RCNN + Fast RCNN + Faster RCNN
图像分类 图像定位 目标检测 和 实例分割

目标检测的发展历程(论文时间)

图片来自https://github.com/hoya012/deep_learning_object_detection#2014
相关链接https://blog.csdn.net/C_chuxin/article/details/82828439
RCNN(Regions with CNN) 是将CNN引入目标检测的开山之作

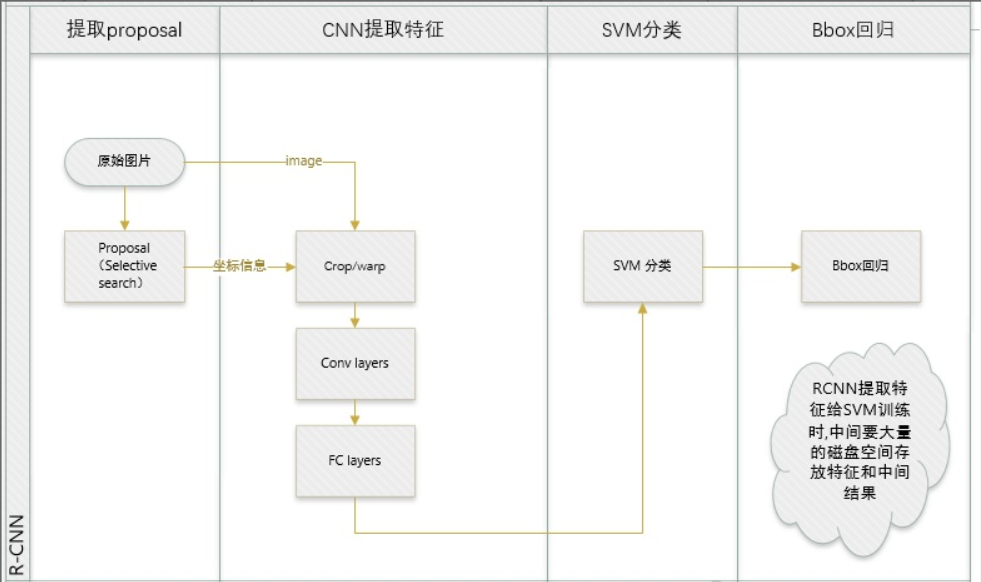
RCNN 主要分为四步
- 采用SelectiveSearch方法生成候选区域(region proposals), 每张图片1K~2K个候选区域
- 提取特征,每个区域都采用CNN(AlexNet)进行特征提取,需要resize(各向异性缩放 p=16)
- 判断类别,每个区域提取特征送入不同的SVM分类器,判断是否属于该类
- 位置修正,采用回归器修正候选框位置 线性回归
![]()
为什么在CNN后采用SVM进行分类,而不用原有的SoftMax?
- 这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNN softmax输出比采用svm精度还低
R-CNN 缺点
- 需要事先提取多个候选区域对应的图像。这一行为会占用大量的磁盘空间
- 候选区域(region proposal)归一化过程中对图片产生的形变会导致图片大小改变,不利于CNN的特征提取
- 每个候选区域(region proposal)都需要进入CNN网络计算,进而会导致过多次的重复的相同的特征提取,这一举动会导致计算浪费
【文章参考】
- https://zhuanlan.zhihu.com/p/23006190?refer=xiaoleimlnote
- https://blog.csdn.net/WoPawn/article/details/52133338
- https://blog.csdn.net/gentelyang/article/details/80469553
Fast R-CNN
