(转)Extracting knowledge from knowledge graphs using Facebook Pytorch BigGraph.
Extracting knowledge from knowledge graphs using Facebook Pytorch BigGraph
2019-04-27 09:33:58
This blog is copied from: https://towardsdatascience.com/extracting-knowledge-from-knowledge-graphs-e5521e4861a0
Machine learning gives us the ability to train a model, which can convert data rows into labels in such a way that similar data rows are mapped to similar or the same label.
For example, we are building SPAM filter for email messages. We have a lot of email messages, some of which are marked as SPAM and some as INBOX. We can build a model, which learns to identify the SPAM messages. The messages to be marked as SPAM will be in some way similar to those, which are already marked as SPAM.
The concept of similarity is vitally important for machine learning. In the real world, the concept of similarity is very specific to the subject matter and it depends on our knowledge.
Majority of mathematical models, on the other hand, assume that the concept of similarity is defined. Typically, we represent our data as multidimensional vectors and measure the distance between vectors.
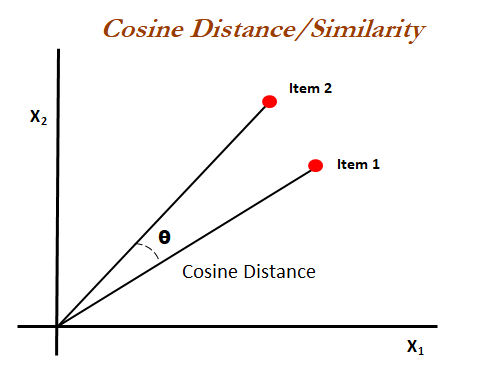
https://www.quora.com/Why-do-we-use-cosine-similarity-on-Word2Vec-instead-of-Euclidean-distance
Feature engineering is the process of converting our knowledge about the real-world objects into numerical representations of such objects. The objects we consider similar are represented as nearby vectors.
For example, we are working on estimating house prices. Our experience tells us that the house is defined by the number of bedrooms, number of bathrooms, age, sq. footage, location, etc. Houses, which are located in the same neighborhood, of similar size and age, should cost about the same amount. We convert our knowledge of the housing market into numbers characterizing the house and use it to estimate the price of the house.
Unfortunately, manual feature engineering, as described above, has limitations in terms of our ability to convert our knowledge into descriptive features.
Sometimes out knowledge is limited to the principles of similarity, but not the exact characteristics, which make the objects similar. Often our knowledge about the real world is more complex than what can be represented in a simple tabular format. It’s typically a graph of interconnected concepts and relationships.
Embedding models allow us to take the raw data and automatically transform it into the features based on our knowledge of the principles.
Word2Vec
Word2Vec is likely the most famous embedding model, which builds similarity vectors for words. In this case, our knowledge about the world is present in the form of a narrative, represented as texts, which are sequences of words.
Decades of hard work went into attempts to characterize words using manually defined features with limited success. These solutions typically could not scale to the full body of knowledge or work in limited cases.
It all changed when Tomas Mikolov and his team at Google decided to build a model, which works based on the well-known principles of similarity. The words used in similar context are typically similar. The context, in this case, is defined by the words located nearby.
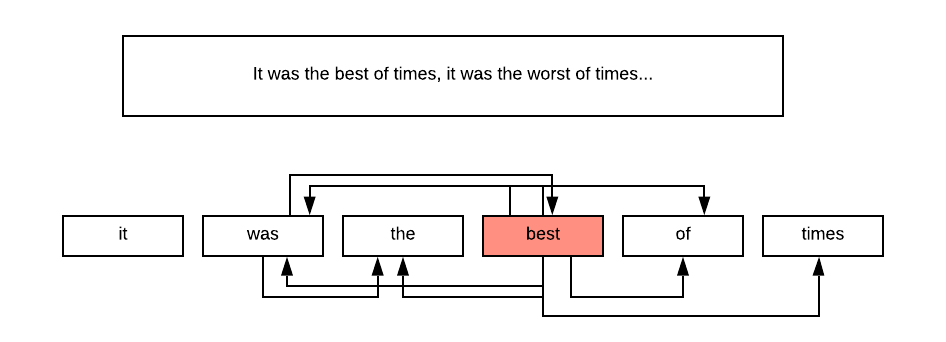
Graph representation of the sequence of words.
What we see is that with these principles in mind, we can build a graph out of our text by simply connecting each word with its neighbors within a predefined window (typically 5 words).
Now we have a graph of real word objects (words) connected based on our knowledge into a graph.
Most simple/complex word representation
We still unable to build any model because words are not represented in form or vectors.
If all we need is to convert the words to numbers, there is a simple solution. Let’s take our dictionary and assign each word its position in the dictionary.
For example, if I have three words: cat, caterpillar, kitten.
My vector representation will be as follows: cat-[1], caterpillar-[2] and kitten-[3].
Unfortunately, this does not work. By assigning numbers like this we implicitly introduce the distance between words. The distance between cat and caterpillar is 1 and the distance between cat and kitten is 2. We are saying that cat is more like a caterpillar than a kitten, which is contradictory to our knowledge.
Alternative representation also called one-hot encoding would do this:
cat — [1,0,0]
caterpillar — [0,1,0]
kitten — [0,0,1]
This schema says that all the words are orthogonal to each other. We admit that have no preconceived notion of words similarity. We will rely on our knowledge graph (as presented above), which incorporates our principles of word similarity, to build the embeddings.
In the real world, the dictionary size is much larger than just 3. Typical dimensionality is from tens of thousands to millions. Not only these vectors don’t really represent our notion of similarity, but these are also very bulky and can’t be really used in practice.
Building word embeddings
Our knowledge graph gives us a very large number of graph edges and each edge can be interpreted as input data as the start of the edge and the label as the end of the edge. We are building a model, which is trying to predict the word using the words it’s surrounded by as labels. It is typically done in two ways. We either reconstructing the word vector from the sum of its neighbors or we do the opposite by attempting to predict the neighbors from the word.

