文件操作1:
#文件操作:
#文件打开模式 9种 读r 写w 追加a
# f = open("a.txt") #打开文件不存在的话,会报错
# #file() python2里面等同于open()
# result = f.read()
# f.close()
# f = open("a.txt",'w',encoding='utf-8')
# f.write("你好呀")
# f.close()
# f = open("a.txt",'r',encoding='utf-8')
# result = f.read()
# f.close()
# print(result)
# f = open("a.txt",'a',encoding='utf-8')
# result = f.write("wenwen")
# f.close()
# print(result)
# 总结:
# r:只能读不能写;文件不存在报错;默认是读模式
# w:只能写不能读;文件不存在会创建;文件已存在会清空里面内容
# a:只能写不能读;文件不存在会创建;不会清空文件内容,会在末尾添加
f = open("a.txt",'w',encoding='utf-8')
nums = ["1","2","3","4","7"]
num = [1,2,3,4,5]
#result = f.read()#读取所有内容,返回是字符串
#result = f.readlines()#读取所有内容,返回是list
#print(f.readline())#读取一行
# print("f.readline",f.readline())#读第一行
# print("f.read",f.read())#读第二行至结尾
# print("f.readlines",f.readlines())#内容都读完了,没内容了
# f.seek(0)#文件指针,回到最前面
#f.write("你好呀")#只能写字符串,如果写列表需循环
# for i in nums:
# f.write(i)
#f.writelines(nums)#可直接传list,不需要循环
# num2 = [str(i)+'\n' for i in num]#int类型,用writelines写入并换行
# f.writelines(num2)
# f.close()
解包:
# msg = "admin,123456"
# username = msg.split(',')[0] #[username,password]
# password = msg.split(',')[1] #[username,password]
#
# username,password = msg.split(',')#列表,元组,字符串都可以解包,等同于上面,解包成admin 123456
# print(username)
# print(password)
# d = {"username":"admin","password":"123456"}
# print(d.items())# [('username', 'admin'), ('password', '123456')]
# for k,v in d.items():#解包
# print(k,v)
文件操作2:
#r+ w+ a+
#读写 写读 追加读模式
#r相关,文件不存在都会报错,他的文件指针是在最前面的
#w相关,都会创建文件,都会清空文件内容
#a相关,文件指针默认在末尾,如果你要读,那么你就移动文件指针,不管你怎么移动文件指针,写的时候都是追加在最后面
# f = open('user.txt','r+',encoding="utf-8")
# f.read()
# f.write("你好啊")
# f.close()
# f = open('user.txt','w+',encoding="utf-8")
# f.write("abbdsfsdfsd")
# 不是说你写什么内容就立即写入磁盘,这样影响效率,内存里有个缓冲区,得缓冲区满了才写入磁盘,故会有你写的东西还没写入文件里
# # f.flush()#缓冲区没满,需要调用下f.flush()就立即写入磁盘里了
# f.seek(0)
# print(f.read())
# f.close()
# f = open('user.txt','a+',encoding="utf-8")
# f.seek(0)
# print(f.read())
# f.write("wenwen")
# f.close()
# print(f.tell() ) #告诉你现在文件指针的位置
# rb wb ab rb+ wb+ ab+#操作二进制文件跟b有关
#处理大文件时,一行一行读,不用readline或readlines

# f = open('access.log',encoding='utf-8')
# for line in f:#直接循环文件对象,就是循环文件里每一行
# print(line)
# f.close()
监控日志练习:
