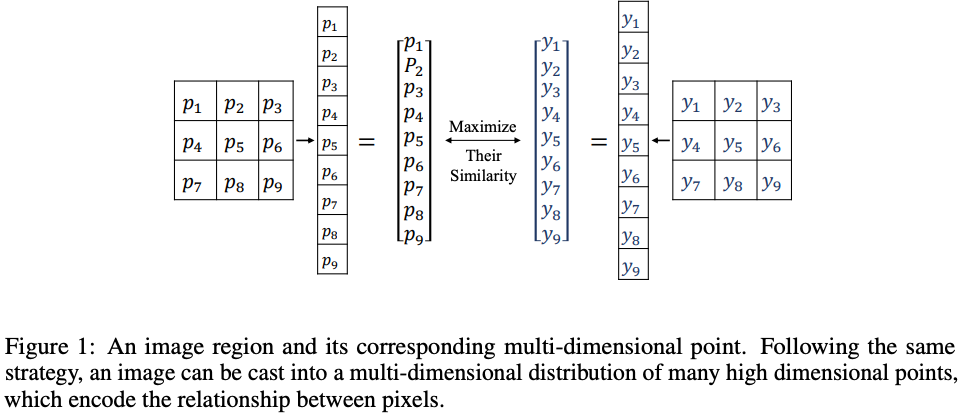
Region Mutual Information Loss for Semantic Segmentation
Shuai Zhao, Yang Wang , Zheng Yang, Deng Cai
While semantic segmentation is commonly solved as a pixel-wise classification, the pixel-wise loss ignores the dependencies between pixels in an image. Authors use one pixel and its neighbor pixels to represent this pixel and transform an image into a multi-dimensional distribution. The prediction and target is thus more consistent through maximizing the mutual information between their distributions. The idea of RMI is intuitive, and it is also easy to use since it only requires a few additional memory during the training stage, even more, no changes to the base segmentation model are needed. RMI can achieve substantial and consistent improvements in performance, too. Approach is tested on PASCAL VOC 2012. Paper. Code.
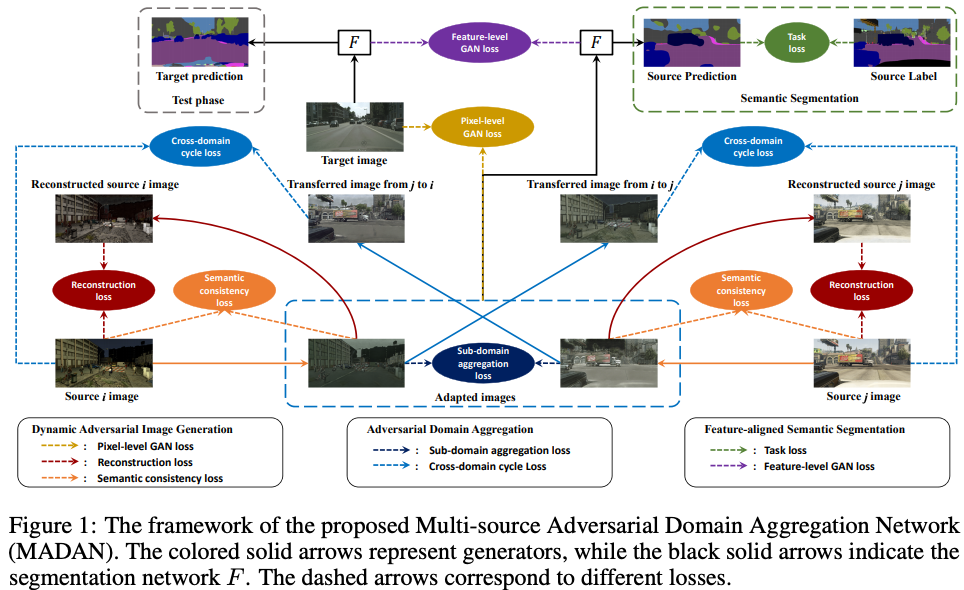
Multi-source Domain Adaptation for Semantic Segmentation
Sicheng Zhao, Bo Li, Xiangyu Yue, Yang Gu, Pengfei Xu, Runbo Hu, Hua Chai, Kurt Keutzer
In this work domain adaptation for semantic segmentation is performed from multiple sources and presented as a novel framework termed MADAN. As stated by the authors, besides feature-level alignment, pixel-level alignment is further considered by generating an adapted domain for each source cycle-consistently with a novel dynamic semantic consistency loss. To improve alignment of different adapted domains two discriminators are proposed: cross-domain cycle discriminator and sub-domain aggregation discriminator. The model is tested on synthetic datasets — GTA and SYNTHIA , as well as real — Cityscapes and BDDS. Paper.
Thank you for reading!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号