Recent Advancements in NLP
Recent Advancements in NLP
2019-12-27 14:28:12
Source:
1. https://medium.com/swlh/recent-advancements-in-nlp-1-2-192ac7eefe3c
2. https://towardsdatascience.com/recent-advancements-in-nlp-2-2-df2ee75e189
2018 has been widely touted as the “Imagenet moment” in the field of NLP due to the release of pre-trained models and open source algorithms by big players like Google, Open AI, Facebook etc. I have tried to summarize some of the important advancements in the field of NLP in this blog.
I have spent a good fifteen years in the field of Data Science and AI and have worked a fair bit on NLP in this period, but the pace with which things have been moving in the last 2–5 years is unprecedented. If you have not caught up with all the exciting work, you may be lagging behind significantly on what’s possible these days.
NLP is one of my favorite areas given its wide applications. Some of the popular applications by which we interact every day are — search engines, machine translation, chatbots, home assistants etc.
This is my first blog in a series of two blogs to capture the exciting work in the field of NLP
NLP is Hard
In addition to being tremendously useful, NLP is also pretty challenging, consider the following few examples:
“Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo” is a grammatically correct sentence
“John saw the man on the mountain with a telescope” Who is on the mountain? John, the man, or both? Who has the telescope? John, the man, or the mountain?
These challenges in interpreting language can cause Siri to do something like this

I have summarized some of the standard techniques which were used in the past along with some popular recent ones.
Pre 2012:
- Using the bag of words representation which paid no heed to the ordering of words was the norm
- Latent Semantic Indexing (LSI), SVM (Support Vector Machine) and Hidden Markov Models (HMM) were the popular techniques
- Standard tricks of the trade were — POS tagging, NER etc
2013–2016
One of the more important developments in this period was work on “word embedding”.
Word Embedding
Word Embedding is nothing but useful numerical representation of words. While the early work on this concept was done as far back as 2003 (Bengio et al.), but it was really work by Tomas Nikolov et al (from Google) in 2013 on Word2Vec which gave it a real push.
One important point to note is, for many word embedding algorithms — while the representation is “learned” by training a model on certain task, example — to predict the next word given surrounding words — it turns out these learned representations give great performance in a variety of other NLP tasks
Word2Vec (2013) by Google
Uses Neural Network to come up with the word representations. There are two popular variants:
- Continuous bag of words (CBOW) — In this approach we try to predict a given word given its neighboring words (context)
- Skip Gram — The approach is similar, but we solve the reverse problem — given target words, try to come up with neighboring words
Word2Vec has a lot of nice and desirable benefits:
- The original model was trained on 1.6 B word dataset and with millions of words in the vocabulary
- The training is pretty fast
- Even people with modest amount of data could use these pre-calculated embeddings (generated by training on huge data) in their specific tasks and walk away with a lot of improvement
- The Word2Vec training itself was unsupervised, that is did not require pricey annotated data
- The numerical representation of words which were similar in meaning were close to each other (had small cosine distance)
- “Somewhat surprisingly, it was found that similarity of word representations goes beyond simple syntactic regularities. Using a word offset technique where simple algebraic operations are performed on the word vectors, it was shown for example that vector(”King”) — vector(”Man”) + vector(”Woman”) results in a vector that is closest to the vector representation of the word Queen”
There was additional work which was done on Word Embedding after the impetus which it received with Word2Vec. The most notable variants are:
GloVe — Global Vector for Word Representation (2014) by Stanford
- Attempted to combine benefits of both — global matrix factorization methods (like LSA), which do well on capturing statistical structure and local context windows methods like Word2Vec, which do well on analogy tasks.
- Instead of extracting numerical representations from training a neural network for certain task like predicting the next word, GloVe vectors have inherent meaning, which is derived from word co-occurrences
FastText (2016) by Facebook
- Its conceptually somewhat similar to Word2Vec, but with a twist — instead using words for creating embeddings, it uses n-gram of characters. For example, fastText representation of word “test” with n=2 would be <t, te, es, st, t>
- One of the major benefits of FastText is, the above approach allows it to generalize to unknown words, or the words which were not part of vocabulary in training
- Requires lesser training data compared to Word2Vec.
