

pytorch_5.5 LeNet
5.5 LeNet最初是用来进行手写字体识别
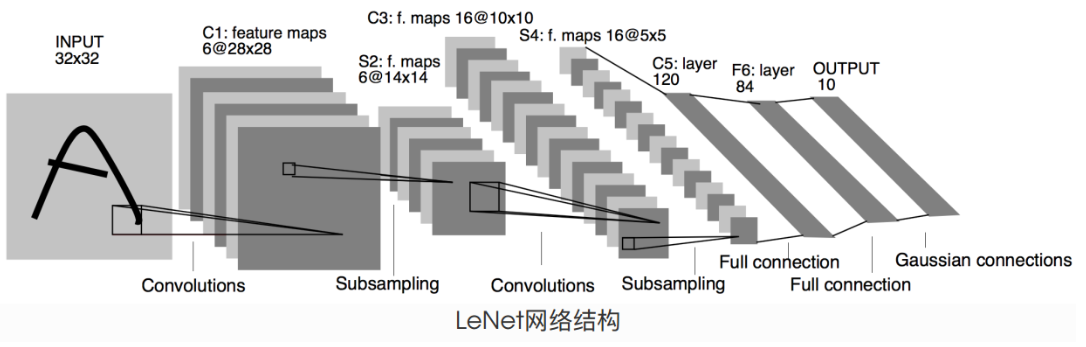
5.5.1 LeNet模型
C1 卷积层
- 输入图片 input 32 * 32
- 卷积核 kernel size 5 * 5
- 卷积核种类 6
- 输出feature_maps大小 28*28
- 神经元数量 28 * 28 * 6
- 可训练参数 (5 * 5 + 1)* 6 = 156
- 连接数 (5 * 5 + 1)* 6 * 28 * 28 = 122304
S2 池化层——下采样
- 输入 28 * 28
- 采样方式 2 * 2 最大池化
- 输出feature_maps大小 14 * 14
- 神经元数量 14 * 14 * 6
- 连接数 (2 * 2 + 1)* 6 * 14 * 14 = 5880
C3 卷积层 6层 ->16层
- 输入 14 * 14
- 卷积核 kernel_size 5 * 5
- 卷积核种类 16
- 输出feature maps 10 * 10
- 可训练参数 6x(3x5x5+1)+6 x (4x5x5+1)+3x(4x5x5+1)+1x(6x5x5+1)=1516
- 连接数 1516x10x10 = 151600
如何卷积成16层?
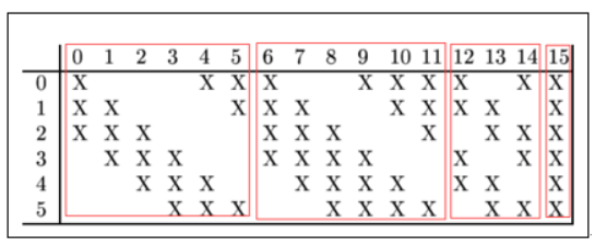
C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5x5,所以总共有6x(3x5x5+1)+6 x (4x5x5+1)+3x(4x5x5+1)+1x(6x5x5+1)=1516个参数。而图像大小为10x10,所以共有151600个连接。
S4 池化层——下采样
- 输入 10 * 10
- 采样方式 2 * 2 最大池化
- 输出feature_maps大小 5 * 5
- 神经元数量 5 * 5 * 16 = 400
- 连接数 (2 * 2 + 1)* 16 * 5 * 5 = 2000
C5 卷积层 16层 -> 120层
- 输入 5 * 5
- 卷积核 kernel size 5 * 5
- 卷积核种类 120
- 输出 feature map 1 * 1
- 可训练参数 / 连接数 (5 * 5 * 16 + 1)* 120 = 48120
F6 全连接层
-
输入:c5 120维向量
-
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
-
可训练参数:84*(120+1)=10164
F7 全连接层 输出层
- 输入 f6 84维向量
- 参数和连接 84 * 10 = 840
- 输出 10 分类
识别3的过程

