
性能测试(二)
一、性能测试的方法
1、负载测试
在被测系统上持续不断的增加压力,直到性能指标(响应时间等)超过预定指标或者某种资源(CPU&内存)使用已达到饱和状态。核心是找到系统的处理极限,为系统调优提供数据,从而达到了解系统性能的容量。
目的:
a、验证服务被部署的系统出现资源瓶颈的时候,服务依然能够提供产品的特性;
b、找到系统的最大饱和状态,或者是最大的处理极限,为系统后续的容量规划提供参考的数据。
2、验收负载测试
在QA(Quality Assurance)的环境模拟生产运行的业务压力和使用场景组合,测试系统的性能是否满足生产环境的性能诉求。
流量回放: 获取生产环境的网络请求,拿到QA的环境执行,方便测试进行测试的时候,测试模拟的环境和生产环境更加逼真。
3、压力测试
该方法是指系统在一定饱和状态下,具体如CPU,内存等饱和使用的情况下,系统能够处理的会话能力,以及系统是否会出现错误,比如TimeOut、OOM、OverStackExpection(堆栈异常)。压力测试的特点:
• 检查系统在处于压力情况下时应用的性能表现
• 等价于负载测试,使系统的资源处于一个瓶颈的状态(建议CPU和内存在75%以上)
• 这种方式一般用于测试系统的稳定性
4、稳定性测试