That’s it on embeddings — the key takeaway is you can find powerful numerical representations of words in almost any major language in the world, which are trained on huge text corpses and can give you a massive headstart in the NLP problem you are trying to solve, thanks to the algorithms listed above.
2014–2016
While a lot of work was happening around 2014 on embeddings, with the onset of Deep Learning era, another old technique was staging a comeback — the RNN
RNN — Recurrent Neural Network
RNN are a type of neural network that specialize in dealing with problems whose input / output are sequential in nature. The text data is inherently sequential given the fact that words are not placed randomly in a sentence and are informed by the grammar of the language. The idea of RNN was proposed as far back as 1980s, but they didn’t really take off given the challenges in training the model
Why RNN?
The basic challenge of classic feedforward neural network is that it has no memory, that is, each training example given as input to the model is treated independent of each other. In order to work with sequential data with such models — you need to show them the entire sequence in one go as one training example. This is problematic because number of words in a sentence could vary and more importantly this is not how we tend to process a sentence in our head.
When we read a sentence, we read it word by word, keep the prior words / context in memory and then update our understanding based on the new words which we incrementally read to understand the whole sentence. This is the basic idea behind the RNNs — they iterate through the elements of input sequence while maintaining a internal “state”, which encodes everything which it has seen so far. The “state” of the RNN is reset when processing two different and independent sequences.

While all this sounds great, but the reality is simplistic RNN described above are rarely used in practice. The reason is — while in theory the RNN should be able to retain the information seen many timesteps before, in practice this is almost impossible to do due to the vanishing gradient problem. Vanishing gradient is the problem due to which deeper networks take forever to train as the updates in parameters of the network becomes painfully slow. Two variants of RNN — LSTM and GRU were designed to solve this problem.
LSTM — Long Short Term Memory
LSTM is a variants of RNN with a way for carrying over information across many timestamps without getting diluted (vanished) due to a lot of processing.
Without getting into too much mathematics, the way LSTM achieves this is by means of three gates — Forget, Input and Output Gate. The Input gate determines the extent to which the current timestamp input should be used , the Forget gate determines the extent to which output of the previous timestamp state should be used, and the Output gate determines the output of the current timestamp
GRU — Gated Recurrent Unit
The GRU introduced in 2014 by Kyunghyun Cho et al was a simplified version of LSTM with just two gates instead of 3 and with a far fewer parameters vs LSTM.
GRU have been shown to have better performance on certain tasks and smaller datasets, but LSTM tend to outperform GRU in general.
There were some additional variants like bidirectional LSTM which don’t just process text left to right, but also do it right to left to give additional performance boost.
Closing Remarks
There was a lot of important work which happened off late on Word Embedding and Neural Network algorithms like RNN. These developments led to some rapid progress in the field of NLP and significantly improved the performance on various benchmark datasets.
But ..
The last few years have seen the rise of a new family of models called Transformers — These attention based models have completely swamped most of the other things. Many of the leading players have open sourced their version of Transformer architecture based models — BERT (Google), Transformer Xl (Google), GPT-2 (OpenAI), XL Net (CMU), ERNIE (Baidu).
In this post, I’ll cover the concept of Attention and Transformer which have become the building blocks for most of the state of the art models in NLP at present. I’ll also review BERT which made the powerful concept of transfer learning easier in NLP
Like my earlier post, I’ll skip most of the mathematics and focus more on intuitive understanding. The reason for this is — use of excessive notations and equations is a turn off for many, myself included. That’s actually not even critical for conceptual understanding which I believe is a lot more important than understanding each and every underlying mathematical equation.
While variants of RNN like Bi-LSTM give a pretty solid performance on various NLP tasks, following are some of the key challenges that still remain:
- Lack of parallelization hurts performance — LSTM needs to process the input tokens in a given sequence in a sequential manner as the output of the current step depends on the output of the previous step. There is no way to parallelize this computation, which comes with obvious disadvantages of long training time, not being able to train on very large datasets etc.
