Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking
2019-07-30 14:55:31
Code: not find yet.
Paper List of Tracking with Deep Reinforcement Learning: https://github.com/wangxiao5791509/Tracking-with-Deep-Reinforcement-Learning
1. Background and Motivation:
本文的贡献在于:
1). 提出一种 Actor-Critic Network 来预测物体运动的参数,并根据跟踪状态选择动作,不同的动作,会根据对结果的影响不同,设置不同的奖励;
2). 将 tracking 看做是迭代的平移问题,而不是 CNN Classification 问题,所以定位更加高效和准确;
3). 在 OTB 和 TC128 数据集上取得了较好的效果;
2. Approach:
本文所提出的方法包含三个模块:1). the actor network; 2). the prediction network; 3). the critic network.
2.1 Iterative Shift for Visual Tracking
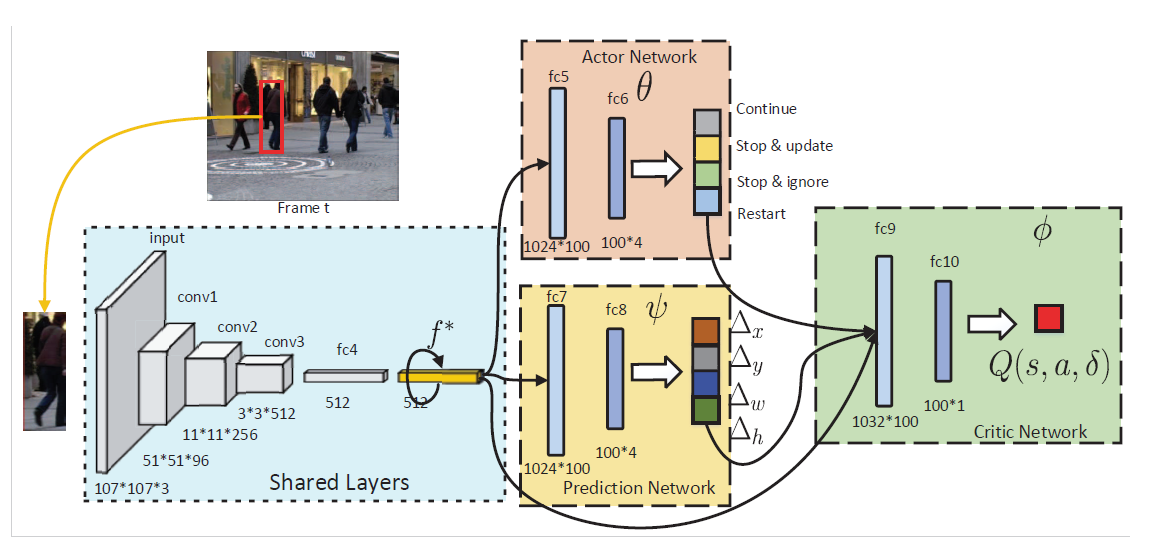
本文将 tracking 看做是迭代的平移问题。 给定当前帧和之前的跟踪结果,prediction network 会迭代的平移候选框,以定位住目标物体,与此同时,action network 会在跟踪状态上进行预测,判断是否进行模型的更新,预测网络,甚至是重启跟踪过程。
正式的来说,给定上一帧的跟踪结果 $l_{t-1} = {x_{t-1}, y_{t-1}, w_{t-1}, h_{t-1}}$ 以及 feature $f_{t-1}^*$,我们先根据该位置,得到当前帧的大致位置,抠出该 feature $f_t$,然后用预测网络进行预测:
![]()
其中,预测网络的输出为:

此外,跟踪状态也可能会影响最终的结果,即:需要适时的更新预测网络。为了联合的基于 target's motion status 以及 tracker's status 进行决策,我们利用 actor network 根据多项式分布来产生动作:

其中,$a_k \in A = \{ continuous, stop & update, stop & ignore, restart \}$。
对于动作 continuous 来说,即:不用更新模型,继续平移,而进行的 shift 是根据 prediction network 进行的。
对于动作 step & update 来说,即:停止平移,更新模型,即:

对于动作 stop & ignore 来说,停止平移,不更新模型,表示目标物体已经找到,然而,跟踪器无法确定是否需要进行更新。
对于动作 restart 来说,重新进行跟踪过程,即:restart the iteration by re-sampling a random set of candidate patches $L_t$ around $l_{t-1}^*$ in $I_t$ and select the patch which has the highest Q-values.
DRL-IS with Actor-Critic:
我们探索 AC算法,来进行联合的训练三个网络。首先作者根据跟踪的性能,进行了奖励的设定:
对于 continue 动作, 根据

对于 stop & update and stop & ignore 动作,奖励的设定是根据 final prediction 和 ground truth 之间的 IoU 进行评判的:

对于 restart 动作,当 final prediction 和 groundtruth 之间的 IoU 低于 0.4 时,给予 pos 的奖励:

然后,我们计算每一个动作的 Q-value。
对于 action continue 的 Q-value 来说:

对于其他的三个动作来说,是按照如下的式子进行计算:

最终,两个函数的优化是按照如下的式子进行的:

其中,s' 是下一个状态,a' 是选择的最优动作,Action-value 以及 Value function 是按照如下的方式进行计算的:


总体的算法过程如下所示:

==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号