Deep High-Resolution Representation Learning for Human Pose Estimation
Deep High-Resolution Representation Learning for Human Pose Estimation
2019-08-30 22:05:59
Code: https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
Related Works:
1. High-Resolution Representations for Labeling Pixels and Regions, Sun, K., Zhao, Y., Jiang, B., Cheng, T., Xiao, B., Liu, D., ... & Wang, J. (2019). arXiv preprint arXiv:1904.04514.
2. Deep High-Resolution Representation Learning for Visual Recognition. Wang, Jingdong, et al. arXiv preprint arXiv:1908.07919 (2019).
3. Simple baselines for human pose estimation and tracking. Xiao, Bin, Haiping Wu, and Yichen Wei. Proceedings of the European Conference on Computer Vision (ECCV). 2018.
1. Background and Motivation:
以前的网络都是先降低分辨率,再提升分辨率 (encoder-decoder framework ?) ,如:Hourglass, simpleBaseline, dilated convolutions。而本文则提出一种分辨率网络(High-resolution Net,HRNet)来在整个过程中保持分辨率不降低。作者从高分辨率开始,逐渐的添加 high-to-low resolution subnetworks 来构成多阶的网络,并行的连接多尺度的网络。
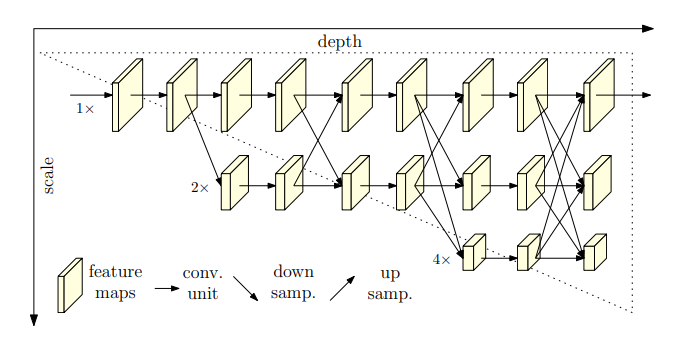
如上图所示,本文的方法对比传统方法有如下两点优势:
1). 本文的方法可以实现并行的连接 high-to-low resolution subnetwork,而不是像前人方法用序列的方式实现 low-to-high 的过程,所以,其 feature map 更加准确;
2). 大部分现有的机制集成 low-level and high-level representation, 而本文则是重复的多尺度融合,来实现高分辨率的表达。
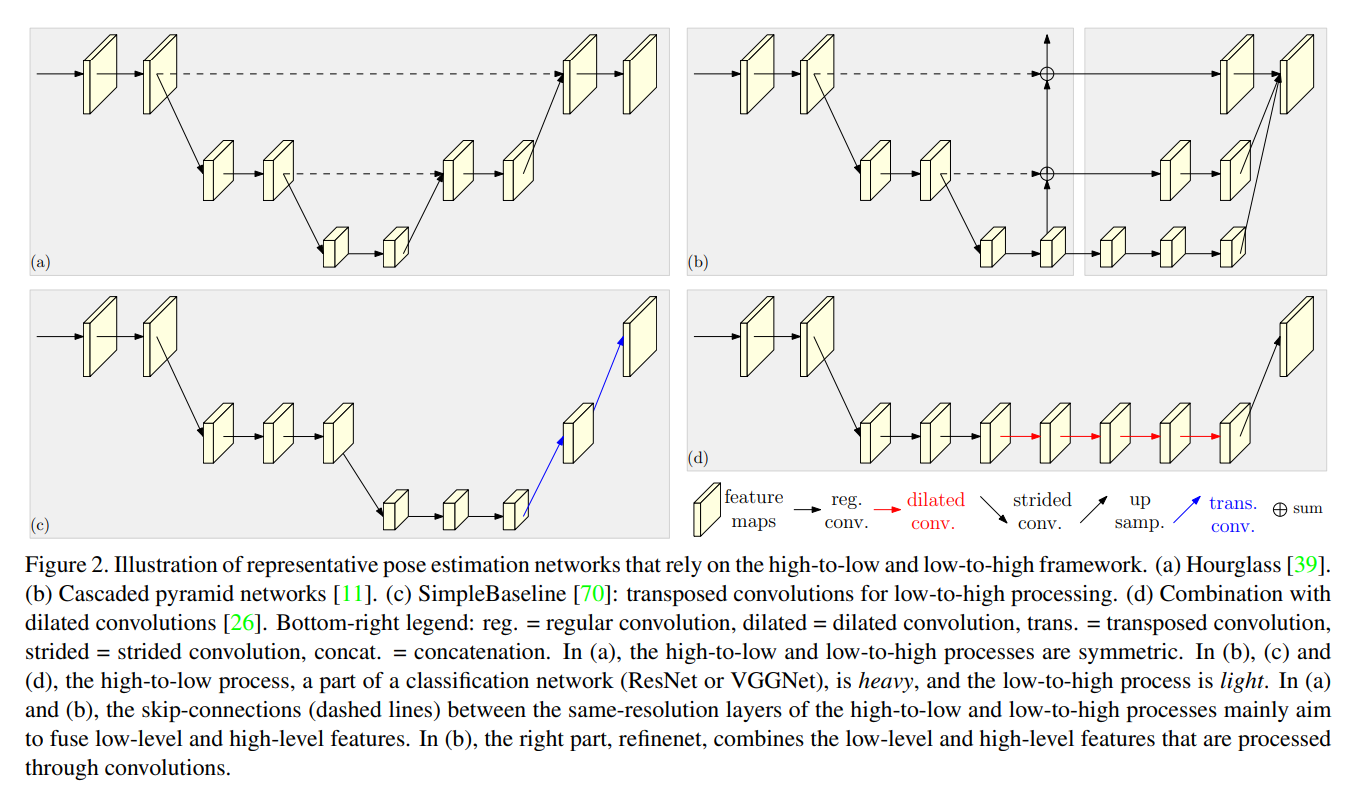
2. The Proposed Approach:
2.1. 序列化多分辨率子网络:
现有的网络是通过将 high-to-low resolution subnetworks 序列化的执行,其中每一个自网络构成一个阶段,是由一系列的 convolutions 组成,并且有下采样层来降低分辨率。
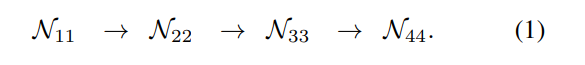
2.2 并行的多分辨率子网络:
我们从高分辨率子网络作为第一个阶段,逐渐的增加 high-to-low resolutions subnetworks 构成新的阶段,并且将这些多分辨率子网络连接。这样,后面阶段的子网络就包含了前面阶段的 resolution,还多了一个额外的 low-resolution 的。作者以 4 个并行的子网络为例,来说明这个过程:
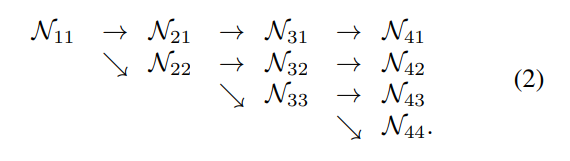
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号