机器学习之Javascript篇: 近邻(k-nearest-neighbor) 算法介绍
 本文讨论了kNN算法的原理以及在机器学习具体实施过程中的细节。整个算法以及结果呈现全部利用javascript完成。
本文讨论了kNN算法的原理以及在机器学习具体实施过程中的细节。整个算法以及结果呈现全部利用javascript完成。
原文:http://burakkanber.com/blog/machine-learning-in-js-k-nearest-neighbor-part-1/
翻译:王维强
我的目的是使用一门通用语言来教授机器学习,内容涵盖基础概念与高级应用。Javascript是一个非常好的选择,最明显的优点就是对运行环境没有特殊要求。另外,因为该语言缺乏与机器学习相关的类库,也能迫使我们从基础编码写起。
先看一个实例。
今天我们将要开始近邻(k-nearest-neighbor)算法的学习,该算法在文章中一律被简写作kNN。我非常喜欢这个算法,因为虽然它简单的要命,却能解决一些令人兴奋的问题。其优点在于不依赖于复杂的数学或理论,但是在实际应用中却能对不同规模的输入参数进行优美的处理。
近邻算法也给我提供了实现初衷的好途径:该算法是介绍“监督学习”的最佳切入点。
那么就让我们着手建立最佳邻居算法吧,同时我们会让结果以图像的形式展示出来,我喜欢可视化。
监督学习
在机器学习领域中存在两个巨大的类别:监督学习和非监督学习。 简而言之,非监督学习很像数据挖据,翻检一些数据尝试得出什么有用的结论。通常情况下,在开始数据处理之前你没有更多信息可供参考。我们会在下周关注一个叫“k-means”的非监督学习算法,我们会在下一篇文章中给予其更多的讨论。
监督学习,也可以说成是开始于“训练数据”的学习算法。监督学习很像我们小时候作为孩子了解周遭世界的过程。我们和妈妈在厨房里,妈妈拿着一个苹果给我们看,同时说“苹果”二字,我们看到的东西是妈妈为我们标注好的。
第二天,她给我们看一个小一点的苹果,也不那么红,形状也稍有不同。但是妈妈给你看的同时说的仍是“苹果”这两个字。整个过程会重复几周,每天妈妈都会给你看稍有不同的苹果,并且告诉你它们是”苹果。通过这个过程你理解并记住了什么是苹果。
不是每个苹果都一模一样,一生中看到的每个苹果,你可能都认为是独一无二的,但是妈妈已经把你训练得能够识别苹果的所有特征。现在你可以建立分类或标签用来区分脑海中的各种事物。你一旦看到苹果就能立刻将之归为苹果,因为你认识到所有的苹果都共享一些相同的属性,另外这些属性可能也不必只属于苹果。
这个过程被称为“泛化”,是机器学习算法中非常重要的概念。我们不会因为一个iphone佩戴了不同的外壳或者屏幕上布满划痕就认不出来。
在建立特定类型的机器学习算法之前,我们需要了解泛化的含义。我们的算法应该能够实现泛化,但不过度泛化(说起来容易作起来难啊)。
比如,我们想要的是:“这是红色的、圆形的、光滑的,这一定是苹果。”。
不期望出现的是:“这是红色的、圆形的,这一定是个球;另外一个橙色的、圆形的,也一定是个球。”
这种过度泛化会是个问题,同时泛化不足也是问题。这就是机器学习当中的一个挑战:够找到泛化的最佳点。
你可以使用一些测试案例来检测你的算法帮你找到这个最佳点,我们也会在将来的文章中谈到更多的关于这方面的更高级的算法。
许多监督学习问题都是怎么“归类”问题。
归类问题的过程类似于,有一篮子苹果、橙子和梨。除了一个水果外,其他每个水果都有个标签告诉你这个水果是什么。你需要通过学习这些标注过的水果来指出未标注的一个是什么水果。
这种归类问题对人类来说非常简单,但是计算机不知道该怎么做。kNN就是众多归类算法中的一个。
特征
先介绍一下机器学习中一个非常重要的概念了:特征。
特征是从对象中提取出来的能够放入机器学习过程中的信息。比如你正在甄别一个物体是苹果还是橙子,你可能要观察以下特征:形状,大小,颜色,光滑度,表面纹理等等。很可能某些时候某个具体特征对甄别什么是苹果或橙子并没有什么帮助,苹果和橙子在尺寸方面就差别不大,所以该特征可以被弃用以节约计算成本。在此例中,尺寸特征真的没有什么帮助。
在设计机器学习算法时,能知道哪些特征需要考虑在内是非常重要的技能。有时你可能依靠直觉,但是大多时候你希望能利用另外一套算法来判断哪些特征是重要的(关于这一点,会在未来的更多文章中进行讨论)。
如你所想,特征并不一直是“颜色,尺寸,形状”。 文档处理就是一个例子,在某些情况下,文档中的每个单词都是一个特征,或者每个连词也是一个特征。我们也会在将来的文章中讨论有关文档分类的话题。
问题
需要解决的问题来了,给出一个住宅的房屋数目和面积,判断出该住宅是apartment,house 或者 flat。
