
UI自动化测试-selenium框架和iframe框架
一、自动化测试介绍
1、自动化测试:就是通过代码或者是工具模拟人的行为来对web(app)进行操作。
2、UI自动化测试的技术栈:
a、编程语言(oop)
b、单元测试框架UnitTest
c、数据驱动(测试的数据分离到文件中)
d、参数化
e、selenium WEB测试框架
f、页面对象设计模式
g、持续集成
二、Selenium环境部署
1、windows环境部署
step1:在之前我们安装Python的时候,已经在windows里配置了环境变量。如下图所示:

step2:到这里我们的配置环境就完成了,但是还是需要验证我们是否安装成功。按win+R,输入cmd,在运行框里,输入python,如下图所示:

step3:安装Selenium,重新按win+R,输入cmd,在运行框里,输入pip install selenium,如下图所示:
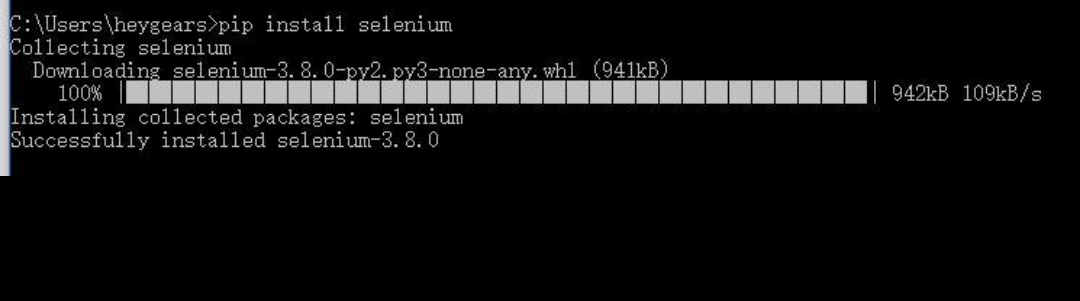
说明下载成功!
step4:驱动下载,我们以主流的Chrome浏览器为例,打开该浏览器,如下图所示:
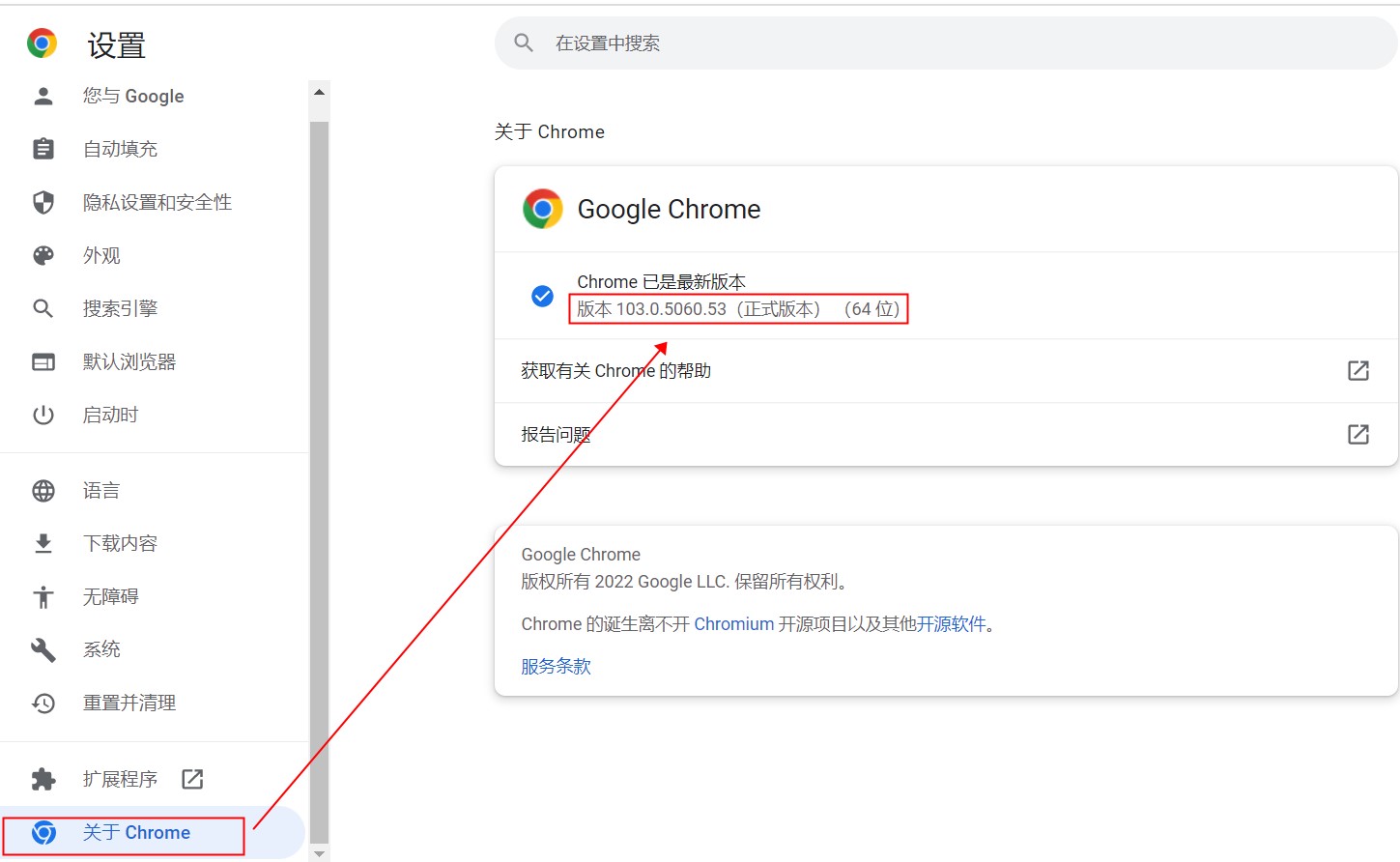
step5:查看Chrome浏览器的版本信息,如下图所示:
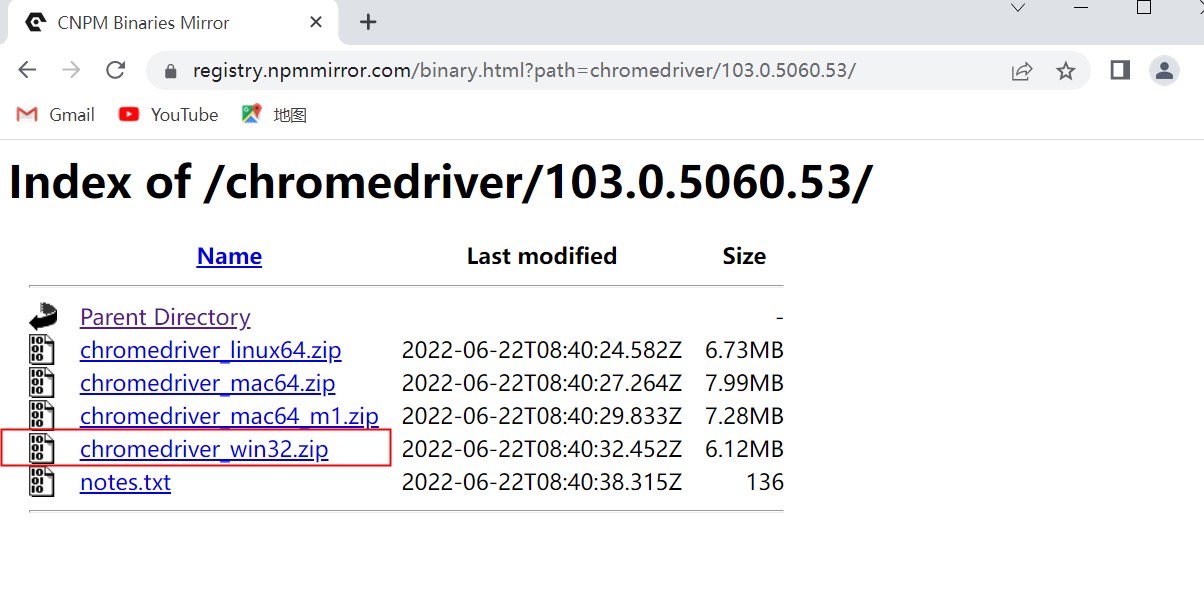
step6:driver的驱动要与浏览器的版本完全匹配(99%),下载网址为:打开网址下载符合我们浏览器的版本驱动,如下图所示:
step7:将下载好driver驱动应用程序放在python的安装目录下,如下图所示:
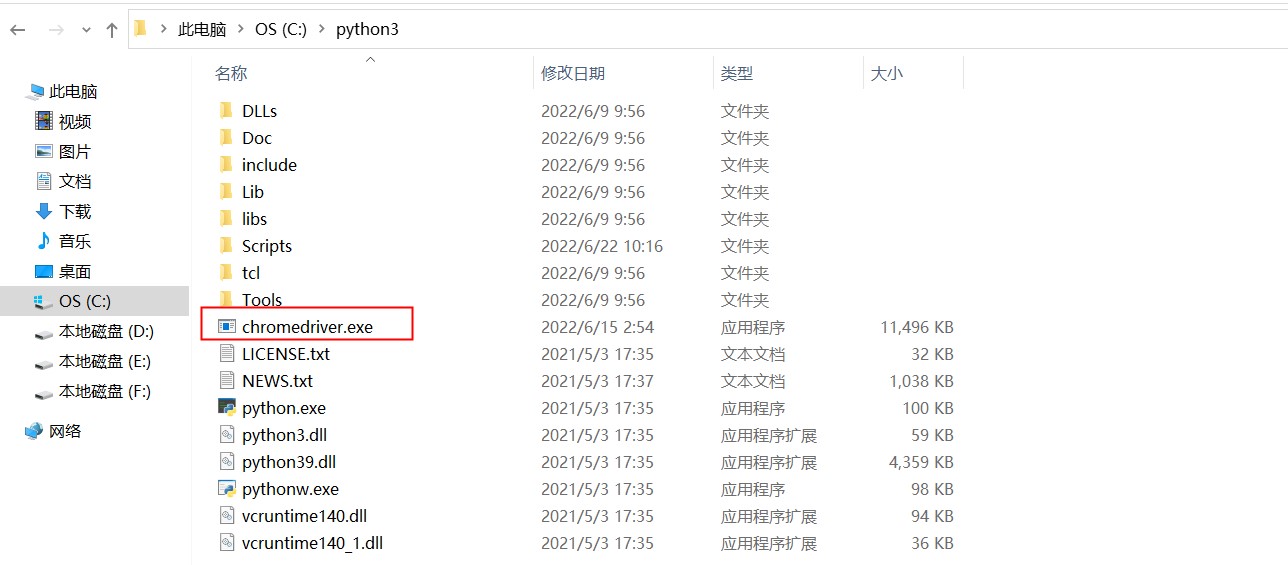
step8:接下来,测试Selenium是否可以启动Chrome浏览器,在PyCharm,输入如下代码:
1 from selenium import webdriver 2 import time as t 3 4 driver=webdriver.Chrome() 5 driver.get('http://www.baidu.com') 6 driver.find_element_by_id('kw').send_keys('Chrome浏览器') 7 t.sleep(3) 8 driver.quit()
运行结果如下:
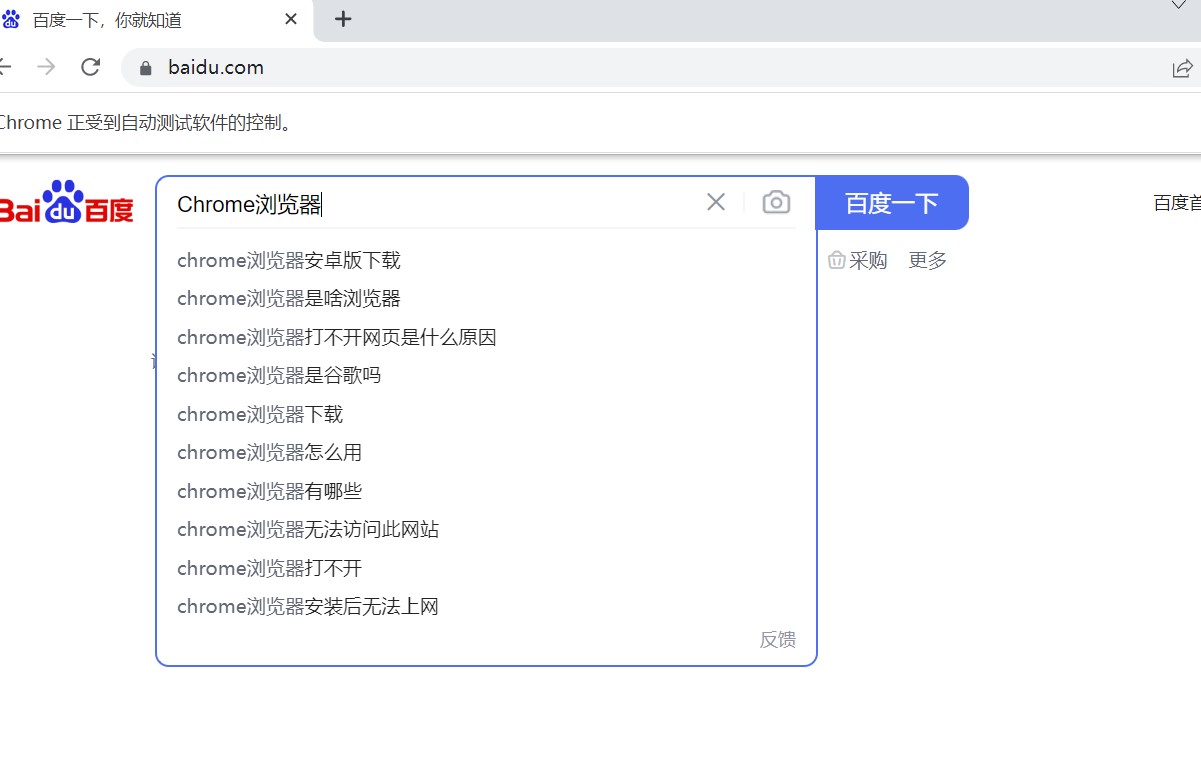
看到启动浏览器,我们就已经安装Selenium成功了!
三、Selenium的定位元素操作
1、元素定位从属性上来分
在selenium框架中,操作元素定位里面方法有8种,那么也就是说,定位页面的元素属性方法有8种,分别是:这8种名字一定要熟记+理解:
a:ID = "id" ,每个元素的ID是唯一性,不可重复的。
b:XPATH = "xpath"
c:LINK_TEXT = "link_text"
d:PARTIAL_LINK_TEXT = "partial_link_text"
e:NAME = "name"
f:TAG_NAME = "tag_name"
g:CLASS_NAME = "class_name"
h:CSS_SELECTOR = "css_selector"
我们以百度首页为例,其中我们要查看这8种属性的步骤是:打开百度首页,右击检查,如下图所示:
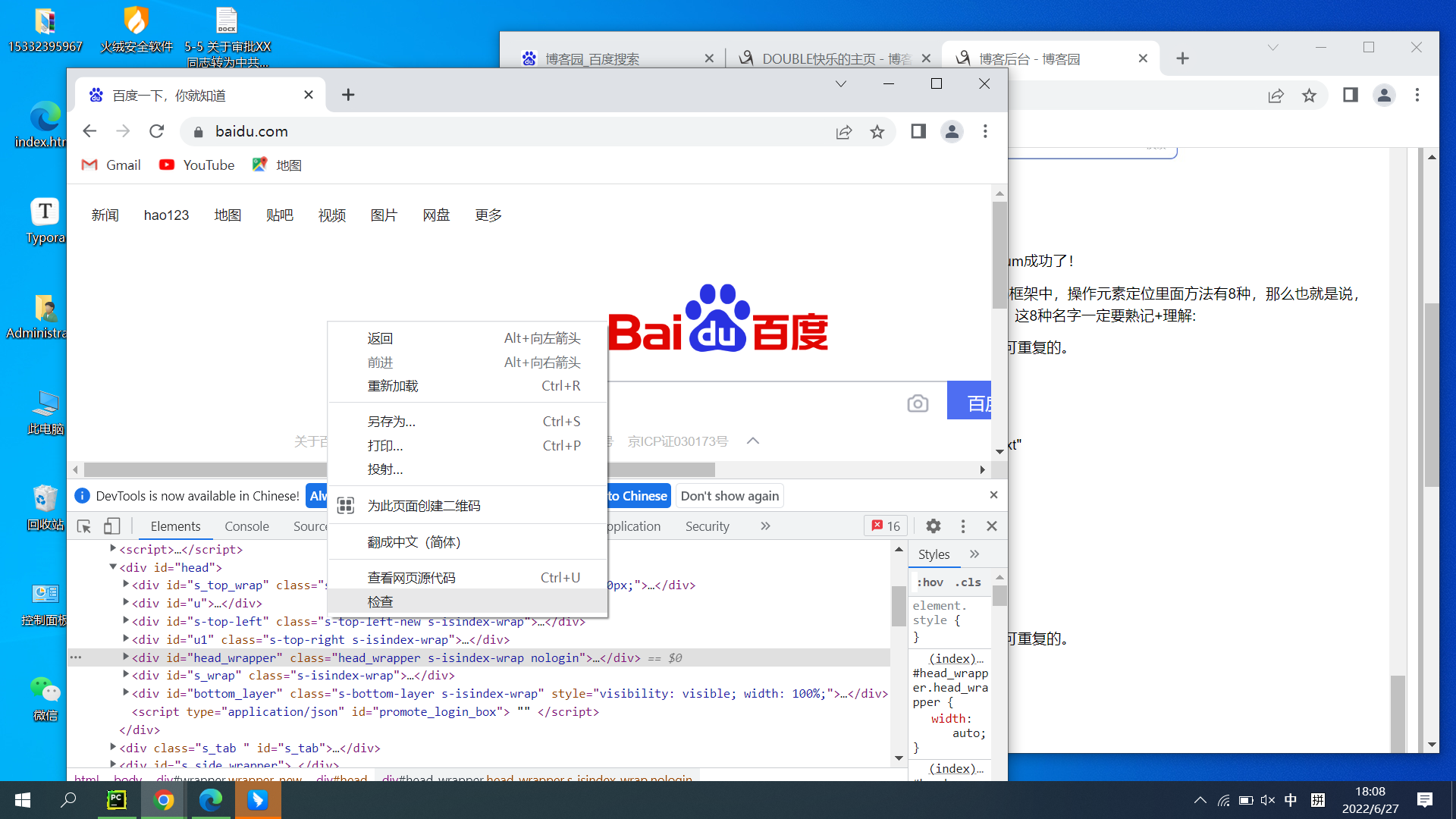
在这里我们可以查看id、name、class name、tag name、link text、partial link text,如下图所示:
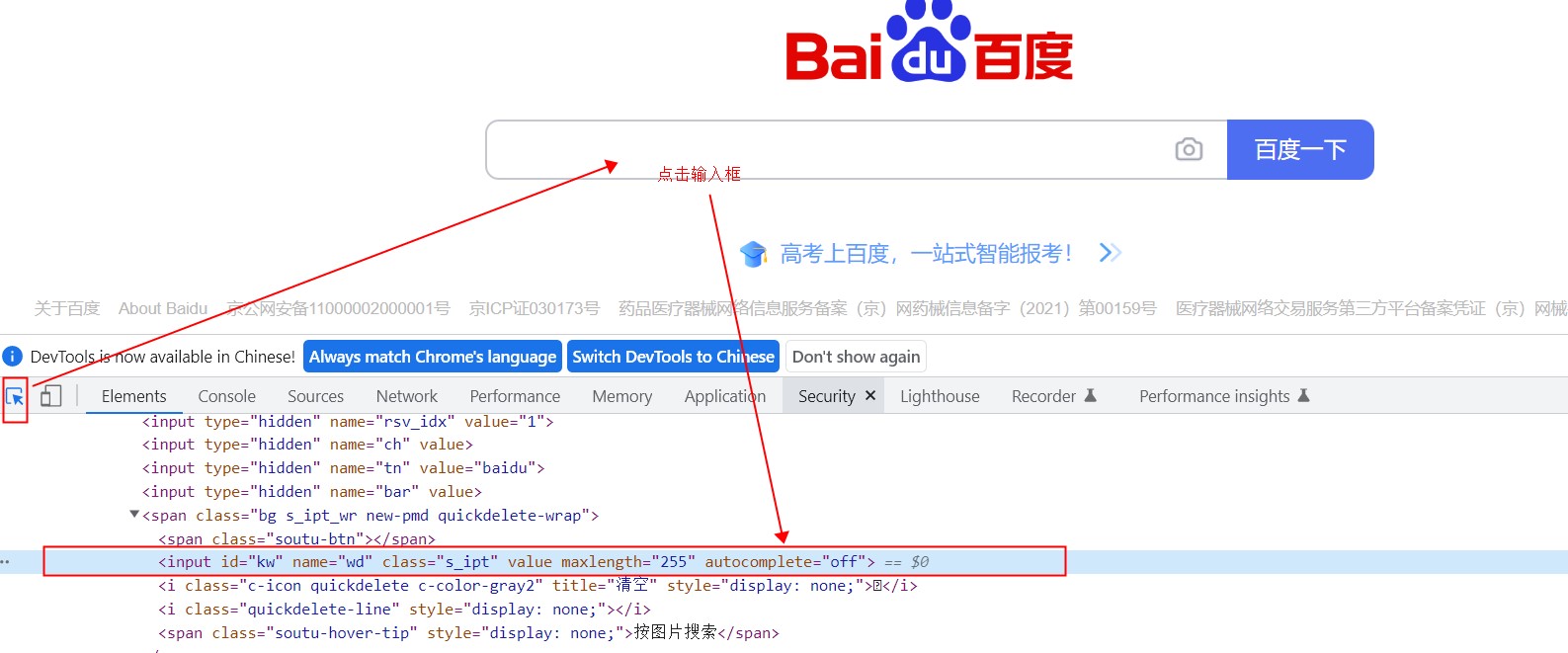
在阴影处右击,我们可以复制xpath、full xpath ,css selector如下图所示:
a:ID = "id" ,每个元素的ID是唯一性,不可重复的。
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #ID = "id" 4 #实例化webdriver,并且指定要测试的浏览器 5 driver=webdriver.Chrome() 6 #打开浏览器后导航到百度 7 driver.get("http://www.baidu.com") 8 #send_keys是输入方法(通过ID的属性定位到百度的搜索输入框,并且输入搜索的关键字) 9 driver.find_element_by_id("kw").send_keys("selenium") 10 t.sleep(3) 11 #退出浏览器 12 driver.quit()
e:NAME = "name"
