论文笔记:Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells
2019-04-24 14:49:10
Paper:https://arxiv.org/pdf/1810.10804.pdf
在过去的许多年,大家一直认为网络结构的设计是人类的事情。但是,近些年 NAS 的发展,打破了这种观念,用自动化的方法在给定的数据上设计合适的网络结构,变的势不可挡。本文在语义分割的任务上,尝试搜索高效的 encoder-decoder framework,并在其他类似任务上做了验证。
1. 方法:
1.1 问题定义:
我们考虑 dense prediction task T, 输入是 3维的 RGB image,输出是 C 维的 one-hot segmentation mask,C 是等于类别数目的。我们将从该输入到对应输出的函数,记为 f,即:全卷积网络结构。我们假设 f 可以进一步的分解为两个部分,即:e-代表 encoder,d-代表 decoder。我们用预训练的分类任务的模型来初始化 encoder e,另外,decoder d 部分,就是选择访问 encoder 的多个输出,然后选择利用哪些 operation 在这个上面进行对应的操作。
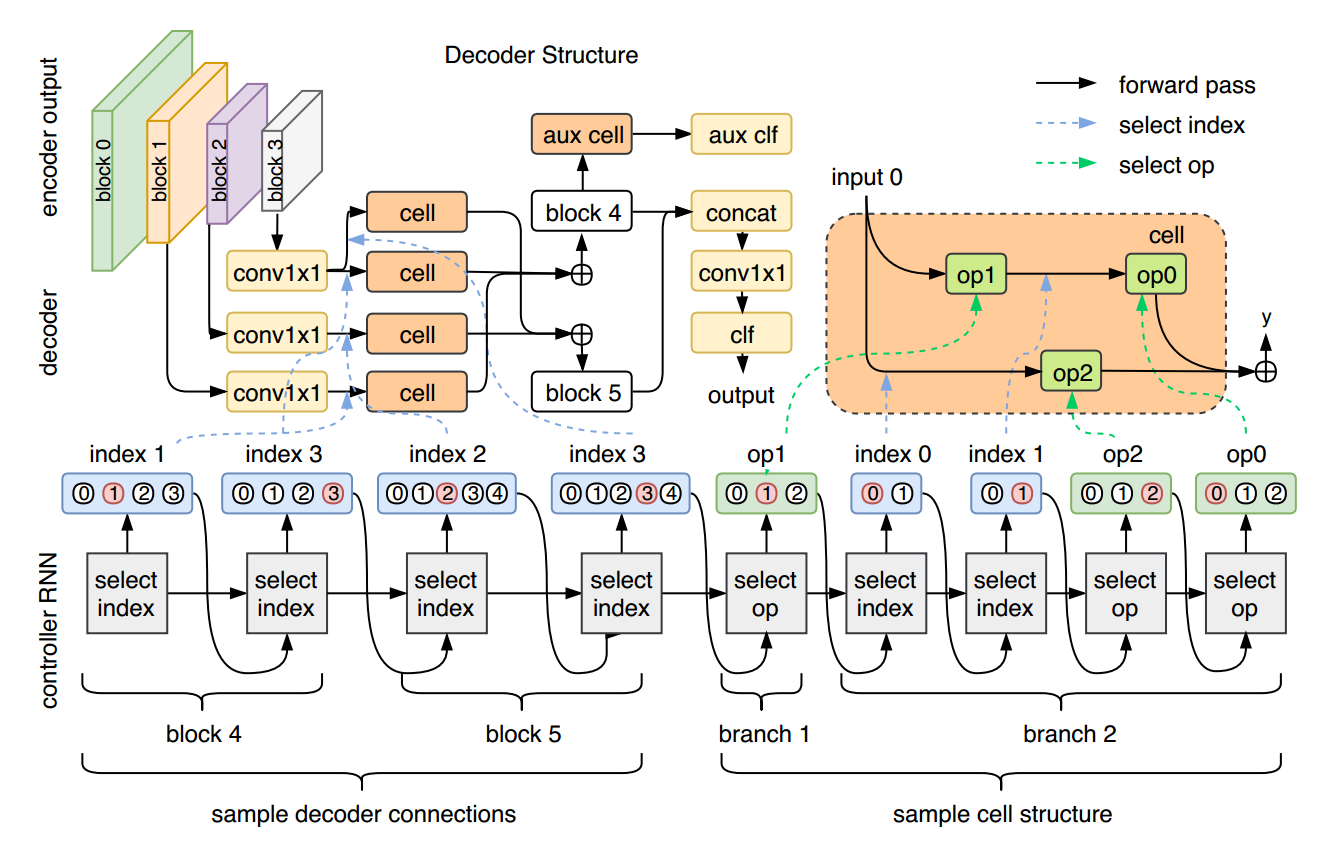
1.2 Search Space:
这里作者着重关注 decoder 部分,该 decoder 可以访问 pre-trained encoder 的多个 layer,从而可以获得多个不同分辨率的输出。为了使得采样的结构紧凑,每一个 encoder 的输出会经过一个 1*1 convolution,得到相同数目的 channel。我们依赖于 RNN 模型,来序列的产生该利用的 layer 的索引 (produce pairs of indices of which layers to use) 以及在这些数据上利用什么操作。特别的,这些操作的序列组合起来,得到一个 cell(如图1所示)。同样的 cell 但是用不同的 weights,对采样到的 layer 进行操作;两个 cell 的输出进行 sum。在 sampling pooling 之后添加 resultant layer。采样的 layer 个数是由超参数控制的,文中设置为 3,允许 controller (即 RNN)来恢复出该 encoder-decoder architecture,比如:FCN, RefineNet。所有的非采样的加和输出,都被组合起来,然后输入到 1*1 卷积中,以进行降维。
作者使用了如下的 11 种操作,作为搜索空间:

1.3 Search Strategy:
作者将 training set 划分为两个不连续的集合,meta-train 以及 meta-val。meta-train 是用于训练在特定任务上的 sampled architecture,meta-val 则是用于衡量 trained architecture 的性能,并提供给 controller 一个 scalar,在 DRL 中通常称为 reward 。给定采样的序列,其 logarithmic probabilities 以及 reward signal, the controller 都用 PPO 进行优化。所以,本文的任务就有两个训练过程:
inner --- optimization of the sampled architecture on the given task,
outer --- optimization of the controller.
作者接下来对 inner 的过程进行了详细的介绍。
1.4 Progressive Stages:
作者将 inner training process 分为两个阶段:在第一个阶段,固定住 the encoder weights,所以其输出是可以预先计算的,然后仅仅训练 decoder 部分。这种策略可以快速的更新 decoder 的权重,可以对 sampled architecture 进行一个合理的性能评估。我们探索了一个检测的方法来决定是否继续,在第二阶段训练 the sampled architecture。确切的说,当前 reward value 是和所看到的 running mean of rewards 相比较,如果大于平均值,我们继续训练。否则,我们以 1-p 的概率来终止训练过程。概率 p 在搜索过程中是从 0.9 渐变的(annealed)。
而这么做的动机是:在第一个阶段,虽然有些许噪声,但是仍然可以提供潜在的 sampled architecture 的合理预测。至少,他们提供了一个可靠地信号:the sampled architecture is non-promising, 当仅仅花费几秒钟在这个任务上。这种简单的方法,在前期可以鼓励探索。
1.5 Fast training via Knowledge Distillation and Weights' Averaging:
对于语义分割任务来说,需要多次的迭代才能够收敛。通过用 pre-trained classification model 来初始化 encoder 部分可以很大程度上缓解该问题,但是对于 decoder 来说,不存在这种 pre-trained model。作者探索了几种其他的策略,来加速收敛过程:
1). we keep track of the running average of the parameters during each stage and apply them before the final valivation.
2). we append an additional l2-loss term between the logits of the current architecture and a pre-trained teacher network.
