Better intuition for information theory
Better intuition for information theory
2019-12-01 21:21:33
Source: https://www.blackhc.net/blog/2019/better-intuition-for-information-theory/
The following blog post is based on Yeung’s beautiful paper “A new outlook on Shannon’s information measures”: it shows how we can use concepts from set theory, like unions, intersections and differences, to capture information-theoretic expressions in an intuitive form that is also correct.
The paper shows one can indeed construct a signed measure that consistently maps the sets we intuitively construct to their information-theoretic counterparts.
This can help develop new intuitions and insights when solving problems using information theory and inform new research. In particular, our paper “BatchBALD: Efficient and Diverse Batch Acquisition for Deep Bayesian Active Learning” was informed by such insights.
For a gentle introduction to information theory, Christopher Olah’s Visual Information Theory is highly recommended. The original work “A Mathematical Theory of Communication” by Claude Shannon is also highly accessible, but more geared towards signal transmission.
Information theory with I-diagrams
If we treat our random variables as sets (without being precise as to what the sets contain), we can represent the different information-theoretic concepts using an Information diagram or short: I-diagram. It’s essentially a Venn diagram but concerned with information content.
An I-diagram for two random variables XX and YY looks as follows:
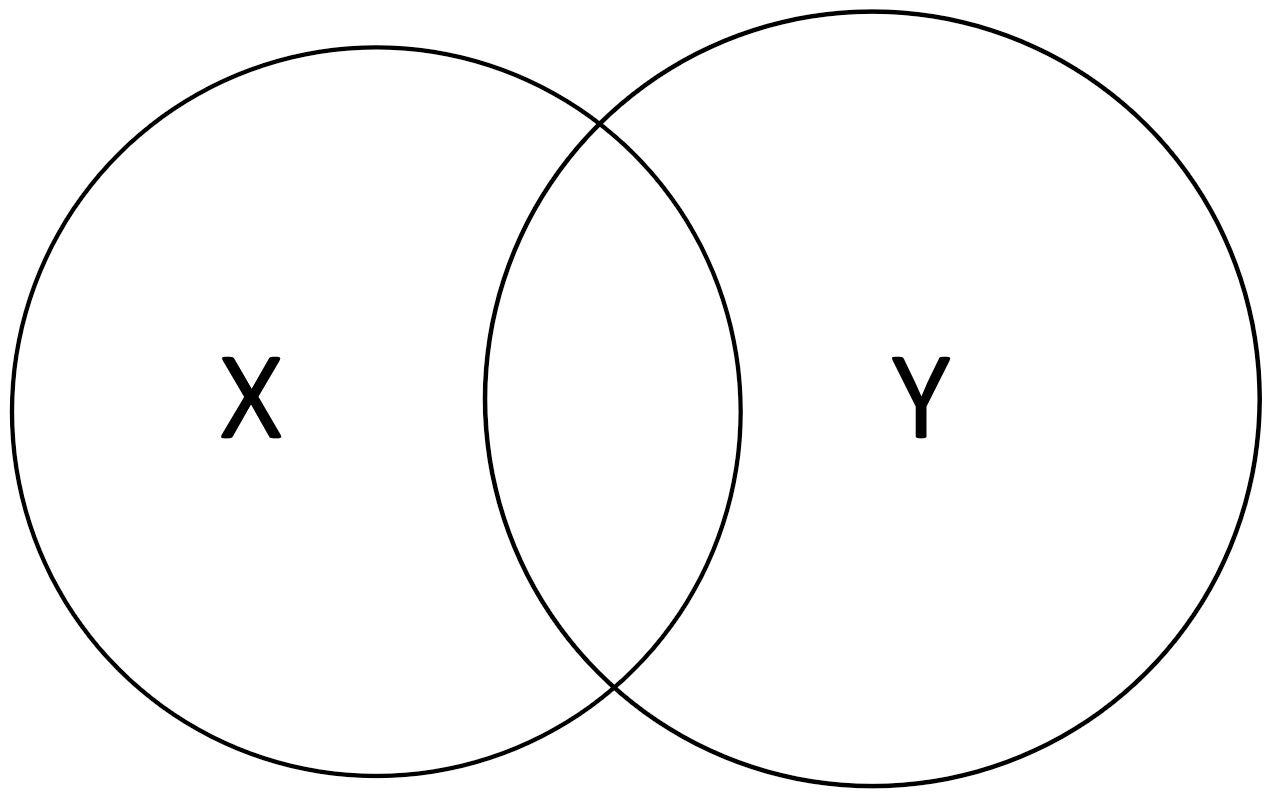
We can easily visualize concepts from information theory in I-diagrams.
