pytorch_5.6 AlexNet
深度卷积神经网络 AlexNet
- 网络层数 8层 5个卷积层 3个全连接层
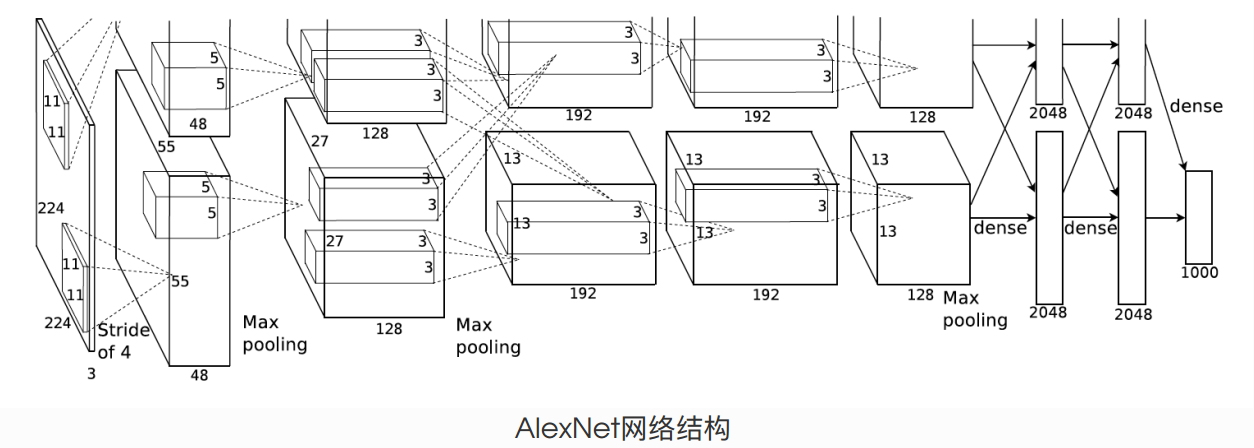
C1 卷积层 (卷积 -> Relu -> 池化 )
-
卷积
- input 227x227x3 这里的输入应该是227x227
- kernel size 11x11x3
- 卷积核种类 96
- stride = 4
- feature map 54x54x96
- padding = 0
$\color{red}{【如何计算输出大小】}$
- wide = (227 + 2 * padding - kernel_size) / stride + 1 = 55
- height = (227 + 2 * padding - kernel_size) / stride + 1 = 55
-
Relu 将卷积层输出的FeatureMap输入到ReLU函数中
-
Pool
- pool size = 3x3
- stride = 2
- feature map 27x27x96
$\color{red}{【计算方式】}$ (55−3)/2+1=27
C2 卷积层 (卷积 -> Relu -> 池化 )
-
卷积
- input 27x27x48 x 2 2是代表两组
- kernel size 5x5x48
- 卷积核种类 128
- stride = 1
- feature map 27x27x128 x 2
- padding = 2
$\color{red}{【如何计算输出大小】}$
- wide = height = (27+2∗2−5)/1+1=27
-
Relu 将卷积层输出的FeatureMap输入到ReLU函数中
-
Pool
- pool size = 3x3
- stride = 2
- feature map 13x13x256
$\color{red}{【计算方式】}$ (27−3)/2+1=13
C3 卷积层 (卷积 -> Relu)
-
卷积
- input 13x13x256
- kernel size 3x3x256
- 卷积核种类 384
- stride = 1
- feature map 13x13x384
- padding = 1
-
Relu 将卷积层输出的FeatureMap输入到ReLU函数中
C4 卷积层 (卷积 -> Relu)
-
卷积
- input 13x13x384
- kernel size 3x3x384
- 卷积核种类 384
- stride = 1
- feature map 13x13x384
- padding = 1
-
Relu 将卷积层输出的FeatureMap输入到ReLU函数中
C5 卷积层 (卷积 -> Relu -> 池化)
-
卷积
- input 13x13x384
- kernel size 3x3x256
- 卷积核种类 256
- stride = 1
- feature map 13x13x256
- padding = 1
-
Relu 将卷积层输出的FeatureMap输入到ReLU函数中
-
Pool
- pool size = 3x3
- stride = 2
- feature map 6x6x256
FC6 全连接层 [(卷积)全连接 -->ReLU -->Dropout]
- 卷积->全连接
- input 6x6x256
- kernel 6x6x256
- 卷积核种类 4096
- stride = 1
- feature map 4096×1×1
- Relu 4096个神经元
- Dropout 抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
FC7 全连接层 (全连接 -->ReLU -->Dropout)
- 全连接 input 4096 个向量
- Relu 4096个神经元
- Dropout 抑制过拟合,随机的断开某些神经元的连接或者是不激活某些神经元
输出层
- 第七层输出的4096个数据与第八层的1000个神经元进行全连接,经过训练后输出1000个float型的值,这就是预测结果
AlexNet参数数量
卷积层的参数 = 卷积核的数量 * 卷积核 + 偏置
- C1: 96个11×11×3的卷积核,96×11×11×3+96=34848
- C2: 2组,每组128个5×5×48的卷积核,(128×5×5×48+128)×2=307456
- C3: 384个3×3×256的卷积核,3×3×256×384+384=885120
- C4: 2组,每组192个3×3×192的卷积核,(3×3×192×192+192)×2=663936
- C5: 2组,每组128个3×3×192的卷积核,(3×3×192×128+128)×2=442624
- FC6: 4096个6×6×256的卷积核,6×6×256×4096+4096=37752832
- FC7: 4096∗4096+4096=16781312
- output: 4096∗1000=4096000
利用pytorch 构建简单的AlexNet
import time
import torch
from torch import nn, optim
import torchvision
import pytorch_deep as pyd