The details of the model are out of scope and well described in many other posts. Fundamentally, the team used the basic encoder/decoder model learning the projection from the high dimensional space (millions of dimensions) to the space of limited dimensionality (typically 300) and back to high dimensional space. The goal of the training is to preserve as much information as possible during this compression (minimize cross-entropy).

http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
This concept of learning the low dimensional projection from the sparse orthogonal dataset into more dense low dimensional space is the foundation of many other embedding training models.
The model is typically trained on sources like google crawl, twitter dataset or Wikipedia. We are consuming the world knowledge and building our word embeddings from this.
Properties of Word2Vec embeddings
The important properties of Word2Vec are the ability to preserve the relationships and expose structural equivalence.
The plots below show the connections between countries and capitals.

or other different concepts.

https://www.tensorflow.org/tutorials/representation/word2vec
Essentially it allows doing algebra on words like this:
king — man+woman=queen.
Using Word Embeddings
Word embeddings drastically improve tasks like text classification, named entity recognition, machine translation.
Here is more info: http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
Node2Vec
Node2Vec by A. Grover and J. Leskovec. is the model, which is analyzing the homogenous weighted graphs by expanding on the ideas from Word2Vec. The idea behind this paper is that we can characterize the graph node by exploring its surroundings. Our understanding of the world is based on two principles — homophily and structural equivalence.
Homophily
Similar nodes are located nearby.
Examples:
- social network — we are more connected to people like us.
- business location — financial firms, doctor offices or marketing companies seem to be typically located on the same street
- organizational structure — people on the same team share similar traits
Structural equivalence
Different communities share the same structure:
- organizational structure — while the teams can have weak connectivity, the structure of the team (manager, senior member, newcomers, junior members) is repeated from team to team.