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #NAME = "name" 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element_by_name("wd").send_keys("selenium") 7 t.sleep(3) 8 driver.quite()
g:CLASS_NAME = "class_name"
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #CLASS_NAME = "class name" 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element_by_class_name("s_ipt").send_keys("selenium") 7 t.sleep(3) 8 driver.quit()
当一个元素使用ID、name、class_name定位不到的时候,那么这个时候使用css(基于样式)和xpath(基于路径)。
h:CSS_SELECTOR = "css_selector"
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #CSS_SELECTOR = "css selector" 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element_by_css_selector("#kw").send_keys("selenium") 7 t.sleep(3) 8 driver.quit()
b:XPATH = "xpath"
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #XPATH = "xpath" 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element_by_xpath('//*[@id="kw"]').send_keys("selenium") 7 t.sleep(3) 8 driver.quit()
注意:xpath定位,是当元素的ID是固定不变的时候所使用。
full xpath ,是当元素的ID是动态变化的时候所使用。
c:精确查找,LINK_TEXT = "link_text",是超链接。
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #精确查找:LINK_TEXT = "link text" 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element_by_link_text("视频").click() 7 t.sleep(3) 8 driver.quit()
d:模糊查找,PARTIAL_LINK_TEXT = "partial_link_text"
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #模糊查找:PARTIAL_LINK_TEXT = "partial link text" 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element_by_partial_link_text("网").click() 7 t.sleep(3) 8 driver.quit()
2、元素定位从分类上来分
a:单个元素定位(8个)
b:多个元素定位(元素属性都一致)(8个)
[1]:获取到元素的属性,它是一个列表。
[2]:按照我们需要被定位的元素属性,它在列表中是第几位,那么就使用它的索引来定位。
实例1:在桌面存放一个index.html的网页,内容如下:
1 <!DOCTYPE html> 2 <html lang="en"> 3 <head> 4 <meta charset="UTF-8"> 5 <title>Title</title> 6 </head> 7 <body> 8 <center> 9 <p> 10 账户:<input id="login" type="text" placeholder="请输入账户"> 11 </p> 12 <p> 13 密码:<input id="login" type="password" placeholder="请输入密码"> 14 </p> 15 <p> 16 登录:<input id="login" type="button"> 17 </p> 18 19 <a href="http://www.baidu.com">百度</a> 20 </center> 21 </body> 22 </html>