|
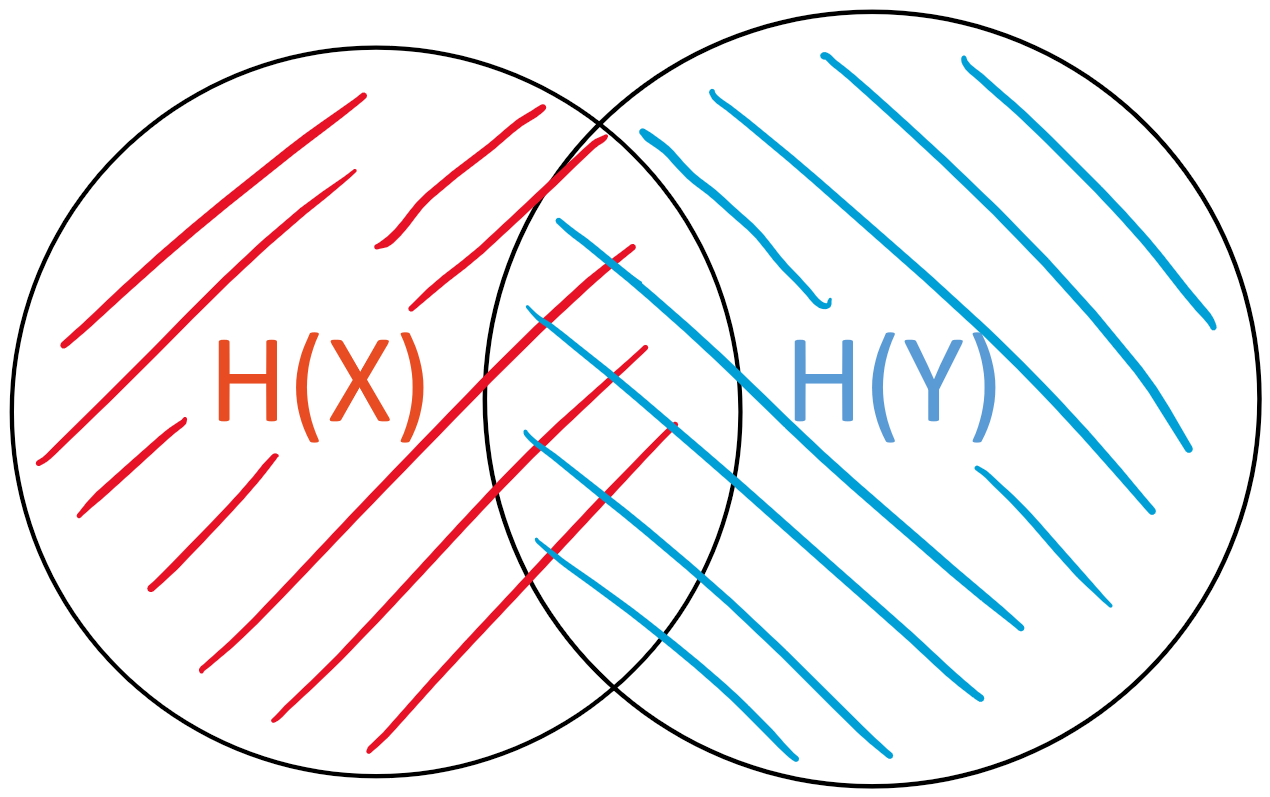
The entropy H(X)H(X) of XX, respectively H(Y)H(Y) of YY, is the “area” of either set
|
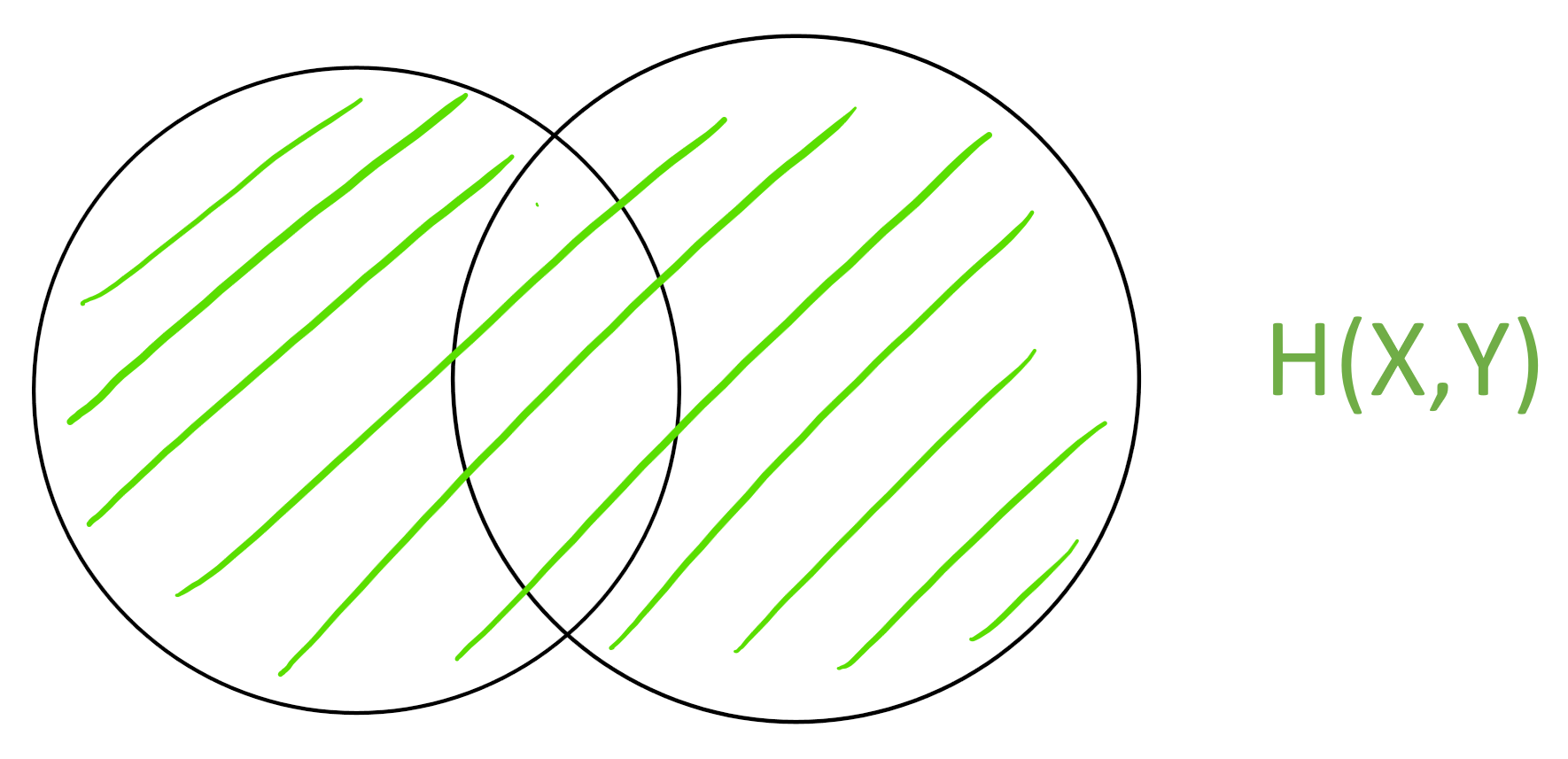
The joint entropy | H(X,Y)H(X,Y) is the “area” of the union X \cup YX∪Y
|
|
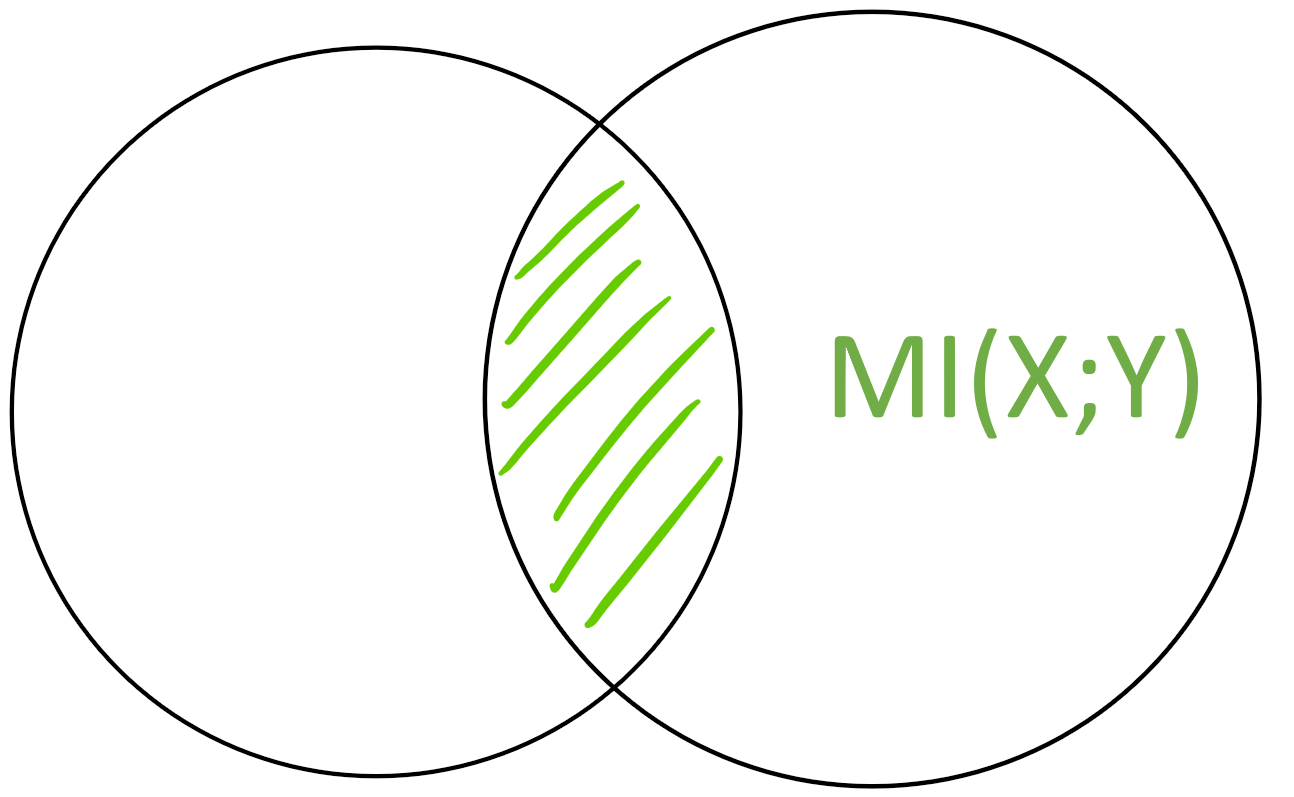
The mutual information MI(X;Y)MI(X;Y) is the “area” of the intersection X \cap YX∩Y
|
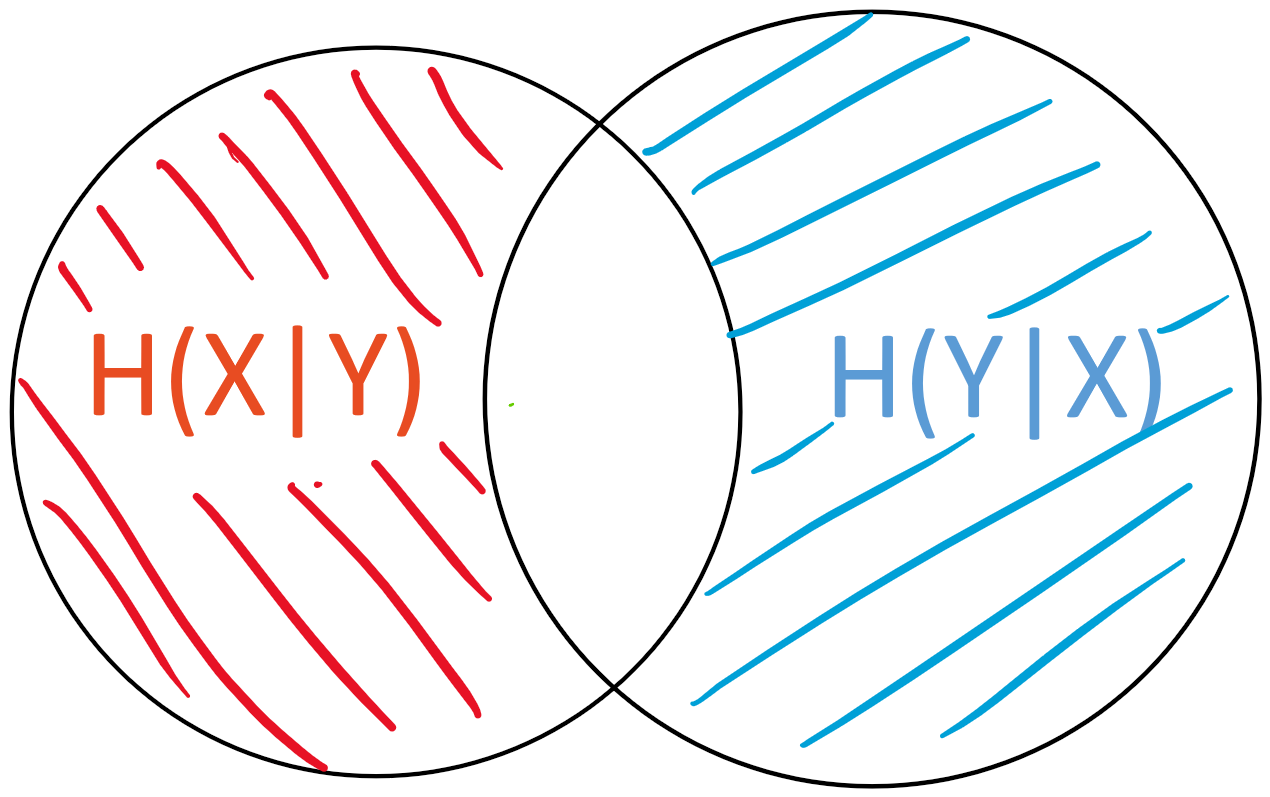
The conditional entropy H(X|Y)H(X∣Y) is the “area” of X - YX−Y
|
Benefits