https://arxiv.org/pdf/1607.00653.pdf
In order to incorporate both principles into our embeddings, the authors of Node2Vec paper propose a random walk approach combining breadth-first sampling to capture homophily and depth-first sampling to capture structural equivalence.
As we can see, the node (u) acts as a hub within a group (s1,s2,s3,s4), which is similar to s6 being a hub for (s7,s5,s8,s9). We discover the (s1,s2,s3,s4) community by BFS and (u)<->(s6) similarity by doing DFS.
We are learning about each node by exploring its surroundings. Such exploration transfers the graph into a large number of sequences (sentences) produced by random walks, which combine BFS and DFS exploration. BFS and DFS mix is controlled by the weights of the graph edges as well as the hyperparameters of the model.
Once we have the full body of sequences (sentences), we can apply the Word2Vec method the same way it was applied to texts. It produces the graph node embeddings, which are based on the principles we defined as well the knowledge from the graph.
Node2Vec Properties
Node2Vec representation improved the models for clustering and classification of the nodes. The learned similarity of the embeddings will be helpful for tasks like fraud detection.
Complementary visualizations of Les Misérables coappearance network generated by node2vec with label colors reflecting homophily (top) and structural equivalence (bottom). — https://arxiv.org/pdf/1607.00653.pdf

https://arxiv.org/pdf/1607.00653.pdf
Node2Vec shows significant improvements in link prediction. It was able to improve the ability to reconstruct the graph, where some percentage of edges were removed. The link prediction evaluation process is discussed further in this post.
Knowledge Graphs
Below we are going to discuss the PYTORCH-BIGGRAPH: A LARGE-SCALE GRAPH EMBEDDING SYSTEM paper further named PBG as well as the relevant family of papers.
Knowledge graphs are special types of graphs, which incorporate known entities as well as different types of edges. It represents structural knowledge.
In knowledge graphs, nodes are connected via different types of relationships.

https://arxiv.org/pdf/1503.00759.pdf
The goal of the training is to produce embeddings, which represent our knowledge. Once we have the embeddings of the nodes, it should be easy to determine if the corresponding nodes are connected (or should be connected) in our knowledge graph via the specific type of relationship.
Different models propose different ways of comparing embeddings. The most simple models compare embedding vectors using cosine or vector product distance. More complex models apply different weighting schemes for the elements of the vector before comparison. Weighting schemes are represented as matrices and are specific to the type of relationship. We can learn the weighting matrices as part of our training.

https://www.sysml.cc/doc/2019/71.pdf
We need to find a way to measure the similarity score between edges and use this score to estimate the possibility that these nodes are connected.
Representation of the knowledge graph
Knowledge graphs can be represented as adjacency tensor. To build it we would have a square matrix for every type of relationship. Each matrix has as many columns or rows as nodes in the graph. The value of the matrix will be 1 of these nodes are connected via this type of relationship and 0 if not. It’s pretty clear that this matrix will be very large and very sparse.
To learn our embeddings we need to convert each node into fixed sized vectors. Let’s discuss the properties of the “good” embeddings.
Good embeddings represent our knowledge expressed in the form of graph edges. Embedding vectors located “nearby” should represent the nodes, which are more likely connected. Based on this observation, we will train our model in such a way that the similarity score of the connected nodes marked as 1 in the adjacency tensor would be higher and the similarity score of the connected nodes marked as 0 in the adjacency tensor would be lower.