# 练习,打开access.log文件,比如有个ip地址1分钟内访问超过50次,怀疑受攻击,我要找出这个ip加入黑名单
# 思路:
# 1死循环
# 2读文件,移动文件指针(第一次读的时候,指针应该是0)
# 3找出文件里面的ip地址
# 4记录当前的文件指针位置,赋值给文件指针
# 5ip地址存起来list/dict
# list:存列表,判断相同的ip放在一个列表里,这样列表累加,越来越大
# dict:ip作为key,出现次数作为value,显然存字典更好
# 6循环字典,判断出现次数,找出大于50次
# 7sleep(60)#持续60秒
# import time
# FILE_NAME = 'access.log'
# point = 0
# while True:#死循环
# ips = {}#如果放在循环外,外面列表是一分钟一分钟累加状态,则几分钟后,更多的ip大于50次出现,逻辑不对了
# f = open(FILE_NAME,encoding='utf-8')
# f.seek(point)
# for line in f:
# line = line.strip()
# if line:
# ip = line.split()[0]
# if ip in ips:
# ips[ip] +=1#字典赋值value,累加1
# else:
# ips[ip] = 1#字典赋值,ip首次出现,次数为1,加入字典中
# point = f.tell()#记录当前的文件指针位置,赋值给文件指针
# f.close()#读完结束
# for ip,count in ips.items():
# if count>=50:
# print("加入黑名单的ip是 %s" % ip)
# time.sleep(60)
# 实际应用用下面代码,基本这个日志文件里有几分钟的数据了,这样里面的ip有很多次了,要判断是否为第一次读取
# import time
# FILE_NAME = 'access.log'
# point = 0
# while True:#死循环
# ips = {}
# f = open(FILE_NAME,encoding='utf-8')
# f.seek(point)
# if point == 0: #判断是否为第一次读取
# f.read()
# else:
# for line in f:
# line = line.strip()
# if line:
# ip = line.split()[0]
# if ip in ips:
# ips[ip] +=1#字典赋值value,累加1
# else:
# ips[ip] = 1#字典赋值,ip首次出现,次数为1,加入字典中
# point = f.tell()#记录当前的文件指针位置,赋值给文件指针
# f.close()#读完结束
# for ip,count in ips.items():
# if count>=50:
# print("加入黑名单的ip是 %s" % ip)
# time.sleep(60)
修改文件:
# 要打卡其他目录下的文件,用绝对路径
# f = open('/Users/nhy/Desktop/fmz.txt')#mac系统
# f = open('e:\\niuhy\\xxxx\\xx')#windows,需再转义
# f = open(r'e:\niuhy\xxxx\xx') #原字符,或者加r表明不要转义
# f = open('user.txt',encoding='utf-8')
# result = f.read()
# f.close()
# new_result = result.replace("hello","你好")#你好替换hello,然后存到新变量new_result
# f = open("user.txt",'w',encoding="utf-8")#w模式,清空user.txt
# f.write(new_result)#重写进去,打开两次文件,简单粗暴
# f.close()
# f = open("user.txt",'a+',encoding="utf-8")
# f.seek(0)
# result = f.read()#用read,如果大文件,一次性全读了
# result_new = result.replace("hello","你好")
# f.seek(0)
# f.truncate() #清空文件
# f.write(result_new)#打开一次文件
# f.close()
# 大文件常用下面代码修改文件,小文件上面两种代码都可
# import os
# f1 = open("user.txt",encoding='utf-8')
# f2 = open("user.txt.bak","w",encoding="utf-8")
# for line in f1:#一行一行读
# new_line = line.replace("周","周杰伦")
# f2.write(new_line)
# f1.close()
# f2.close()
# os.remove("user.txt")#删除
# os.rename("user.txt.bak","user.txt")#重命名
自动关闭文件:
# f = open("user.txt",'a+',encoding="utf-8")
# with open("user.txt",encoding="utf-8") as f:#with相当于不用写f.close
# with open("user.txt",encoding="utf-8") as f, open("user.txt2","w",encoding='utf-8') as f2:#打开多个文件
# for line in f:
# new_line = line.replace("周杰伦","周")
# f2.write(new_line)
json模块:
# 百度:bejson.com检查json格式
import json
import pprint
#{"code":0,"msg":"操作成功","token":"xxxxx"}
#json是一个字符串
#python的数据类型转成json,字典转成字符串用dumps
# d = {"code":0,"msg":"操作成功","token":"xxxxx"}
# pprint.pprint(d)
# json_str = json.dumps(d,ensure_ascii=False)#ensure_ascii=False保留中文,否则是unicode
# pprint.pprint(json_str) #unicode
#json转成python的数据类型,字符串转成字典用loads
# json_str = '{"code": 0, "msg": "操作成功", "token": "xxxxx"}'
# dic = json.loads(json_str)
# pprint.pprint(dic)
# with open("student.txt",encoding="utf-8") as f:
# dic = json.loads(f.read())
# pprint.pprint(dic)
# d = {"code":0,"msg":"操作成功",
# "token":"xxxxx","addr":"xxxx","sdgsdg":"xxx",
# "sdfsdf":"sdgsdg","s11":"111"}
# with open("student2.json",'w',encoding="utf-8") as f:
# json_str = json.dumps(d,ensure_ascii=False,indent=4)#indent=4缩进,格式好看些
# f.write(json_str)
# pprint.pprint(json_str)
# 不带s都和文件相关,操作文件用下面方式,方便
# with open("student2.json",encoding="utf-8") as f:
# result = json.load(f)#对象是文件,直接转字典,会自动读内容
# print(result)
# with open("student2.json",'w',encoding="utf-8") as f:
# json.dump(d,f,ensure_ascii=False,indent=4)
函数:
#函数、方法(提高的代码复用性,简化代码)
# def hello():#定义函数
# print('hello')
# hello()#调用hello函数,函数必须调用之后才能执行

# def welcome(name,country="中国"):
# print("welcome %s,you are from %s" % (name,country))
# welcome("candy")
# welcome("郑佩佩","美国")
# 封装op_file函数,功能为如果content不为空,就写文件,如果content为空就读文件
# 所以调用这个函数直接写内容即可,不用打开文件了
# def op_file(filename,content=None):
# with open(filename,'a+',encoding="utf-8") as f:
# f.seek(0)
# if content:
# f.write(content)
# else:
# result = f.read()
# return result#写return,读才能拿到结果
# content = op_file("student2.json")#先返回,然后用content接着
# print(content)
#函数里面定义的变量都是局部变量,只在函数内部生效
#函数return除了返回值外,只要遇到return函数立即结束
# def hello():#定义函数
# print('hello')
# def welcome(name,country="中国"):
# return name,country
# def test():
# return
# r = hello()
# print('没有写return',r)#None
# print('return多个值的时候', welcome("小黑"))#('小黑', '中国')
# print( 'return后面啥也不写',test())#None
#练习:写一个字符串判断合法小数的函数,1.1和-1.1都是,即写一个校验小数格式的函数
#思路:
# 1判断是否只有一个小数点
# 2正小数,小数点左边和右边必须是整数
# 3负小数,小数点右边必须是整数,小数点左边只能有一个负号,负号后面必须是整数
# def is_float(s):
# s = str(s)#不管什么类型,先转字符串
# if s.count('.') == 1:#一个小数点
# left,right = s.split('.') #[1,1]#-s.2
# if left.isdigit() and right.isdigit():
# return True
# elif left.startswith('-') and left.count('-')==1 \
# and left[1:].isdigit() and right.isdigit():
# #左边以负号开头且有一个负号,然后负号为0下标,从下标1开始取
# return True
# return False
#
# print(is_float(-2))#验证代码
# 应用:
# price = input("请输入价格:").strip()
# if is_float(price):
# print("价格合法")
# else:
# print("价格不合法")
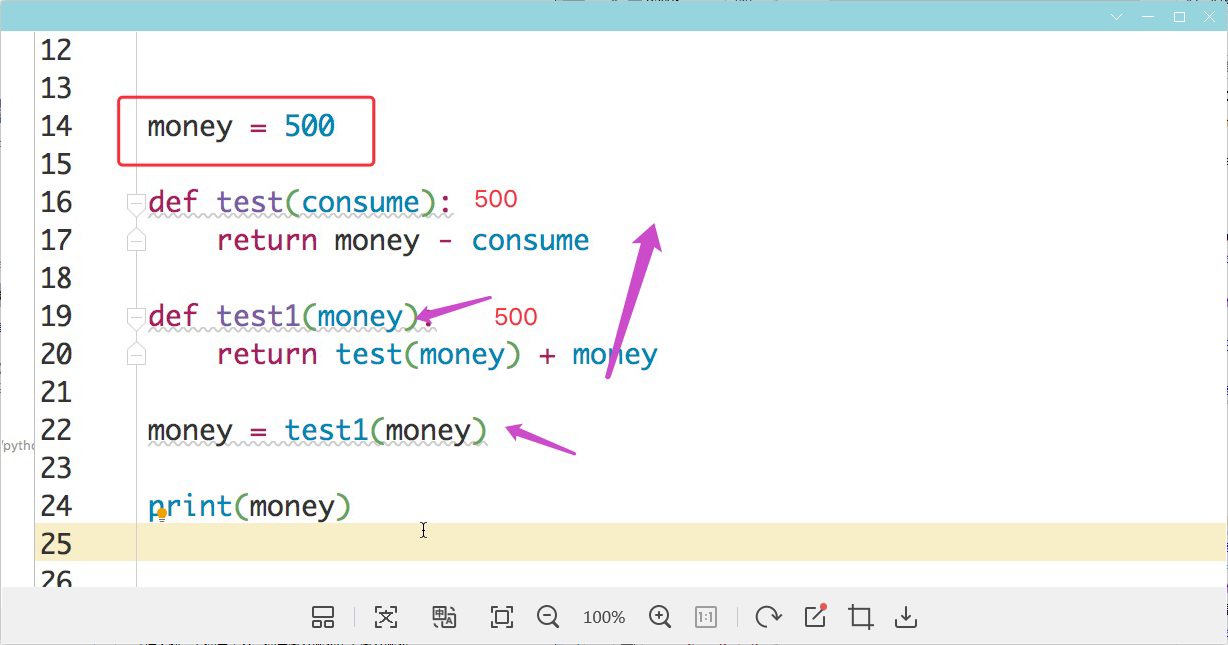
# money = 500
# def test(consume):
# return money - consume
# def test1(money):
# return test(money) + money
# money = test1(money)
# print(money)
#插入图,看调用关系,调用哪个函数先看哪个函数
# a = 100 #全局变量。少用全局变量,会一直占内存,另外不安全,大家都可以用
# def test():
# # global a#在函数里面要改全局变量,要用global声明下
# a = 1
# print(a)
# test()
# print(a)
# def test():
# global a
# a = 5
# def test1():
# c = a + 5
# return c
# res = test1()
# print(res)
# def test():
# l = []
# for i in range(50):
# if i % 2 ==0:
# l.append(i)
# return l#return立即结束
# print(test())
递归:
#函数自己调用自己,就是递归
# count = 0#死循环,最多调用998次
# def test():
# global count
# count+=1
# print("5.1快乐",count)
# test()
# test()
# def test():
# number = input("请输入一个数字:").strip()
# number = int(number)
# if number %2 == 0:
# print("输入正确")
# return
# test()
# test()
#面试题:写一个函数功能是替换replace,不能用自带方法a.replace
# def replace(src,old,new):
# if old in src:#先判断123在字符串里吗
# return new.join(src.split(old))#src.split(old)按照123分隔,
# return src
# a = 'abc123abc123sdgsd123' #[abc你好abc你好sdgsd你好]
# b = "123"
# c = "你好"
# result = replace(a,b,c)
# print(result)
# abc你好abc你好sdgsd你好
# result = a.replace('123','你好')
# print(result)
函数参数:
#必填参数(位置参数)
#默认值参数
#可选参数,参数组
#关键字参数
# def test(name,country='China'):#name 必填参数(位置参数)。country='China' 默认值参数
# print(name)
# print(country)
# a = "小黑"
# b = "japan"
# test(a,b)#对应位置传参
# test(country="japan",name="xiaohei")#对应名字传参
# test("小黑",country="Japan")#混用传参
# test(country="Japan","小黑")#错误写法
# open("小黑")#看代码,点击左键+Ctrl
# def send_sms(*args): #可选参数,接收到的是一个元组,不限制传参个数
# print(args)
#
# send_sms()#不传参数
# send_sms(110)#传一个参数
# send_sms(110,120)#传多个参数
# send_sms(110,120,120,1330000)
# def send_sms2(**kwargs): #关键字参数,接收到的是一个字典,不限制传参个数
# print(kwargs)
# send_sms2(a=1,b=2,name="abc")#得传谁等于谁
# send_sms2()