- Learning long term dependency remains a challenge —While LSTMs are better at remembering context from something which appeared a while back in a sequence compared to classic RNNs, remembering the context from a word which occurred much earlier in long sentences remains a challenges, that’s why performance is not as good in longer sentences/sequences compared to shorter ones.
- Linear increase in # operations with distance —The number of operations required to relate signals from two arbitrary input or output positions grows linearly in the distance between positions
The above challenges were the motivation for a lot of work which happened in 2017 and forward. The concept of attention addresses challenge #2 above and the transformer architecture addresses challenge # 1 and #3.
One thing to note is — while the concepts of attention and transformer helped break established benchmarks in NLP tasks, these are generic techniques with wide application in any sequence to sequence task. For instance, the transformer architecture was also a building block for AlphaStar the DeepMind bot that beat the top StarCraft II professional player.
Attention
The attention is one of the most influential ideas in Deep Learning in general. While the concept was originally developed for machine translation, its use quickly spread to a lot of other areas. It was proposed by Dzmitry Bahdanau et al in this influential paper.
The core idea behind it is — when performing a certain task, for example, translation of a sentence from one language to the other, say English to French, each word in the output French sentence would be informed by (relevant context of) all words in the original input English sentence with varying degree of attention or importance rather than a single/constant context generated by processing the whole English sentence.
Consider the following excellent English to French translation example from Google Blog. The “it” in the two sentences refers to different nouns, and its translation to French differs depending on which noun the “it” refers to.

To a human, It is obvious that in the first sentence pair “it” refers to the animal, and in the second to the street
The following picture depicts what happens conceptually with (self) attention. Rather than taking a context vector of the whole sentence and that informing the translation of the word “it”, the translation context would be informed by different words in the input sentence by a different amount as shown by the color coding (darker = more important)