This intuition allows us to create and visualize more complex expressions instead of having to rely on the more cumbersome notation used in information theory.
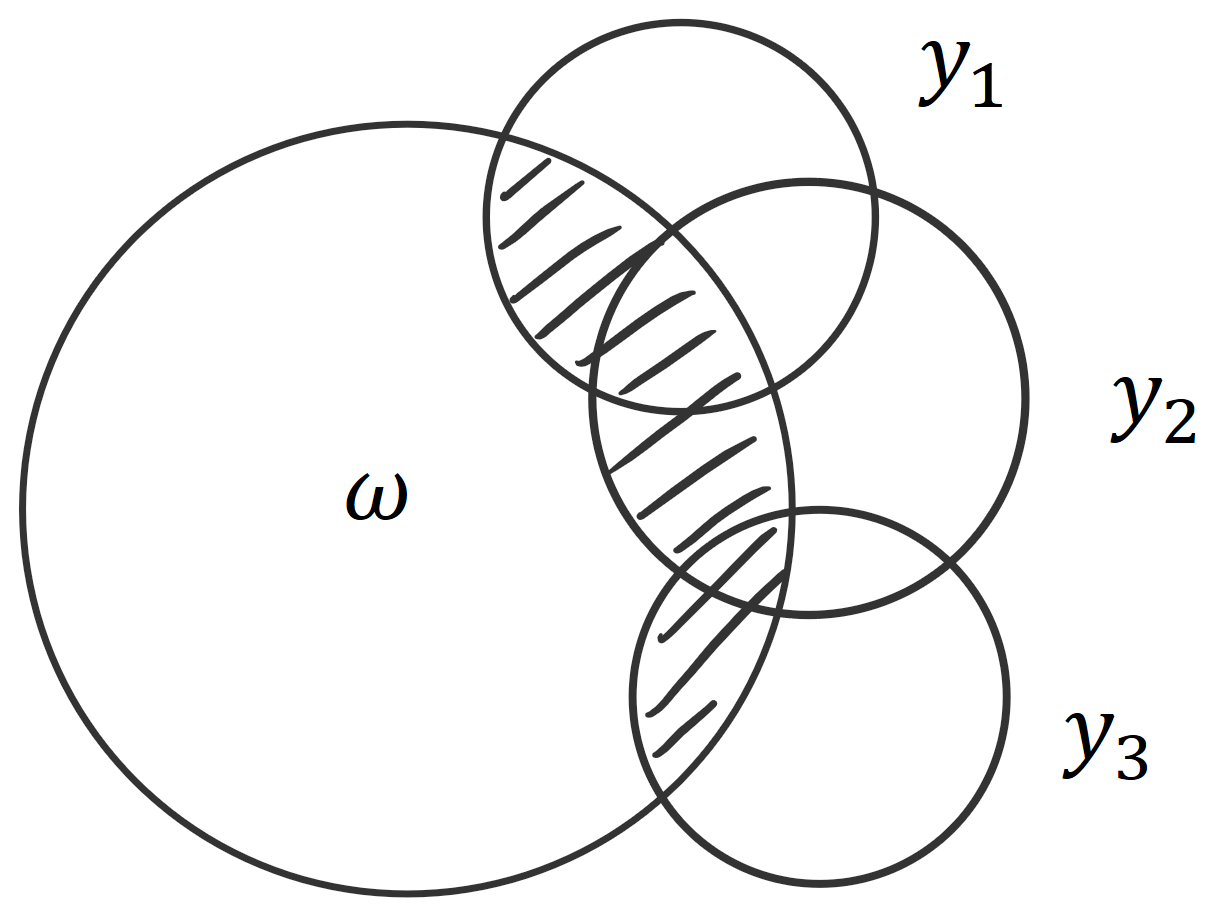 For example, BatchBALD relies on this intuition. We were looking for an information-theoretic measure that would allow us to capture the union of the predictions y_iyi intersected with the parameters \omegaω (to see why that is: read the blog post). Using an I-diagram, it’s easy to see that this is the same as