
save tracking results into csv file for oxuva long-term tracking dataset (from txt to csv)
save tracking results into csv file for oxuva long-term tracking dataset (from txt to csv)
2019-10-25 09:42:03
Official Tools: OxUvA long-term tracking benchmark [ECCV'18] [Github]
Project page: https://oxuva.github.io/long-term-tracking-benchmark/
import os import numpy as np import cv2 import time import oxuva import pdb # export PYTHONPATH="/home/wangxiao/THOR/long-term-tracking-benchmark-master/python:$PYTHONPATH" # txtPath = '/home/wangxiao/THOR/benchmark/results/OXUVA/Tracker/' # txtFiles = os.listdir(txtPath) # csv_path = './oxuva_csv_results/' # for index in range(len(txtFiles)): # txtName = txtFiles[index] # pointPosition = txtName.find('.') # videoName = txtName[:pointPosition] # preds = np.loadtxt(txtPath + txtName, delimiter=',') # preds = preds.tolist() # spacePosition = txtName.find('_') # if spacePosition: # obj = 1 # else: # obj = txtName[spacePosition:spacePosition+1] # preds_file = os.path.join(csv_path, '{}_{}.csv'.format(videoName, obj)) # tmp_preds_file = os.path.join(csv_path, '{}_{}.csv.tmp'.format(videoName, obj)) # with open(tmp_preds_file, 'w', encoding='utf-8-sig') as fp: # pdb.set_trace() # oxuva.dump_predictions_csv(videoName, obj, preds, fp) # os.rename(tmp_preds_file, preds_file) # pdb.set_trace() import json import pdb import cv2 import os import pandas as pd resultpath= '/home/wangxiao/tracking_results_oxuva/' videopath="/home/wangxiao/dataset/OxUvA/images/test/" videos=os.listdir(videopath) txtFiles = os.listdir(resultpath) for i in range(len(videos)): txtName = videos[i] + "_oxuva-baseline.txt" preds = np.loadtxt(resultpath + txtName, delimiter=',') print("==>> txtName: ", txtName) xmin=[] xmax=[] ymin=[] ymax=[] video_ids=[] obj_ids=[] frame_nums=[] presents=[] scores=[] video_id=videos[i][0:7] if(len(videos[i])==7): obj_id='obj0000' elif(videos[i][-1]=='2'): obj_id='obj0001' else: obj_id='obj0002' present='True' score=0.5 # l=result['res'] imgs=os.listdir(videopath+videos[i]+'/') imgs = np.sort(imgs) # pdb.set_trace() image=cv2.imread(videopath+videos[i]+'/'+imgs[0]) imgh=image.shape[0] imgw=image.shape[1] for j in range(len(imgs)): # pdb.set_trace() x=preds[j][0] y=preds[j][1] w=preds[j][2] h=preds[j][3] ## results relative to original image size. x1=x/imgw x2=(x+w)/imgw y1=y/imgh y2=(y+h)/imgh x1=round(x1,4) x2=round(x2,4) y1=round(y1,4) y2=round(y2,4) frame=imgs[j][0:6] if(frame=='000000'): frame_num=0 else: frame_num=frame.lstrip('0') xmin.append(x1) xmax.append(x2) ymin.append(y1) ymax.append(y2) video_ids.append(video_id) obj_ids.append(obj_id) frame_nums.append(frame_num) presents.append(present) scores.append(score) # pdb.set_trace() dataframe=pd.DataFrame({'video_id':video_ids,'object_id':obj_ids,'frame_num':frame_nums,'present':presents,\ 'score':scores,'xmin':xmin,'xmax':xmax,'ymin':ymin,'ymax':ymax}) savepath='./oxuva_csv_results/' +videos[i][0:7]+'_'+obj_id+'.csv' columns=['video_id','object_id','frame_num','present','score','xmin','xmax','ymin','ymax'] dataframe.to_csv(savepath,index=False,columns=columns,header=None) # pdb.set_trace()
========= Results
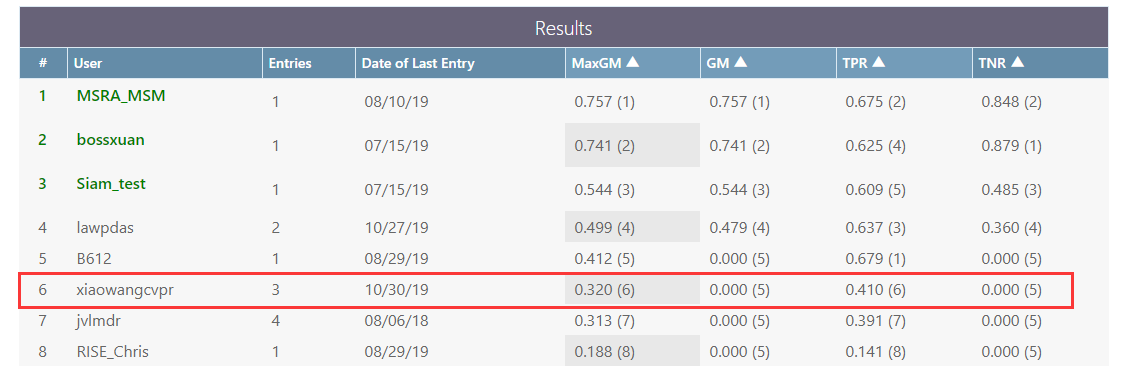
==
Stay Hungry,Stay Foolish ...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号