指的是系统在最大的极限下,依然能够正常的访问,不会对客户造成任何的影响。
5、可靠性测试
给系统加载一定的业务压力,让应用持续运行一段时间,测试系统在这种条件下是否能稳定运行。
6、配置测试
被测环境软硬件环境参数的调整,达到最优的分配原则。
配置测试需要考虑的点:
JVM:CPU,内存
MySQL:连接数,超时参数
操作系统监控:CPU和内存 使用率达到多少的时候触发报警机制。
达到一个好的系统的表现:服务在客户端高并发的情况下依然能够正常的为客户提供业务的能力和服务。

😃高并发情况下会出现如下情况:
a、线程同步:A和B两个线程,在同一时间发送请求的时候,当A线程在对内存进行操作时,B线程都不可以对这个内存地址进行操作,直到A线程完成操作, B线程才能对该内存地址进行操作。
b、死锁:两个程序都在等待彼此先完成,从而导致程序的停滞状态。比如,A线程占有1号锁,正在等待2号锁,而B线程占有2号锁,正在等待1号锁,A和B都在等待双方释放锁,进入无限的等待状态
业务场景:在文件读写的时候特别容易发生。
二、性能测试实战
1、JMeter执行原理
JMerer通过线程组来驱动多个(也可以理解为LR工具里面的虚拟用户)运行测试脚本对目标服务器发起大量的网络请求,在每个客户端上可以运行多个线程组,也就是说⼀个测试计划里面可以包含N个线程组。