和往常一样,为了理解问题的根本,我们从最大可能性的地方入手。通过问题的描述我们获得了需要关注的特征是:房间数目和面积。我们可以这样考虑,既然这是一个监督学习问题,我们就能从案例数据中获得帮助。
什么是 "k-nearest-neighbor" 测量
我认为教授kNN算法最好的方式就是简单地阐释“k-nearest-neighbor”的真正含义。
如下表所示,这里列出了针对该问题的案例数据:
| Rooms | Area | Type |
|---|---|---|
| 1 | 350 | apartment |
| 2 | 300 | apartment |
| 3 | 300 | apartment |
| 4 | 250 | apartment |
| 4 | 500 | apartment |
| 4 | 400 | apartment |
| 5 | 450 | apartment |
| 7 | 850 | house |
| 7 | 900 | house |
| 7 | 1200 | house |
| 8 | 1500 | house |
| 9 | 1300 | house |
| 8 | 1240 | house |
| 10 | 1700 | house |
| 9 | 1000 | house |
| 1 | 800 | flat |
| 3 | 900 | flat |
| 2 | 700 | flat |
| 1 | 900 | flat |
| 2 | 1150 | flat |
| 1 | 1000 | flat |
| 2 | 1200 | flat |
| 1 | 1300 | flat |
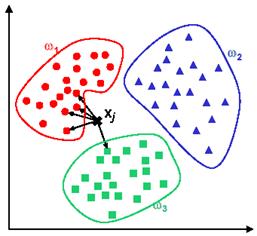
我们将把上面这些信息用坐标点的方式在图像中呈现出来,以房间数目为横坐标,以面积为纵坐标。
当我们不可避免的加入一个新的未标记的数据点(“迷点”)时,也把它画在图上。然后我们选择一个数(称之为k),并且找到图中最接近“迷点”的k个数据点,如果这些点中主要是“flat",那么我们有理由猜测这个”迷点“所代表的住宅也是一个flat。
这就是近邻算法的含义。
如果3个最近的邻居点中有两个是apartment,另一个是house,则我们就可以说“迷点”所代表的住宅是一个apartment。
其简略过程如下:
- 把所有数据(包括迷点)放入图中。
- 测量迷点和每个点的距离。
- 选取一个数值。对于小型数据集,3是不错的选择。
- 找出哪3(k)个点离“迷点”最近。
- 3个点中多数点所代表的,就是我们想要的答案。
代码
现在开始搭建程序,在我们实施算法的过程中会蹦出来一些新的点子,所以请先仔细阅读下文,如果跳过,你会丢掉很重要的概念。
针对这个算法我会创建两个类,一个是 Node,一个是 NodeList。
Node 表示集合中的某个具体数据,可以是已经标记好的数据,也可以是迷点。
NodeList 管理所有 Node 并实现一些额外的功能,如画图。
Node 的构造函数不做任何事情,只是表达一个对象,其属性有“type”,“area” 和“rooms”。
var Node = function(object) {
for (var key in object)
{
this[key] = object[key];
}
};
通常情况下,我在创建算法时会把特征更多地更抽像出来。本例中需要在某些地方硬编码面积(area)和房间数目(rooms),但是我通常创建更通用的kNN算法以便能应付任意特征,而不仅仅限定于我们刚刚定义的内容。我会把这个作为练习留给你。
类似的,NodeList的构造器也很简单:
var NodeList = function(k) {
this.nodes = [];
this.k = k;
};
NodeList 构造器把 k,也就是kNN中的k作为唯一参数。
这里有个简单的函数没有写出来,NodeList.prototype.add(node), 该函数只负责把 node 压进 this.nodes 数组中。
接下来似乎我们就可以进入计算距离的议题了,但是我还是想偏离一下,先讨论另一个问题。
特征归一化
观察上面表格中的数据,房间数目从1到10不等,面积从250到1700不等。如果我们直接拿这些数据在图上标注会发生什么情况? 很显然,数据点会几乎列在一条纵线上,看起来丑陋而不易辩读。
很不幸,这不仅是一个审美的问题,而会造成数据特征方面的巨大矛盾。