Fast R-CNN 主要在SSP-Net上改进
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算
- 用ROI pooling进行特征的尺寸变换,
- 将regressor放进网络一起训练,每个类别对应一个regressor,同时用softmax代替原来的SVM分类器
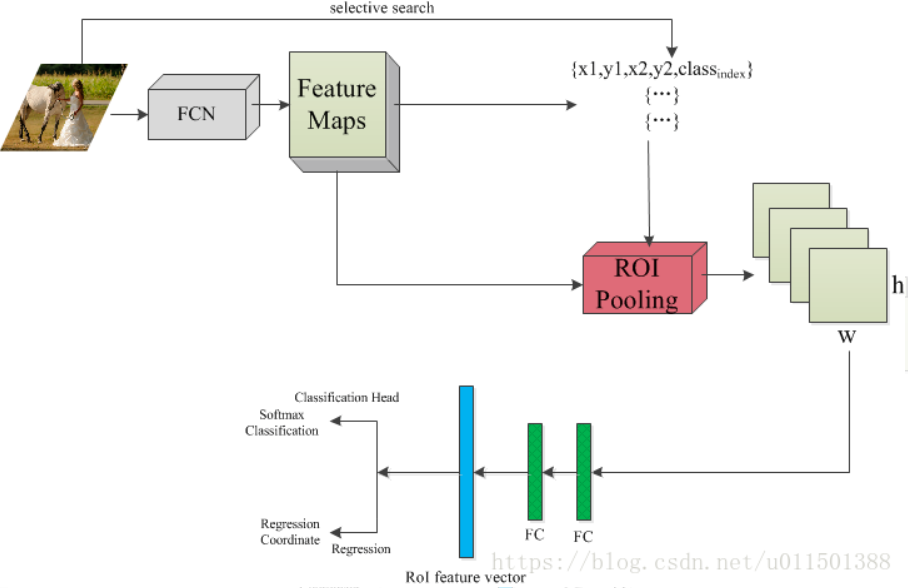
- 从上图可以看出,输入的图片会分成两路,一路进行FCN全卷积(基于VGG16)生成feature map ,一路和RCNN一样利用SS选取region proposals,两者一起进入ROI pooling,这里需要将region proposals的尺度转换成feature map的大小。之后进去两层全连接,之后进入分类层和定位层
【参考文章】
- https://blog.csdn.net/u011501388/article/details/81031780
- https://blog.csdn.net/donkey_1993/article/details/81904726
mAP(Mean Average Precision)
Faster R-CNN
Faster R-CNN 在fast R-CNN上的改进 faster R-CNN=RPN+fast R-CNN
- 改进region proposal候选区域的选取方式,产生 RPN层(区域生成网络Region Proposal Networks)
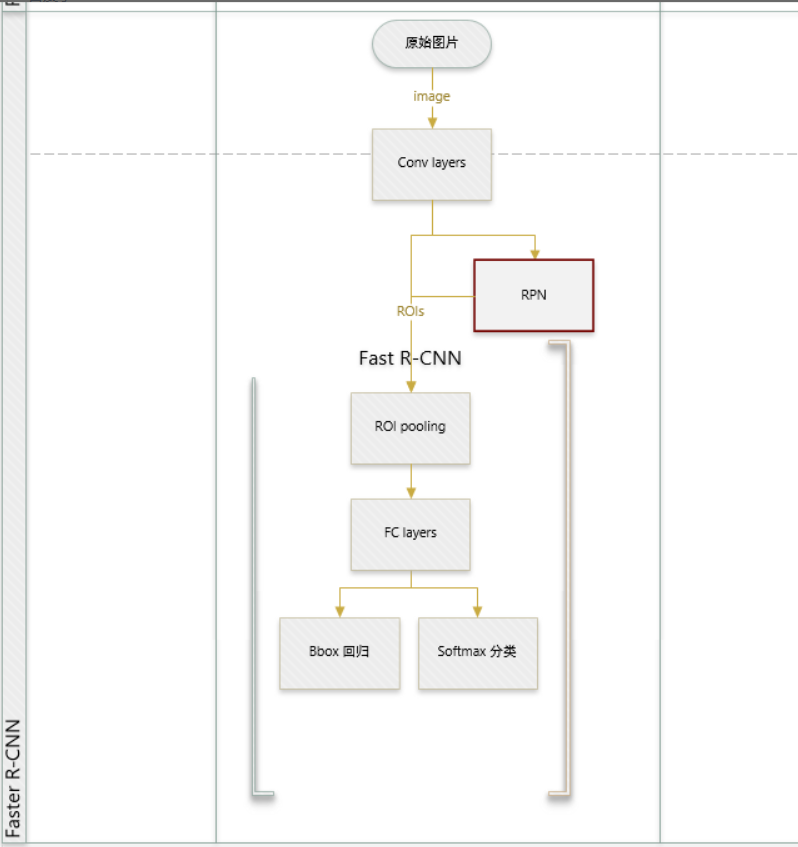
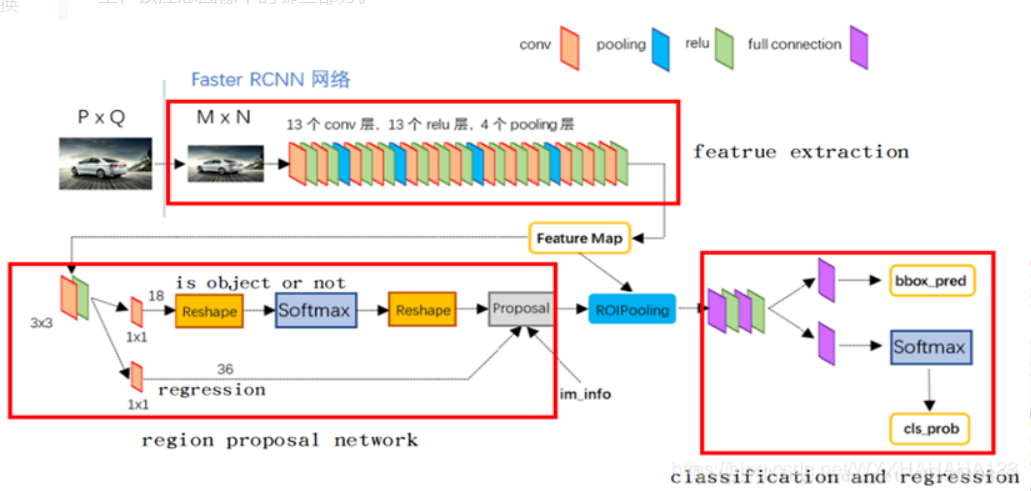
RPN详细理解
- 首先将卷积后的特征图
feature map映射回原始图像, 每个映射都对应不同尺度窗口bounding box - 根据
bbox与真实框ground truth的交并比IOU,给bbox标记正负样本标签
【参考文章】
posted on 2020-07-17 17:49 wangxiaobei2019 阅读(248) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号