论文笔记:SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
2019-04-02 12:44:36
Paper:https://arxiv.org/pdf/1812.11703.pdf
Project:https://lb1100.github.io/SiamRPN++
Official Code: https://github.com/STVIR/pysot
Unofficial Pytorch Implementation: https://github.com/PengBoXiangShang/SiamRPN_plus_plus_PyTorch (Support Multi-GPU and LMDB data preprocessing)
1. Background and Motivation:
与 CVPR 2019 的另一篇文章 Deeper and Wider Siamese Networks for Real-Time Visual Tracking 类似,这篇文章也是为了解决 Siamese Tracker 无法利用 Deep Backbone Network 的问题。作者的实验发现,较深的网络,如 ResNet, 无法带来跟踪精度提升的原因在于:the distroy of the strict translation invariance。因为目标可能出现在搜索区域的任何位置,所以学习的target template 的特征表达应该保持 spatial invariant,而作者发现,在众多网络中,仅仅 AlexNet 满足这种约束。本文中,作者提出一种 layer-wise feature aggravation structure 来进行 cross-correlation operation,帮助跟踪器从多个层次来预测相似形图。
此外,作者通过分析 Siamese Network 发现:the two network branches are highly imbalanced in terms of parameter number; 作者进一步提出 depth-wise separable correlation structure,这种结构不但可以大幅度的降低 target template branch 的参数个数,还可以稳定整个模型的训练。此外,另一个有趣的现象是:objects in the same categories have high response on the same channels while responses of the rest channels are supressed. 这种正交的属性可能有助于改善跟踪的效果。
2. Analysis on Siamese Networks for Tracking:
各种实验说明了 stride,padding 对深度网络的影响。
3. ResNet-driven Siamese Tracking :
为了降低上述影响因子对跟踪结果的影响,作者对原始的 ResNet 进行了修改。因为原始的残差网络 stride 为 32,这个参数对跟踪的影响非常之大。所以作者对最后两个 block 的有效 stride,从 32 和 16 改为 8,并且通过 dilated convolution 来增加 receptive field。利用 1*1 的卷积,将维度降为 256。但是这篇文章,并没有将 padding 的参数进行更改,所以 template feature map 的空间分辨率增加到 15,这就在进行 correlation 操作的时候,计算量较大,影响跟踪速度。所以,作者从中 crop 一块 7*7 regions 作为 template feature,每一个 feature cell 仍然可以捕获整个目标区域。作者发现仔细的调整 ResNet,是可以进一步提升效果的。通过将 ResNet extractor 的学习率设置为 RPN 网络的 1/10,得到的 feature 可以更加适合 tracking 任务。