https://arxiv.org/pdf/1503.00759.pdf
We are training our embeddings to reconstruct the edges of the knowledge graph from node embeddings with minimum loss of information.
Negative sampling
Our training approach has a bit of a problem. We are trying to learn to distinguish between 1 (nodes are connected) and 0 (nodes are not connected) using the graph data. Yet, the only data we actually have is the nodes, which are connected. It’s like learning to distinguish cats from dogs by looking only at cats.
Negative sampling is a technique to expand our dataset and provide better training data by using very simple observation. Any randomly selected nodes, which are not connected as part of our graph will represent a sample data with a label 0. For the purposes of training, the PBG paper proposes to read each edge of the graph and then propose a negative sample, where one of the nodes is replaced with a randomly selected node.
For each edge, we can assign a positive similarity score and a negative similarity score. The positive similarity score is calculated based on the node embeddings and the edge relationship type weights. The negative similarity score is calculated the same way, but one of the nodes of the edge is corrupted and replaced by the random node.
Ranking loss function, which will be optimized during the training. It is constructed to establish a configurable margin between positive and negative similarity scores for all nodes in the graph and all relationship types. Ranking loss is a function of node embeddings and relationship-specific weights, which will be learned by finding minimum ranking loss.
Training
Now we have everything we need to train the embedding models:
- data — negative and positive edges
- labels — (1 or 0)
- function to optimize (it can be ranking loss, more traditional logistic regression loss or cross entropy softmax loss used in word2vec)
- our parameters, which are embeddings as well as the weight matrices for the similarity score function.
Now it’s a matter of using calculus to find the parameters — embeddings, which optimize our loss function.
Stochastic gradient descent
The essence of the stochastic gradient descent is to gradually adjust the parameters of the loss function in such a way that the loss function is getting gradually decreased. To do this we read the data in small batches use each batch to calculate the update to the parameters of the loss function to minimize it.
There are multiple ways of doing stochastic gradient descent. PBG paper uses ADAGrad, which is one of the flavors of stochastic gradient descent to find the parameters, which minimize our loss function. I highly recommend this blog to understand all the flavors of gradient descent: http://ruder.io/optimizing-gradient-descent/index.html#adagrad
Software packages like tensorflow and pytorch provide out of the box implementations for different flavors.
The key element of gradient descent is the process of updating the parameters of the model many times until we minimized the loss function. At the end of the training, we expect to have the embeddings and scoring functions, which satisfy the goals of incorporating our knowledge.
HogWild — Distributed Stochastic Gradient Descent
Going distributed with stochastic gradient descent poses a challenge. If we simultaneously train by adjusting the parameters to minimize the loss function, there needs to be some sort of locking mechanism. In traditional multithreaded development, we lock our data during the update via pessimistic or optimistic locking. Locking slows down the progress but ensures the correctness of our results.
Luckily, the hogwild paper proved that we don’t need to have a locking mechanism. We can simply read data in batches, calculate the parameter adjustments and just save these in the shared parameter space with no regard for correctness. HogWild algorithm does exactly that. Training can be distributed and each HogWild thread can update our parameters without regard for other threads.
I recommend this blog to get more info on HogWild: https://medium.com/@krishna_srd/parallel-machine-learning-with-hogwild-f945ad7e48a4
Distributed training
When the graph spans billions of nodes and trillions of edges, it’s hard to fit all the parameters in the memory of one machine. It also takes a lot of time if we would wait for the end of each batch to complete the calculations before starting another batch. Our graph is so large that it would be beneficial to be able to parallelize the training and learn the parameters simultaneously. This problem is solved by Facebook team, who released PBG paper.
Nodes are split by entity types and then organized into partitions:

https://torchbiggraph.readthedocs.io/en/latest/data_model.html

https://torchbiggraph.readthedocs.io/en/latest/data_model.html

https://www.sysml.cc/doc/2019/71.pdf
- The nodes are partitioned into P buckets and edges are partitioned into PxP buckets. Entity types with small cardinality do not have to be partitioned.
- Training is done in parallel with the following constraints:
for each edge bucket (p1; p2) except the first, it is important that an edge bucket (p1; *) or (*; p2) was trained in a previous iteration.
Multiple edge buckets can be trained in parallel as long as they operate on disjoint sets of partitions.