device = torch.device('cuda' if torch.cuda.is_available() else'cpu')
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels,kernel_size, stride, padding
nn.ReLU(),
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减⼩卷积窗⼝,使⽤填充为2来使得输⼊与输出的⾼和宽⼀致,且增⼤输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使⽤更⼩的卷积窗⼝。除了最后的卷积层外,进⼀步增⼤了输出通道数。
# 前两个卷积层后不使⽤池化层来减⼩输⼊的⾼和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这⾥全连接层的输出个数⽐LeNet中的⼤数倍。使⽤丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这⾥使⽤Fashion-MNIST,所以⽤类别数为10,⽽⾮论⽂中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
net = AlexNet()
print(net)
AlexNet(
(conv): Sequential(
(0): Conv2d(1, 96, kernel_size=(11, 11), stride=(4, 4))
(1): ReLU()
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU()
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU()
(8): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU()
(10): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU()
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=6400, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
加载数据
def load_data_fashion_mnist(batch_size = 256,resize=None,num_workers = 0):
trans = []
if resize:
trans.append(torchvision.transforms.Resize(size=resize))
trans.append(torchvision.transforms.ToTensor())
transform = torchvision.transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root='./MNIST', train=True, download=True,
transform=transform)
mnist_test = torchvision.datasets.FashionMNIST(root='./MNIST', train=False, download=True,
transform=transform)
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
return train_iter,test_iter
batch_size = 128
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = load_data_fashion_mnist(batch_size,resize=224)
训练模型
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
pyd.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
training on cuda
epoch 1, loss 0.6022, train acc 0.773, test acc 0.858,time 60.7 sec
epoch 2, loss 0.1640, train acc 0.879, test acc 0.888,time 63.6 sec
epoch 3, loss 0.0958, train acc 0.893, test acc 0.895,time 63.5 sec
epoch 4, loss 0.0645, train acc 0.904, test acc 0.904,time 63.5 sec
epoch 5, loss 0.0470, train acc 0.912, test acc 0.906,time 63.9 sec
AlexNet 学习完毕
- 网络搭建
- 训练和测试
posted on 2020-07-17 15:44 wangxiaobei2019 阅读(228) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号