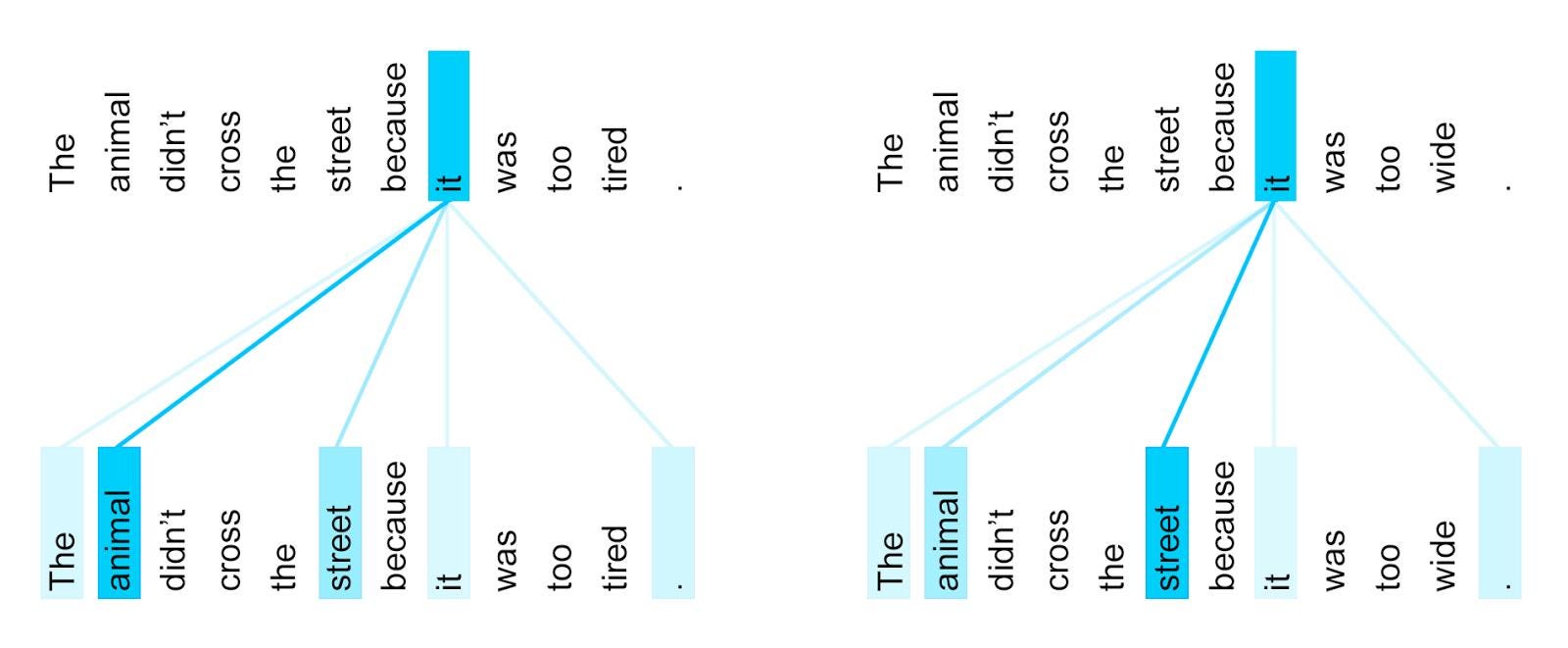
Source: Google Blog
One important thing to note is — attention weights in the model are not fixed, like the other parameters which are learned by neural network models, but are calculated as a function of input / hidden states — that’s how the model knows how to put appropriate emphasis on relevant words in the input sentence for any given sentence.
As illustrated above, the concept of attention addresses the problem of long term dependencies by using more appropriate context at each step (rather than a “constant” context, example in LSTM based encoder-decoder), but the problem of non parallelism in computation remains as the computation still needs to be done sequentially. With attention, if anything, we make the computation even more complex compared to simple LSTMs, this is where the Transformer architecture came to the rescue.
Transformer
Transformer was introduced in 2017 in this seminal paper by Vaswani et al from Google. The network architecture of Transformer is solely based on attention mechanism and has no RNN or CNN units. Following are some of the key benefits of this architecture:
- Superior quality results on language translation tasks, beating previous benchmarks
- More parallelizable and requires significantly less time to train
- Generalizes well to a lot of other tasks
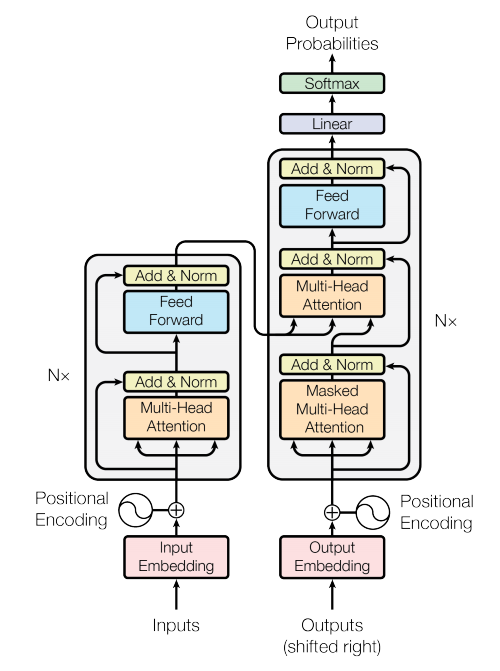
Transformer Model Architecture. Source Transformer Paper
The figure above shows the overall architecture of the Transformer, which is a bit scary at first blush. Let’s look at high level details of the architecture:
- Encoder-Decoder Architecture: It follows the famous Encoder Decoder paradigm, where Encoder translates the input into a useful representation which is used by decoder to generate the output. In the figure above, the Encoder block is on the left and Decoder block is on the right.
- Auto Regressive: At each step, the model consumes the previously generated output as an additional input
- No RNNs: There are no RNN units, only a bunch of attention layers.
- Multiple layers: Each of Encoder / Decoder consist of a stack of 6 (a hyperparameter in the model) identical layers
- Embedding: The Input / Output embedding converts text or words into numbers.