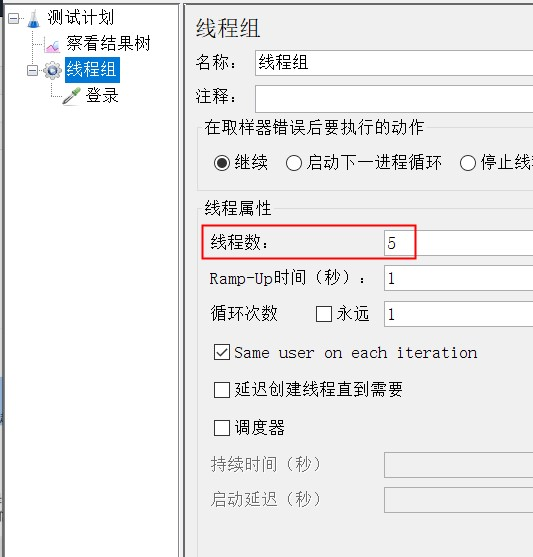
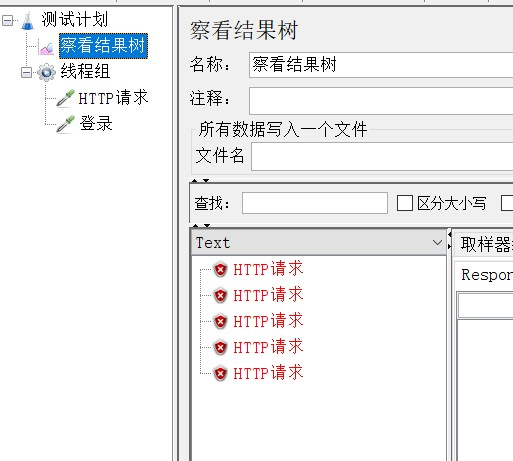
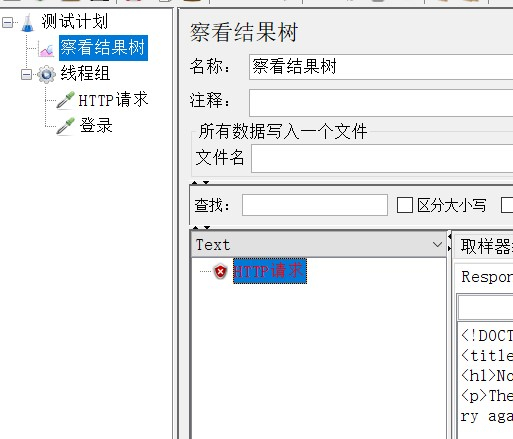
比如:以某一平台的登录为例,进行如下操作:让5个虚拟用户同时访问登录界面:
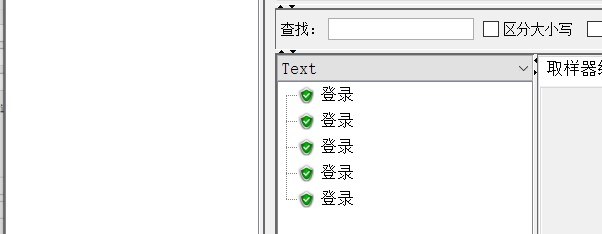
运行jmeter结果树,查看访问结果:
2、场景设置
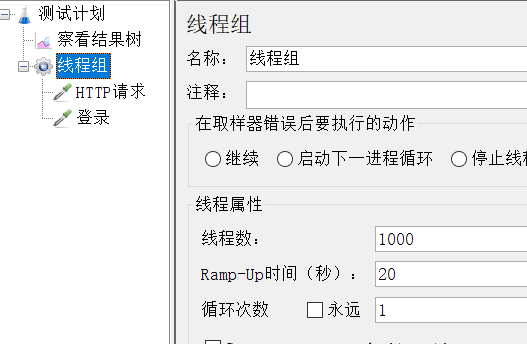
在JMeter的测试工具中,依据业务的形态来设置它的目录结果,但是设置性能测试的场景,主要是在线程组中来进行设置。JMeter的线程组可以理解为是建立了⼀个线程池,在执行的过程中处理线程组里面的各个业务逻辑,线程组的信息具体如下:
2-1、取样器错误后要执行的动作

2-2、线程属性
2-2-1、线程数
一个线程可以理解为对应模拟一个用户,所以线程数越多,那么也就认为可以模拟的用户数越多。
2-2-2、Ramp-Up时间(秒) 该属性指的是所有线程从启动到开始运行的时间间隔,单位是秒,也就是说所有线程在多长时间内开始执行,如线程数设置50,设置的时间为5秒,那么计算的公式为:

设置虚拟用户数是:1000,每秒并发50个用户,Ramp-Up:1000/50=20s
2-2-3、循环次数
循环次数可以理解为,请求的重复次数。如果选择“永远”,那么请求将⼀直进行,不建议这样操作,可以进行稳定性的测试。
2-2-4、调度器
首先,我们知道在性能测试中,测试系统的稳定性的时候,需要持续运行业务一段时间,通过综合分析执行指标和资源监控指标,来确定系统处理最大工作量强度性能的过程。所以,这个稳定性测试方案,在jmeter上通过调度器的设置来实现的。
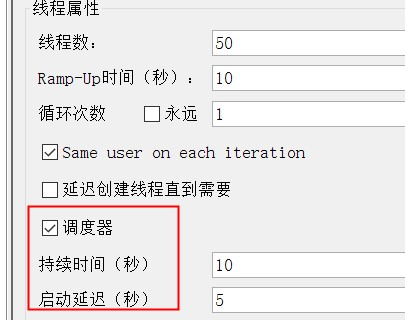
其次,说下调度器配置。
要让调度器成功运行,循环次数必须勾选永远,否则按照具体的循环次数执行。
勾选调度器之后:
2-2-4-1、持续时间
测试计划持续多长时间:从开始运行到结束的时间总和,即就是持续运行的时间。
2-2-4-2、启动延迟
从当前时间延迟多长时间开始运行测试,也就是说点击执行后,仅仅是做初始化的场景,不会执行测试,等待延迟到达后开始运行测试,执行的时间为持续时间设置的时间。
举例1:假设总的线程数(虚拟用户数)是50个,每秒启动5个用户,Ramp-Up:50/5=10s,并发测试50个用户(假设启动延迟10s,此时10秒就会加载完所有用户,然后同时执行)