这两种方法的组合允许我们接受一个非常可靠地分割模型的性能预测。
1.6 Intermediate Supervision via Auxiliary Cells:
作者添加了一个 辅助单元(auxiliary cell),该 cell 是和 main cell 相同的。同时,在训练和测试阶段,其也不影响 main classifier 的输出,而仅仅对剩下的网络提供更好的梯度。最终,每一个采样的网络结构的奖励,仍然由 main classifier 的输出决定。为了简单起见,我们仅仅在该辅助输出上计算分割损失(segmentation loss)。中间监督的概念,并不是很新,但是前人的工作仅依赖于辅助分类器,而本文作者首次将 decoder 的设计与辅助单元的设计相结合。
2. Experiments:
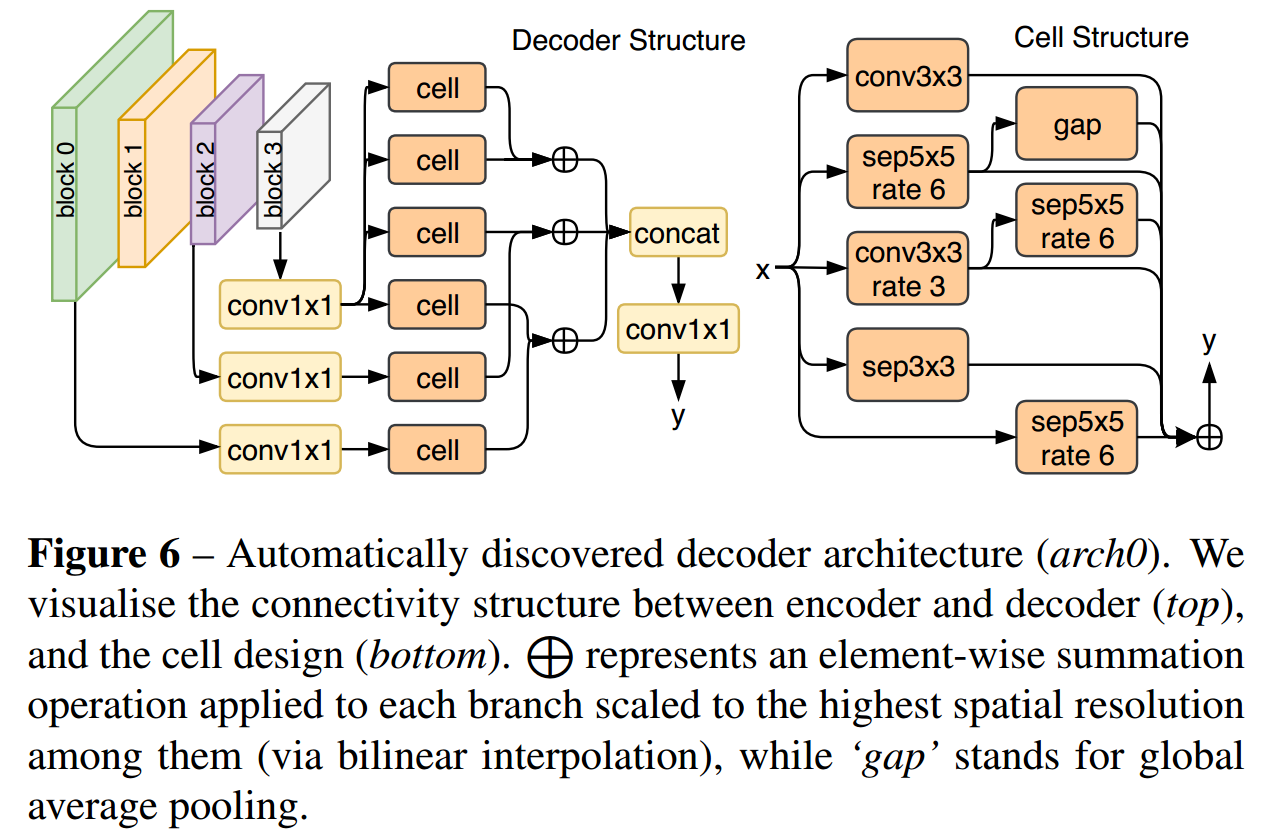
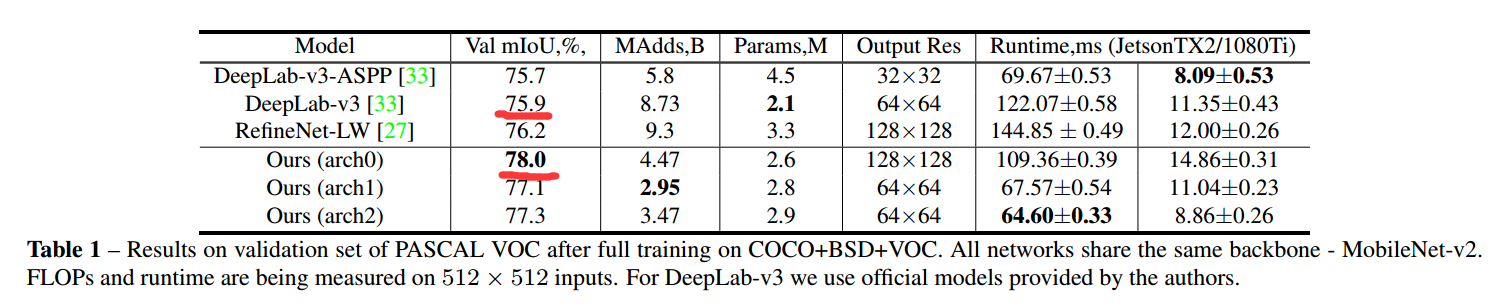
下面该 decoder 网络结构就是作者搜索出来的,取得了很好的分割效果。
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号