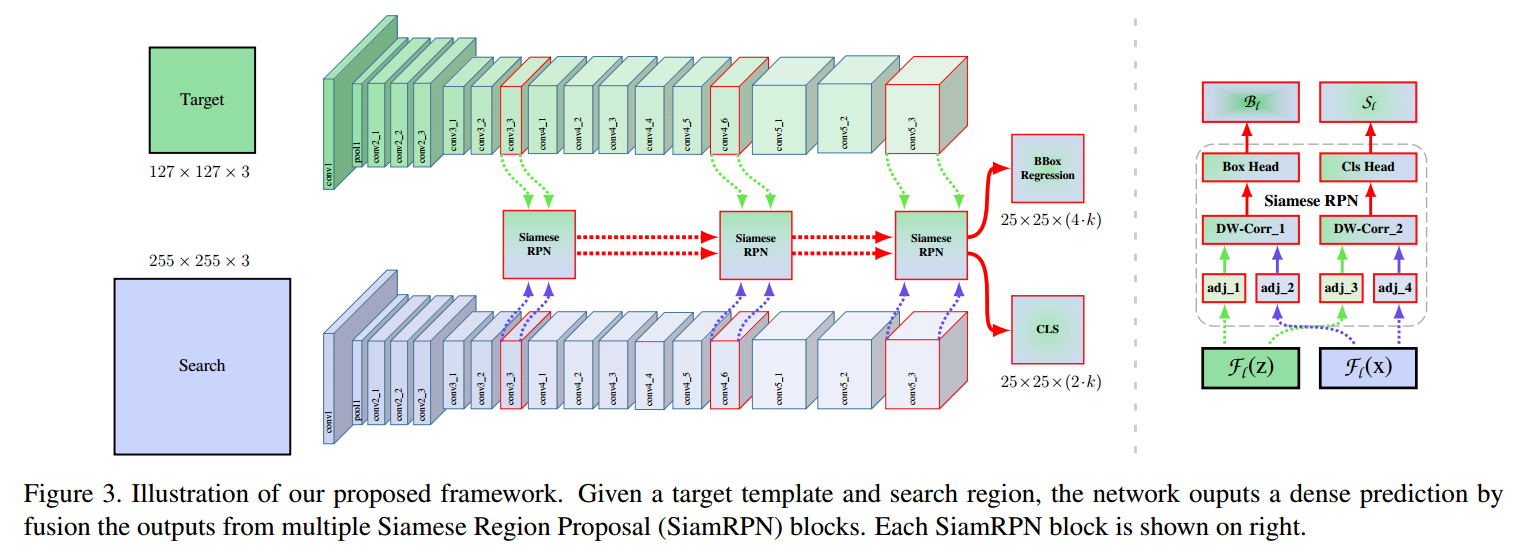
4. Layer-wise Aggregation :
本文是想利用多层特征的聚合来提升特征表达,提升跟踪结果。作者从最后三个残差模块,得到对应的输出:F3(z), F4(z) 以及 F5(z)。由于多个 RPN 模块的输出,有相同的分辨率。所以,直接对这几个结果进行加权求和,可以表达为:
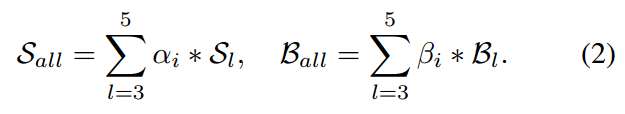
5. Depthwise Cross Correlation :
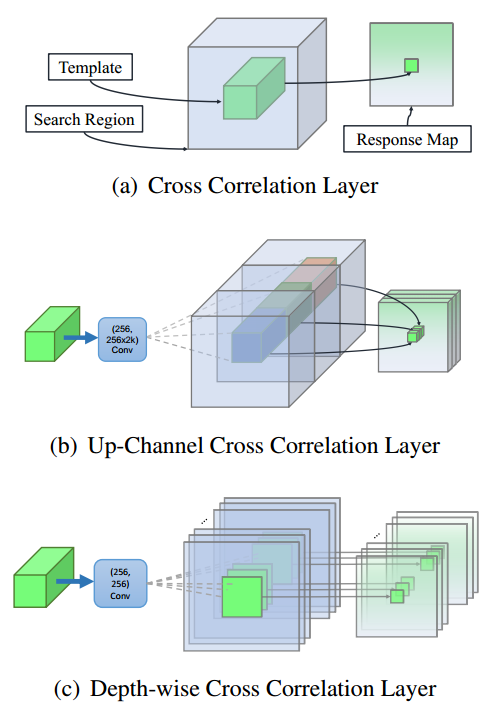
Cross correlation module 是映射两个分支信息的核心操作。SiamFC 利用 Cross-Correlation layer 来得到单个通道响应图进行位置定位。在 SiamRPN 中,Cross-Correlation 被拓展到更加高层的信息,例如 anchors,通过增加一个 huge convolutional layer 来 scale the channels (UP-Xcorr)。这个 heavy up-channel module 使得参数非常不平衡(RPN 模块包含 20M 参数,而特征提取部分仅包含 4M 参数),这就使得 SiamRPN 变的非常困难。于是作者提出一个轻量级的 cross correlation layer,称为:Depthwise Cross Correlation (DW-XCorr),以得到更加有效的信息贯通。DW-XCorr layer 包含少于 10 倍的参数(相比于 UP-XCorr used in RPN),而性能却可以保持不降。