举例2:假设总的线程数(虚拟用户数)是50个,每秒启动5个用户,Ramp-Up:50/5=10s,并发测试25个用户(假设启动延迟5s,此时5秒就会加载完25个用户,然后让这25个用户同时执行,剩下的25个用户,每秒启动5个用户,用5秒完成)
举例3:假设有25名运动员(虚拟用户数)进行田径比赛,每个跑道要放5名运动员(每秒启动5个用户),总共会有25/5=5个跑道(Ramp-Up:5s),并发测试25个运动员(假设启动延迟5s,此时5秒就会让所有的运动员处于起跑线上,然后同时执行)
3、JMeter监听器
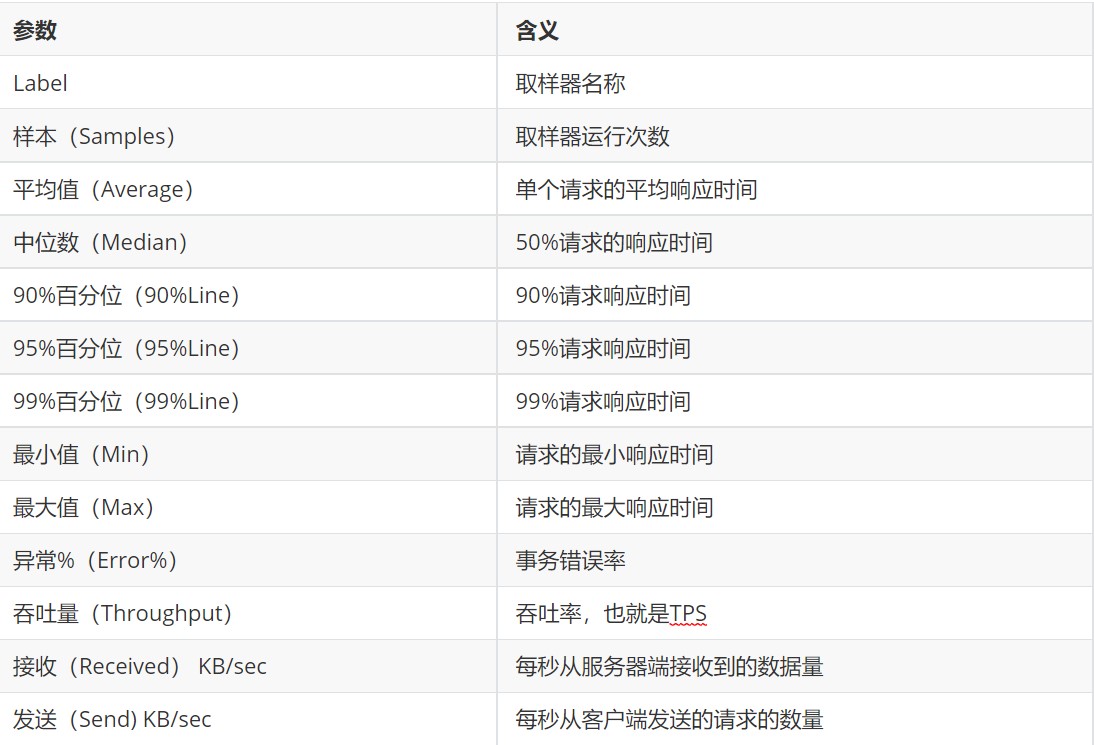
3-1、聚合报告
位置:添加→监听器→聚合报告

聚合报告参数:
😃不加上调度器设置和加上调度器设置:
不加调度器设置:

加上调度器设置:

会发现:加上调度器设置后,吞吐量会增加。
说明:系统的吞吐量越大,在一定程度上可以说明系统的稳定性比较好。
注意:每秒模拟的用户数,并不一定就是吞吐量数,这中间会涉及一些算法调度。
3-2、汇总报告
位置:添加→监听器→汇总报告
![]()
汇总报告参数:
汇总报告比聚合报告多了一个标准偏差和平均字节数。

标准偏差(SD):标准偏差提供了一定程度的稳定性,但是标准偏差不会显示最慢和最快的响应,而是有助于识别响应趋势。