https://www.sysml.cc/doc/2019/71.pdf
Training is happening in parallel on multiple machines and multiple threads per each machine. Each thread calculates the parameter update based on the allocated bucket and batch of data. The lock server distributes training buckets according to the established constraints. Notice that the lock server only controls the distribution of data batches across the hogwild threads and not the parameter updates.
Characteristics of PBG embeddings
Knowledge embeddings can be used in two ways:
- Link predictions.
Link predictions help to fill the gaps in our knowledge by finding the nodes, which are likely connected or about to be connected.
Example: The graph represents customers and products bought by the customers. Edges are purchase orders. Embeddings can be used to form the next purchase recommendations. - Learning the properties of nodes
Embeddings can be used as feature vectors supplied as an input to all kinds of classification models. The learned classes can fill the gaps in our knowledge about the properties of the objects.
Evaluating link predictions using MRR/Hits10
This process is described in the paper — “Learning Structured Embeddings of Knowledge Bases” and later was used as the way to measure the quality of embedding models in many other papers including Facebook PBG.
The algorithm takes a subset of test edges and performs the following:
- Corrupt the edge by replacing the beginning or end of the edge with a negatively sampled edge.
- Train the model on a partially corrupted dataset
- Calculate aggregate MRR and Hits10 metrics for the edges from the test dataset.
Mean reciprocal rank
MRR or Mean reciprocal rank is a measure of search quality. We take an uncorrupted node and find the “nearest neighbors” with distance defined as the similarity score. We rank the nearest neighbors by the similarity score and expect that the node, which was connected, would appear on top of the ranking. MRR decreases the accuracy score in case the node is not raked on top.
The alternative measure is Hits10, where we expect the corrupted node to appear in the top 10 nearest neighbors.

https://www.sysml.cc/doc/2019/71.pdf
PBG paper shows that on many data sets the MRR metrics gradually increases as we allocate the resources into training. Parallelism does not affect the quality of ranking to a point but saves tremendous amounts of time.
Further evaluation can be performed by simply exploring and visualizing the graphs.
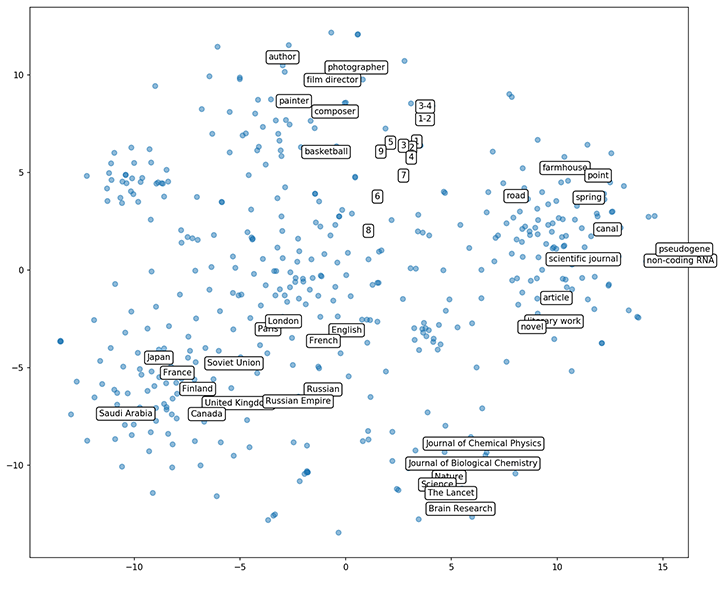
The image above is a 2d projection of the embeddings built from the Freebase knowledge graph. As we can see, similar nodes are grouped together. Countries, numbers, scientific journals professions seem to have clusters even on the carefully prepared 2d projection.
Limitations of the knowledge graph models.
Knowledge graphs as described above represents a static snapshot of our knowledge. It does not reflect the process of it’s how the knowledge built up. In the real world, we learn by observing temporal patterns. While it’s possible to learn the similarity between nodes A and node B, it will be hard to see the similarity between node A and node C as it was 3 years ago.
For example, if we look at the forest for one day we will see the similarity between two large sequoia trees. Yet it will be hard to understand which sapling will grow into a large sequoia tree without long term observations of the forest.
Ideally, we need to explore the series of knowledge graphs built at different points in time and then build the embeddings, which will incorporate generational similarities.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号