我们通过input里的相同id来定位,如下图所示:
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #多个元素定位,需要列表索引来定位 4 driver=webdriver.Chrome() 5 driver.get("file:///C:/Users/Administrator/Desktop/index.html") 6 listID=driver.find_elements_by_id("login") 7 print(type(listID)) 8 #输入账户 9 listID[0].send_keys("黛西") 10 t.sleep(3) 11 #输入密码 12 listID[1].send_keys("123") 13 t.sleep(3) 14 #点击登录按钮 15 listID[2].click() 16 t.sleep(2) 17 driver.quit()
或者通过input标签来定位,如下图所示:
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 driver=webdriver.Chrome() 4 driver.maximize_window() 5 driver.get("file:///D:/Desktop/%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95/%E5%8F%91%E9%80%81%E7%9A%84%E6%96%87%E4%BB%B6/index.html") 6 listID=driver.find_elements_by_tag_name('input') 7 print(type(listID)) 8 # 输入账户 9 listID[0].send_keys("黛西") 10 t.sleep(3) 11 # 输入密码 12 listID[1].send_keys("123") 13 t.sleep(3) 14 # 点击登录按钮 15 listID[2].click() 16 t.sleep(2) 17 driver.quit()
实例2:通过input标签来定位,以百度的搜索框为例,如下图所示:
1 from selenium import webdriver #包:selenium,模块:webdriver 2 import time as t 3 #TAG_NAME = "tag name" 4 #多个元素定位,需要列表索引来定位 5 driver=webdriver.Chrome() 6 driver.get("http://www.baidu.com") 7 inputs=driver.find_elements_by_tag_name("input") #注意:elements 8 inputs[7].send_keys("selenium") 9 t.sleep(3) 10 driver.quit()
3、通过更简单的By来定位
1 from selenium import webdriver #包:selenium,模块:webdriver 2 from selenium.webdriver.common.by import By 3 import time as t 4 driver=webdriver.Chrome() 5 driver.get("http://www.baidu.com") 6 driver.find_element(By.ID,"kw").send_keys("selenium") 7 t.sleep(3) 8 driver.quit()
五、利用iframe框架来定位
1、为什么我们要使用iframe框架来定位?
当我们使用上述8种方式,去操作时,并没有任何问题,但是就是没有访问到,那么有可能是在iframe框架里嵌套着。
2、进入iframe框架的三种方式
[1]:ID
[2]:name
[3]:索引
3、当存在单个元素定位时,通过id和name定位
1 from selenium import webdriver #包:selenium,模块:webdriver 2 from selenium.webdriver.common.by import By 3 import time as t 4 driver=webdriver.Chrome() 5 driver.get("http://mail.qq.com") 6 7 #进入iframe框架 8 driver.switch_to.frame("login_frame") #通过name定位 9 t.sleep(2) 10 11 driver.find_element(By.NAME,"u").send_keys("1658376993") 12 t.sleep(3) 13 driver.quit()