😃当模拟用户数增加时,吞吐量会变高并且标准差会变低:
当模拟用户数是:50个,Ramp-Up:10s
![]()
当模拟用户数是:100个,Ramp-Up:10s

会发现:吞吐量越高,标准偏差越低,意味着系统内的性能更稳定或更一致。
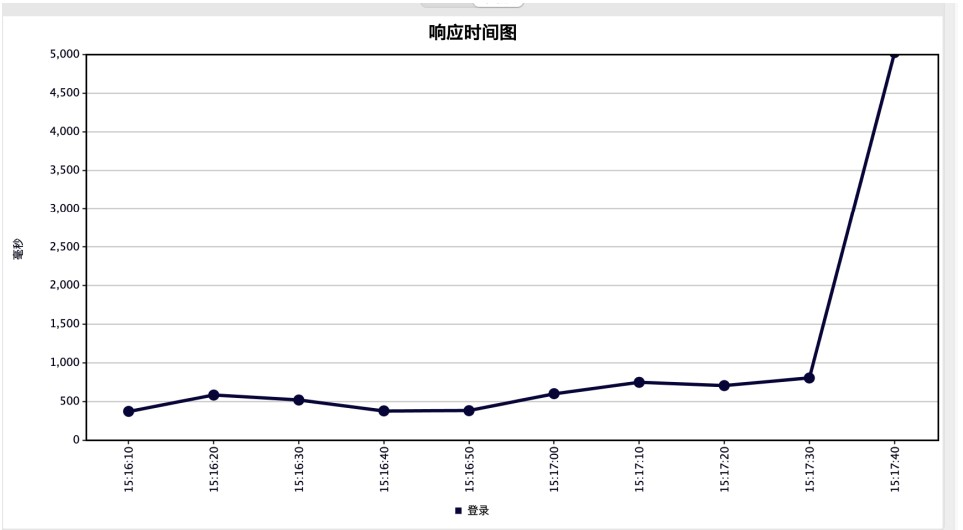
位置:添加→监听器→响应时间图
响应时间趋势图反馈的是请求的时间趋势图,具体如下:
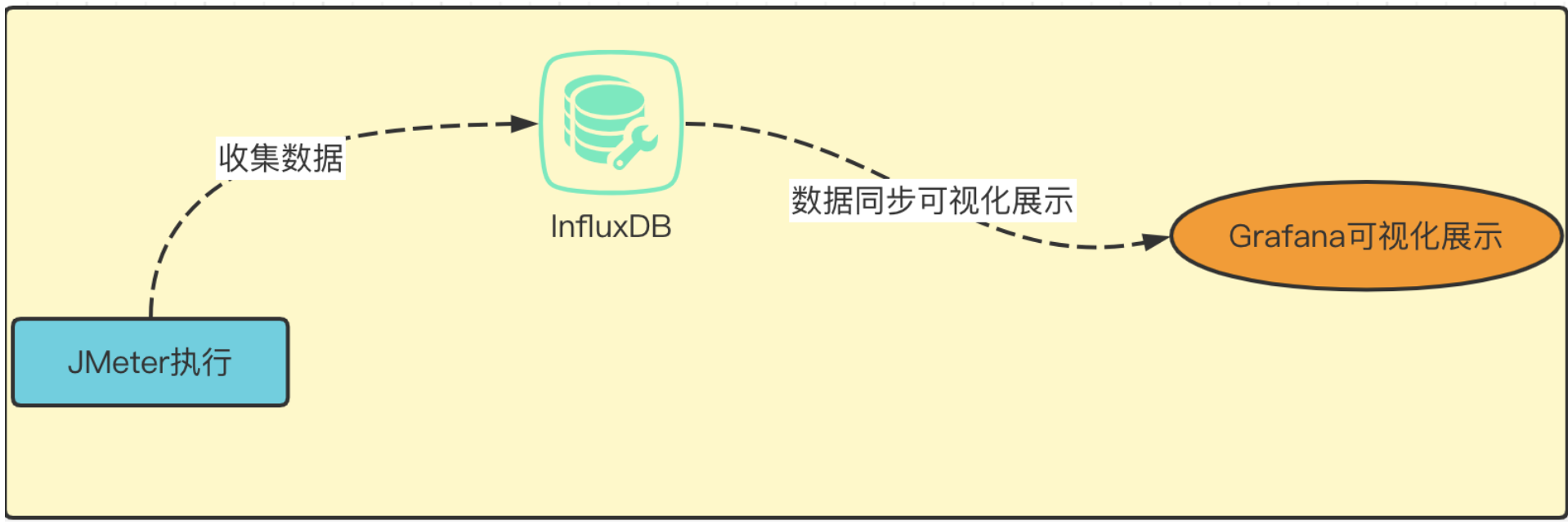
3-4、后端监听器
位置:添加→监听器→后端监听器
后端监听器可以把JMeter与influxdb,grafana整合起来,把性能测试过程中的数据存储到influxdb,然后最后显示在grafana的可视化界面中。
三、参数化
参数化:相同的测试步骤,不同的测试数据,那么这个时候我们把测试的数据分离到文件中,在JMeter中,是通过CSV数据文件设置来实现的。
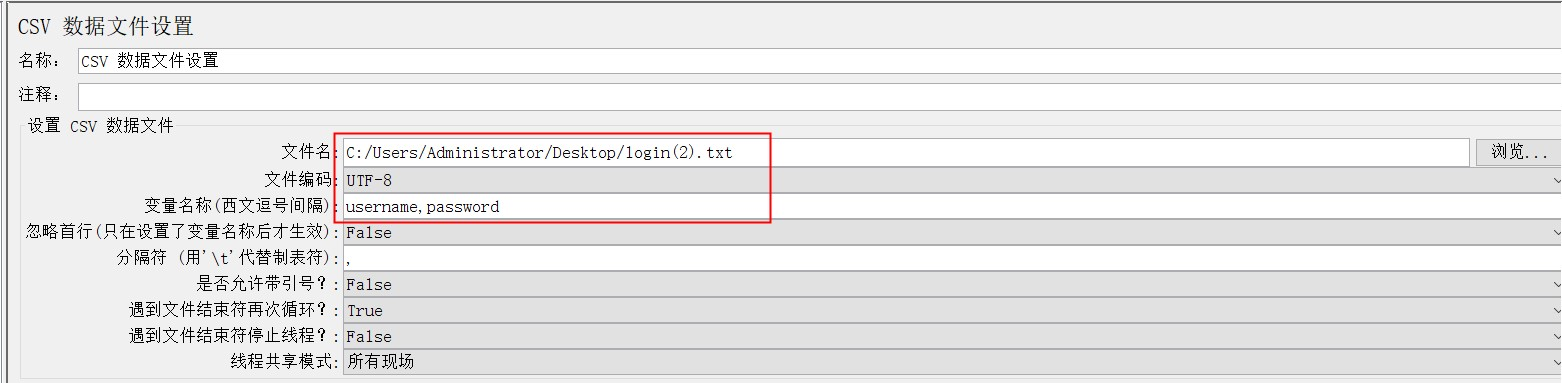
其中:CSV数据文件设置
位置:添加→ 配置元件 →CSV Data Set Config
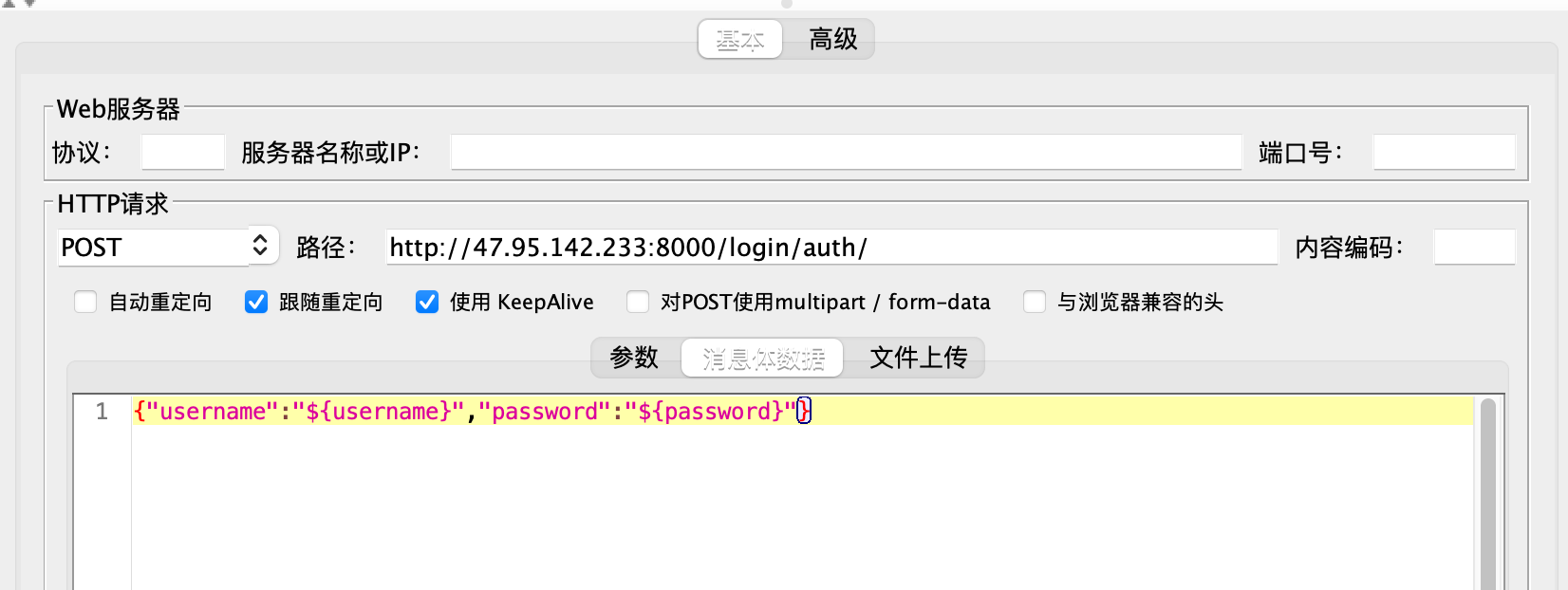