房间数从1到10对于确认该住所是 flat 还是 house 是非常巨大的跨度,但是相比面积数据的差异时,即使是房间数目的差异达到了9,对距离计算来说也相当于无。如果在计算 Node 间距离的过程中不调整这种矛盾,你会发现房间数目对计算结果的影响微乎其微,因为数据间在横坐标方向彼此靠的实在太近了。
同样是面积为700,房间数目分别为1和5的两个住所,区别是什么?观察上表中的数据,你会看到第一行是flat,第二行是apartment。但是,如果把它们标注在图上并运行kNN算法,二者会被认为都是flat。
所以,我们使用把值归一化到0到1的区间的方法,以取代直接使用这些数据。归一化后,房间数目最小的1变为0,原本最大的10变为1。与之相似,最小面积为250的变为0,最大面积数1700变为1。这样一来所有数据都处于同一级别,也就消除了比例矛盾的问题。这是一个制造差异化的简单的方法。
提示: 你甚至不需要像我以上描述的那样缩放某个数据(比如面积),如果面积比房间数目重要,你可以按照不同的比例缩放他们,这就是“权重”,给予某个特征更重要的地位。有一些算法可以判定什么样的权重比较合适,以后我们会讲到...
怎么开始做数据的归一化呢? 我们应该给 NodeList 提供一个能找出每个特征数据的最大值和最小值的方法:
NodeList.prototype.calculateRanges = function() {
this.areas = {min: 1000000, max: 0};
this.rooms = {min: 1000000, max: 0};
for (var i in this.nodes)
{
if (this.nodes[i].rooms < this.rooms.min)
{
this.rooms.min = this.nodes[i].rooms;
}
if (this.nodes[i].rooms > this.rooms.max)
{
this.rooms.max = this.nodes[i].rooms;
}
if (this.nodes[i].area < this.areas.min)
{
this.areas.min = this.nodes[i].area;
}
if (this.nodes[i].area > this.areas.max)
{
this.areas.max = this.nodes[i].area;
}
}
};
我之前说过,最好的方法是抽象出特征量而不是硬编码房间的数目或面积,但是,现在这样做对我讲解算法来说更清晰些。
现在有了最大和最小值,我们可以开始算法的核心功能了。
把所有的 Node 压入 NodeList 之后:
NodeList.prototype.determineUnknown = function() {
this.calculateRanges();
/*
* Loop through our nodes and look for unknown types.
*/
for (var i in this.nodes)
{
if ( ! this.nodes[i].type)
{
/*
* If the node is an unknown type, clone the nodes list and then measure distances.
*/
/* Clone nodes */
this.nodes[i].neighbors = [];
for (var j in this.nodes)
{
if ( ! this.nodes[j].type)
continue;
this.nodes[i].neighbors.push( new Node(this.nodes[j]) );
}
/* Measure distances */
this.nodes[i].measureDistances(this.areas, this.rooms);
/* Sort by distance */
this.nodes[i].sortByDistance();
/* Guess type */
console.log(this.nodes[i].guessType(this.k));
}
}
};
作为入口,首先计算最大最小值的范围。
然后循环整个 Node 集合寻找未知 Node(没错,未知Node可以不止一个)。
一旦发现某个未知 Node,就把所有已知的 Node 克隆出来作为该未知 Node 的邻居序列。之所以这样做是因为我们需要计算该未知 Node 和所有已知Node的距离。
最后,我们连续调用未知 Node 的三个方法: measureDistances, sortByDistance, 和 guessType.
