
得分函数;损失函数;正则化;过拟合、泛化能力;softmax分类器;激励函数;梯度下降;后向传播
1、得分函数
线性分类器:在坐标系上就是一直线,大于它就是1,小于它就是0。
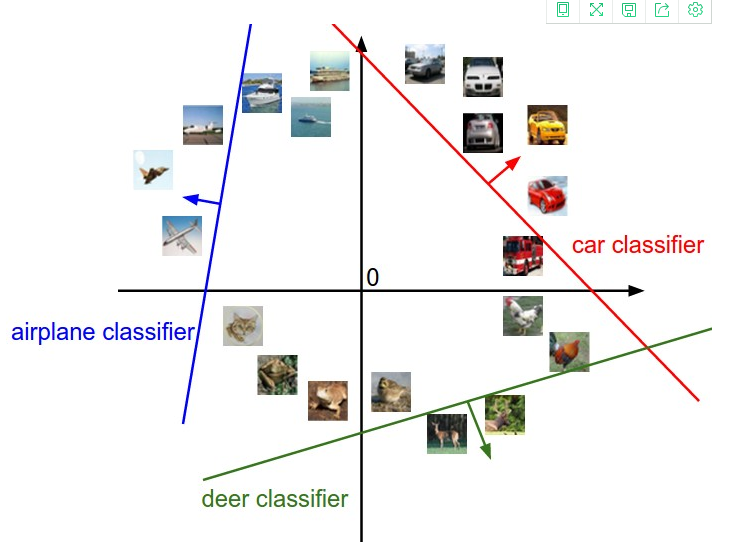
一张图假设是32*32*3的像素矩阵,首先把它平展为3072*1的向量,如果最后结果只能是10个类别。那么得分函数结果将是10*1的向量。w将是10*3072的矩阵,b是10*1的向量。
意思就是,这张图通过计算,属于这一类的得分是多少。

2、损失函数
得分函数结束后,每一个类都有得分。将这些预测结果和实际的结果求出一个偏差,来表明预测的准确性。
1)多类别支持向量机损失/Multiclass Support Vector Machine loss
正确的类别结果获得的得分比不正确的类别,至少要高上一个固定的大小Δ。类得分结果f(xi,W),其中第j类得分我们记作f(xi,W)j,该图片的实际类别为yi。就是每个类的得分-实际类的得分+Δ,再和0取最大值。
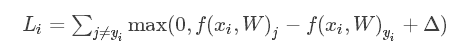
3、正则化
损失函数存在一弊端,
假设存在一组w使得一个类减去实际类的得分小于10,则一定存在一组γ*w使得其得分大于10。所以要加上一个正则项,在下方式中,是把所有W的元素的平方项求和
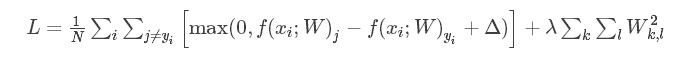
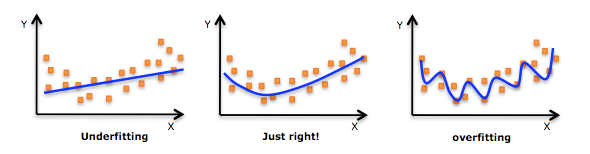
4、过拟合(overfitting)、泛化能力
泛化能力:用来表征学习模型对于未知数据的预测能力。
过拟合:在学习模型的时候,一味的最小化训练误差,所选的模型的复杂度可能会很高,这种现象称为过拟合。出现过拟合的原因是因为训练集中的数据本身就存在有噪声,一味的追求训练误差的最小化,会导致对未知数据的预测能力降低。
避免过拟合的方法有很多:early stopping、数据集扩增(Data augmentation)、正则化(Regularization)包括L1、L2(L2 regularization也叫weight decay),dropout。
5、softmax分类器
有两种特别常见的分类器,SVM是其中的一种,而另外一种就是Softmax分类器。
做的事情就是把一列原始的类别得分归一化到一列和为1的正数表示概率。

6、激励函数
每一次输入和权重w线性组合之后,都会通过一个激励函数(也可以叫做非线性激励函数),经非线性变换后输出。
7、梯度下降
实际是反向传播的机制,目的是找到能让损失函数最小的参数W。
给损失函数求导,也就是梯度,实际是损失函数变化率最快的方向。
梯度的方向是函数增大方向,负梯度才是下降方向。
步长,也叫学习率。
计算得到梯度之后,使用梯度去更新已有权重参数的过程叫做『梯度下降』。
8、后向传播
BP(backpropgationalgorithm ):后向传导算法,顾名思义就是从神经网络的输出(顶层)到输入(底层)进行求解
根据误差信号修正每层的权重

 浙公网安备 33010602011771号
浙公网安备 33010602011771号