- Positional Encoding: The positional encoding is to encode the order of the original sequence as we no longer process the input sequentially like in RNN, so it ensures the information of ordering is not lost.
- Mult-Head attention: There are multiple attention layers running in parallel, for adding variety (akin to multiple convolution filters in Computer Vision).
- Attention layers: There are 3 types of attentions — Encoder self-attention, Encoder-Decoder Attention and Decoder self-attention.
- Self Attention: In case of Encoder self-attention (left-bottom attention block in figure), a layer within the Encoder tries to figure out how much attention it should pay to the output of the previous layer(of the Encoder), that is, tries to learn the relationship /context for each word in the input with the other words in the input. Decoder self-attention (right-bottom attention block in the figure)does the same thing but over Output.
- Encoder-Decoder Attention: With Encoder-Decoder attention (right-top attention block in the figure) The model figures out how relevant is each word in the input for each word in the output.
With those details, the results which Transformer achieved were impressive, however, there were some areas of improvement:
- It can only deal with fixed-length sentences.
- Larger sentences need to be broken into smaller ones for feeding into the model, which causes “context fragmentation”
BERT — Bidirectional Encoder Representations from Transformers
First, an honest confession — I just can’t memorize the full form for BERT no matter how many times I read it, I think the full form was derived from the acronym rather than the other way around :-)
BERT was proposed by Jacob et al from Google, its a language representation model based on Transformer. I think the major contribution of BERT, in addition to its novel bi-directional training, etc is that it played a big role in popularizing the concept of pre-training / transfer learning in NLP
Before we go further — just a few words about transfer learning. Its one of the most elegant concepts in Deep Learning was more popular in ComputerVision compared to NLP. The basic idea is — one can train a (deep, that is having multiple layers) model on a generic but related task, and just fine-tune the last few layers on their task-specific data to achieve great performance.
The rationale for transfer learning is — the earlier layers in a deep model learn more fundamental patterns, for example, learning to detect lines and curves in a computer vision model, and the latter layers learn the task-specific patters, example learning whether there is a cat in the picture or not. The major benefit of this approach is — you can get great performance even with a modest amount of data on deep learning models which are pretty data hungry in general.
Following are some important details about BERT:
- Bi-Directional training: Jointly trained by looking at words in both directions —left-to-right and right-to-left for better context, other language models are typically trained by looking at context in just one direction
- Pre-trained: Pre-trained on huge text corpses (~3B words), so you just need to fine-tune one additional output layer, that is very few parameters (using your training data) for getting very good performance on a variety of tasks like — sentence classification, question answering system, named entity recognition etc without having to do too many task specific changes in model architecture.
- Training Objective: Typically language models are trained in an unsupervised fashion, with the goal of predicting a word given words which immediately preceded it. BERT is jointly trained on two tasks — predict a word given the words on its left and right (with some details on masking to avoid leakage) and predicting the next sentence given a sentence. The latter is not standard, and language models typically do not directly capture relationships among sentences, but doing this tends to help applications like Question Answering systems for example.
- Model Size: The authors of the BERT paper experimented with BERT of various sizes, most notable — Base (110M parameters) and Large (340M parameters). They found that bigger is better, even with the similar model architecture and small task-specific training data, this is largely due to the pre-training on a huge corpus.
Since the Original paper of BERT in Oct’2018, there have been many variants and modifications which have been proposed. Most notable among them are — RoBERTa and mBERT by Facebook AI, XLNet by researchers at CMU and GPT-2 by Open AI.
This concludes my roundup of some exciting things off late in NLP, clearly, there is so much happening in the field and also at such a rapid pace. There is a lot which people can do with very little effort these days thanks to the giants in the field which have done the heavy lifting and made it easier.
Additional Resources
- Excellent visualization of RNN, Attention etc
- Building a Transformer from scratch
- Excellent library for using various Transformer architectures

 浙公网安备 33010602011771号
浙公网安备 33010602011771号