4、当存在多元素定位时,我们使用索引
1 from selenium import webdriver #包:selenium,模块:webdriver 2 from selenium.webdriver.common.by import By 3 import time as t 4 driver=webdriver.Chrome() 5 driver.get("http://mail.qq.com") 6 7 #进入iframe框架 8 driver.switch_to.frame(1) #(1)是iframe框架的索引 9 t.sleep(2) 10 11 driver.find_element(By.NAME,"u").send_keys("1658376993") 12 t.sleep(3) 13 driver.quit()
5、实战淘宝
1 from selenium import webdriver #包:selenium,模块:webdriver 2 from selenium.webdriver.common.by import By 3 import time as t 4 5 #实战淘宝 6 driver=webdriver.Chrome() 7 driver.get("https://www.taobao.com/") 8 9 #无iframe框架 10 driver.find_element(By.LINK_TEXT,"亲,请登录").click() 11 # <a href="//login.taobao.com/member/login.jhtml?f=top&redirectURL=https%3A%2F%2Fwww.taobao.com%2F" target="_top" class="h">亲,请登录</a> 12 #这里的“亲,请登录”是超链接<a href=.........>亲,请登录</a>的名字 13 t.sleep(3) 14 driver.find_element(By.NAME,"fm-login-id").send_keys("16583") 15 t.sleep(3) 16 driver.quit()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号