为了达到这个目标,作者采用一个 conv-bn block 来调整特征,来适应跟踪任务。Bounding box prediction 和 基于 anchor 的分类都是非对称的 (asymmetrical)。为了编码这种不同,the template branch 和 search branch 传输两个 non-shared convolutional layers。然后,这两个 feature maps 是有相同个数的 channels,然后一个 channel 一个 channel 的进行 correlation operation。另一个 conv-bn-relu block,用于融合不同 channel 的输出。最终,最后一个卷积层,用于输出 classification 和 regression 的结果。
通过用 Depthwise correlation 替换掉 cross-correlation,我们可以很大程度上降低计算代价和内存使用。通过这种方式,template 和 search branch 的参数数量就会趋于平衡,导致训练过程更加稳定。
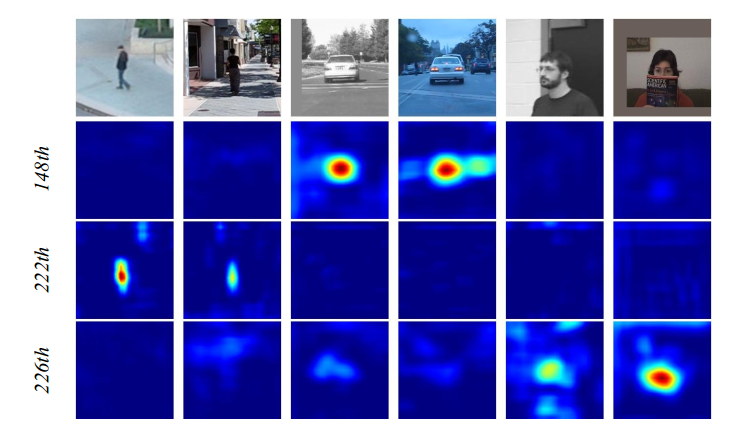
另一个有意思的现象是:the objects in the same category have high response on same channels, while response of the rest channels are supressed。也就是说,同一类的物体在同一个 channel 上,都有较高的响应,而其他的 channels 上则被抑制。如下图所示:
6. Experimental Results:

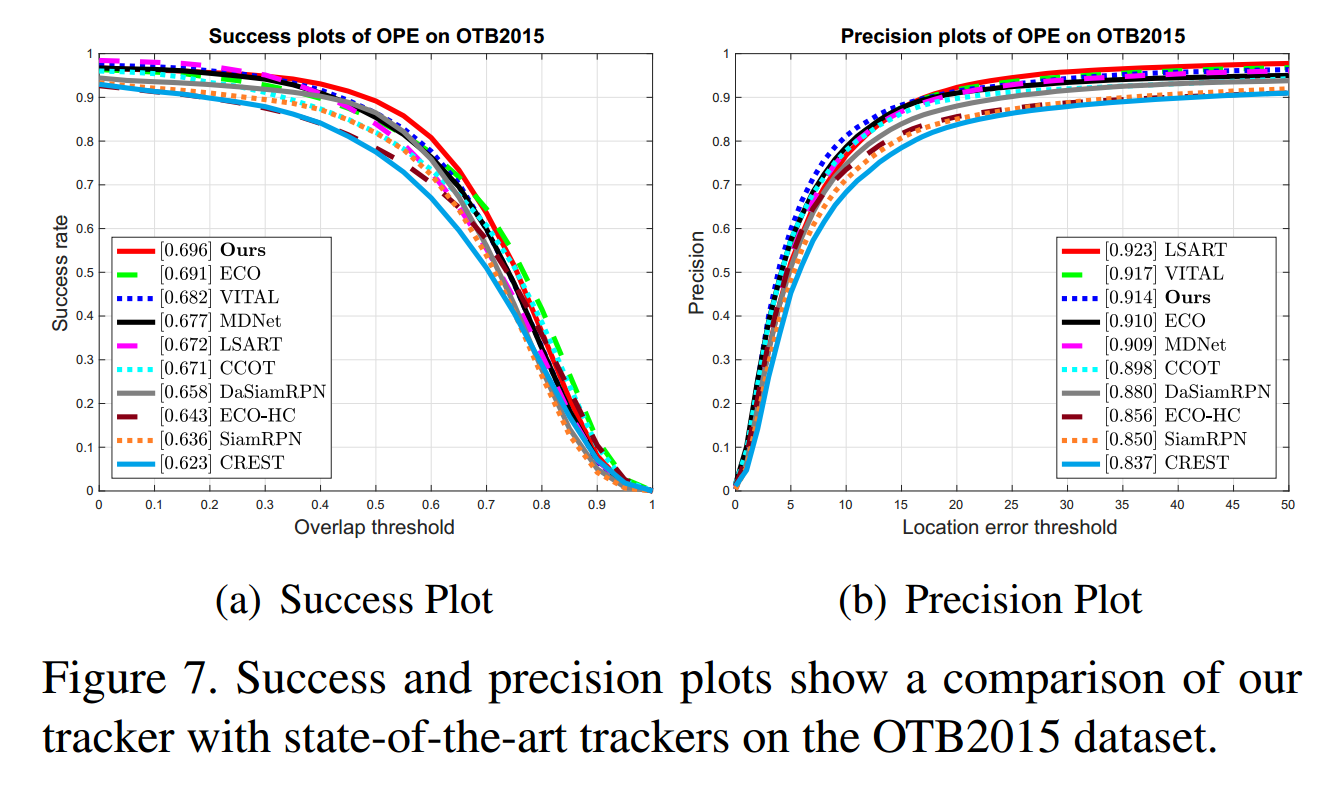
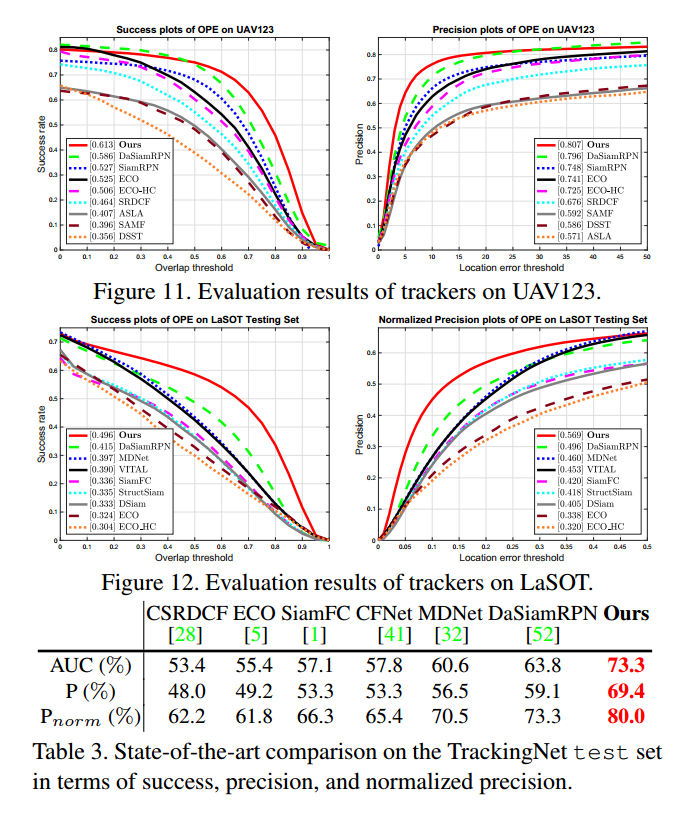
==

 浙公网安备 33010602011771号
浙公网安备 33010602011771号