引用方式:${变量名}
局限性:需要手动进行测试数据的设置
1、以 .txt后缀文件样式来实现参数化,步骤如下:
step1:在登录的时候,每次都会有不同的客户进行过访问,因而也就会有不同的账户和密码,假设登录的账户和密码如下:这里的用户是6个
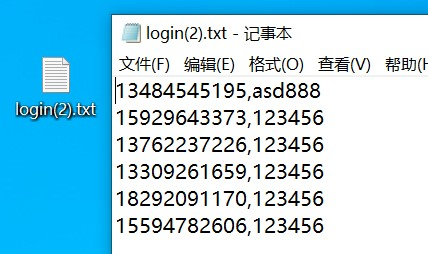
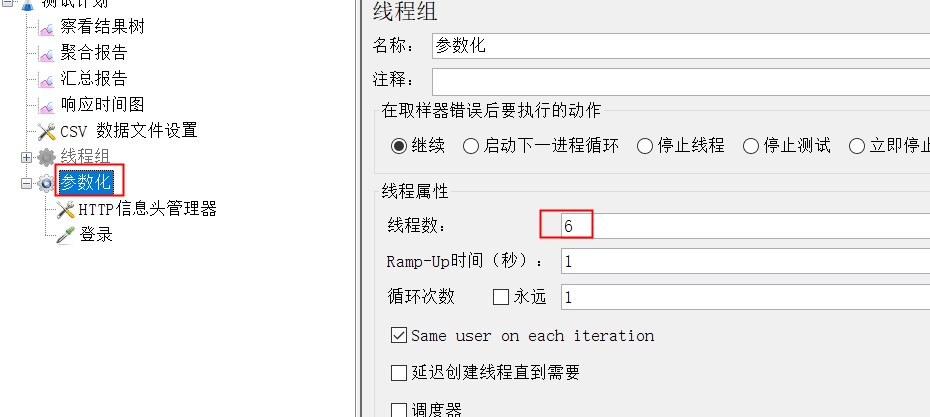
step2:创建名为“参数化”的线程组,名为“登录”的http请求、Http信息头管理器,CSV数据文件设置、结果树和更改线程数。
更改线程数为6:
CSV数据文件设置:
step3:返回名为“登录”的http请求,设置动态参数:${定义变量}
step4:运行结果树,会出现6个不同的用户名的信息情况:
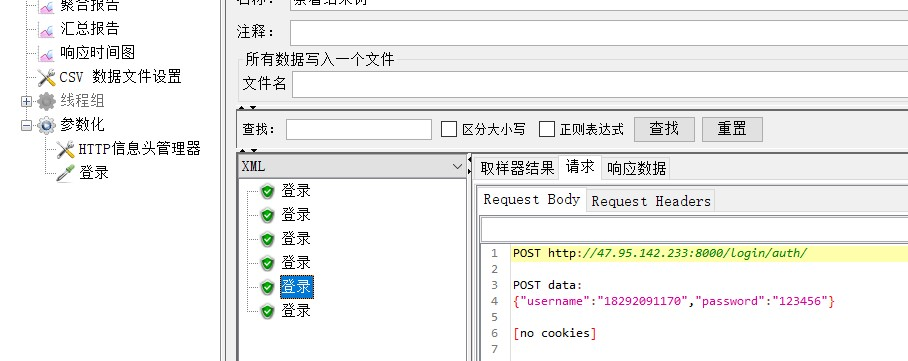
2、以 .csv后缀文件样式来实现参数化,步骤如下:
和上述的.txt文件操作一致
注意:在进行.csv为后缀的文件的编写的时候,在Excel书写的时候,另存为.csv为后缀的即可。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号