the joint of all the predictions minus the joint of all the predictions conditioned on the parameters. This in turn is the same as the mutual information of the joint of predictions and the parameters:MI(y_1, y_2, y_3;\omega) = H(y_1, y_2, y_3) - H(y_1, y_2, y_3|\omega).MI(y1,y2,y3;ω)=H(y1,y2,y3)−H(y1,y2,y3∣ω).
For example, BatchBALD relies on this intuition. We were looking for an information-theoretic measure that would allow us to capture the union of the predictions y_iyi intersected with the parameters \omegaω (to see why that is: read the blog post). Using an I-diagram, it’s easy to see that this is the same as the joint of all the predictions minus the joint of all the predictions conditioned on the parameters. This in turn is the same as the mutual information of the joint of predictions and the parameters:MI(y_1, y_2, y_3;\omega) = H(y_1, y_2, y_3) - H(y_1, y_2, y_3|\omega).MI(y1,y2,y3;ω)=H(y1,y2,y3)−H(y1,y2,y3∣ω).
It is not immediately clear why this holds. However, using set operations, where \muμ signifies the area of a set, we can express the same as :\mu( (y_1 \cup y_2 \cup y_3) \cap \omega ) = \mu ( y_1 \cup y_2 \cup y_3 ) - \mu ( (y_1 \cup y_2 \cup y_3) - \omega )μ((y1∪y2∪y3)∩ω)=μ(y1∪y2∪y3)−μ((y1∪y2∪y3)−ω)From looking at the set operations, it’s clear that the left-hand side and the second term on the right-hand side together form the union:\mu( (y_1 \cup y_2 \cup y_3) \cap \omega ) + \mu ( (y_1 \cup y_2 \cup y_3) - \omega ) = \mu ( y_1 \cup y_2 \cup y_3 )μ((y1∪y2∪y3