【参考文章】
https://www.cnblogs.com/duanhx/articles/9655228.html
https://cuijiahua.com/blog/2018/01/dl_3.html
LeNet简单实现
import torch
from torch import nn,optim
import time
import pytorch_deep as pyd
# 设置GPU 选项
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
# 设置卷积层 nn.Conv2d(in_channels,out_channels,kernel size)
self.conv = nn.Sequential(
nn.Conv2d(1,6,5),
nn.Sigmoid(),
nn.MaxPool2d(2,2),
nn.Conv2d(6,16,5),
nn.Sigmoid(),
nn.MaxPool2d(2,2),
)
self.fc = nn.Sequential(
nn.Linear(16* 4*4,120), # 输入图像大小是28*28
nn.Sigmoid(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
def forward(self,img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0],-1))
return output
查看LeNet 网络结构
net = LeNet()
print(net)
LeNet(
(conv): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=256, out_features=120, bias=True)
(1): Sigmoid()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): Sigmoid()
(4): Linear(in_features=84, out_features=10, bias=True)
)
)
5.5.2 加载数据集 和 训练模型
- 数据集使用 Fashion-MNIST
batch_size = 256
train_iter, test_iter =pyd.load_data_fashion_mnist(batch_size=batch_size)
#本函数已保存在pytorch_deep包中⽅便以后使⽤
# 计算训练准确度
def evaluate_accuracy(data_iter, net, device= torch.device('cuda' if torch.cuda.is_available() else 'cpu')):
acc_sum,n = 0.0,0.0 #acc_sum 计算训练过程中模型输出结果与标签相同的数量
with torch.no_grad(): # torch.no_grad() 该作用域下 的计算不会被 track
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) ==y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else:print('error net')
n += y.shape[0]
return acc_sum / n
# 本函数已保存在pytorch_deep包中⽅便以后使⽤
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
## 损失函数 交叉熵损失
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0,time.time()
for X, y in train_iter:
X = X.to(device) # 数据放到GPU
y = y.to(device)
y_hat = net(X) #得到网络输出结果
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) ==y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f,time %.1f sec'%
(epoch + 1, train_l_sum / batch_count,train_acc_sum / n, test_acc, time.time() - start))
开始训练 并测试
- 学习率采用0.001 训练算法使用Adam
lr, num_epochs = 0.001, 20
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device,num_epochs)
training on cuda
epoch 1, loss 0.5772, train acc 0.774, test acc 0.774,time 4.2 sec
epoch 2, loss 0.2741, train acc 0.785, test acc 0.780,time 4.2 sec
epoch 3, loss 0.1745, train acc 0.794, test acc 0.789,time 4.4 sec
epoch 4, loss 0.1254, train acc 0.804, test acc 0.802,time 4.2 sec
epoch 5, loss 0.0966, train acc 0.814, test acc 0.808,time 4.3 sec
epoch 6, loss 0.0780, train acc 0.821, test acc 0.813,time 4.2 sec
epoch 7, loss 0.0646, train acc 0.830, test acc 0.821,time 4.3 sec
epoch 8, loss 0.0550, train acc 0.836, test acc 0.826,time 4.5 sec
epoch 9, loss 0.0476, train acc 0.841, test acc 0.829,time 4.2 sec
epoch 10, loss 0.0418, train acc 0.845, test acc 0.835,time 4.2 sec
epoch 11, loss 0.0371, train acc 0.850, test acc 0.838,time 4.2 sec
epoch 12, loss 0.0334, train acc 0.851, test acc 0.843,time 4.3 sec
epoch 13, loss 0.0300, train acc 0.857, test acc 0.847,time 4.4 sec
epoch 14, loss 0.0273, train acc 0.859, test acc 0.849,time 4.5 sec
epoch 15, loss 0.0250, train acc 0.862, test acc 0.850,time 4.2 sec
epoch 16, loss 0.0230, train acc 0.864, test acc 0.853,time 4.3 sec
epoch 17, loss 0.0213, train acc 0.867, test acc 0.849,time 4.3 sec
epoch 18, loss 0.0197, train acc 0.869, test acc 0.860,time 4.3 sec
epoch 19, loss 0.0184, train acc 0.871, test acc 0.861,time 4.3 sec
epoch 20, loss 0.0172, train acc 0.872, test acc 0.862,time 4.4 sec
LeNet 学习完毕
- 基本的网络结构
- 网络的搭建
- 模型的训练与测试

posted on 2020-07-17 15:38 wangxiaobei2019 阅读(226) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界