Node.prototype.measureDistances = function(area_range_obj, rooms_range_obj) {
var rooms_range = rooms_range_obj.max - rooms_range_obj.min;
var area_range = area_range_obj.max - area_range_obj.min;
for (var i in this.neighbors)
{
/* Just shortcut syntax */
var neighbor = this.neighbors[i];
var delta_rooms = neighbor.rooms - this.rooms;
delta_rooms = (delta_rooms ) / rooms_range;
var delta_area = neighbor.area - this.area;
delta_area = (delta_area ) / area_range;
neighbor.distance = Math.sqrt( delta_rooms*delta_rooms + delta_area*delta_area );
}
};
measureDistances 方法两个参数分别是面积和房间数的最大最小值区间,如果你已经把硬编码的特征抽象出来了,那么该方法的参数就会变成了一数组,该数的每个元素是一个特征值区间,但是这里我还是使用硬编码,以方便理解。
接下来快速计算房间数区间(值为9),面积区间(值为1450)。
然后循环处理未知 Node 的所有的邻居,针对每个邻居计算出来房间数目和面积大小的差异(delta_room,delta_area),然后做归一化处理(用差异值除以区间值)。
比如,房间数目差值为3,范围区间是9,那么delta_room的值为3/9等于0.333,该值应该永远处于-1到+1之间。
最后,用毕达哥拉斯定理计算距离(译者注:勾股定理)。需要注意的是,如果维度超过2,还是可以直接用这个定理,把所有的差值平方后相加,再开方即可:
Math.sqrt( a*a + b*b + c*c + d*d + ... + z*z );
到目前为止,人们对该算法的优势的了解还是比较清楚的。人的脑力对5或10个特征之间的统计可能还应付的了,但是该算法却可以处理成百上千的维度。
Node.prototype.sortByDistance = function() {
this.neighbors.sort(function (a, b) {
return a.distance - b.distance;
});
};
sortByDistance 方法用距离排序所有邻居。
Node.prototype.guessType = function(k) {
var types = {};
for (var i in this.neighbors.slice(0, k))
{
var neighbor = this.neighbors[i];
if ( ! types[neighbor.type] )
{
types[neighbor.type] = 0;
}
types[neighbor.type] += 1;
}
var guess = {type: false, count: 0};
for (var type in types)
{
if (types[type] > guess.count)
{
guess.type = type;
guess.count = types[type];
}
}
this.guess = guess;
return types;
};
最后一个算法是 guessType, 该方法需要一个参数 k,找出 k 个最接近该点的邻居,然后按照这些邻居的类型标记,找出占大多数的一类(flat,house,apartment),那么这个类型就是要返回的结果。
恭喜!算法结束了。现在就让我们把它画出来把。
利用Canvas画出结果
画出结果的方法还是很直截了当的:
- 用颜色标记类型:apartments = red, houses = green, flats = blue.
- 把图形缩放在一个正方形之内(我们之前做归一化的一个重要原因).
- 我们还需要设置些图形的边界空白,如果有些数据落在太靠边的位置,看起来不是很好。
- 需要把kNN算法的结果以圆环的形式表示出来,圆环内就是囊括在内的k个最近邻居,圆环需要用显著的颜色表示出来。
NodeList.prototype.draw = function(canvas_id) {
var rooms_range = this.rooms.max - this.rooms.min;
var areas_range = this.areas.max - this.areas.min;
var canvas = document.getElementById(canvas_id);
var ctx = canvas.getContext("2d");
var width = 400;
var height = 400;
ctx.clearRect(0,0,width, height);
for (var i in this.nodes)
{
ctx.save();
switch (this.nodes[i].type)
{
case 'apartment':
ctx.fillStyle = 'red';
break;
case 'house':
ctx.fillStyle = 'green';
break;
case 'flat':
ctx.fillStyle = 'blue';
break;
default:
ctx.fillStyle = '#666666';
}
var padding = 40;
var x_shift_pct = (width - padding) / width;
var y_shift_pct = (height - padding) / height;
var x = (this.nodes[i].rooms - this.rooms.min) * (width / rooms_range) * x_shift_pct + (padding / 2);
var y = (this.nodes[i].area - this.areas.min) * (height / areas_range) * y_shift_pct + (padding / 2);
y = Math.abs(y - height);
ctx.translate(x, y);
ctx.beginPath();
ctx.arc(0, 0, 5, 0, Math.PI*2, true);
ctx.fill();
ctx.closePath();
/*
* Is this an unknown node? If so, draw the radius of influence
*/
if ( ! this.nodes[i].type )
{
switch (this.nodes[i].guess.type)
{
case 'apartment':
ctx.strokeStyle = 'red';
break;
case 'house':
ctx.strokeStyle = 'green';
break;
case 'flat':
ctx.strokeStyle = 'blue';
break;
default:
ctx.strokeStyle = '#666666';
}
var radius = this.nodes[i].neighbors[this.k - 1].distance * width;
radius *= x_shift_pct;
ctx.beginPath();
ctx.arc(0, 0, radius, 0, Math.PI*2, true);
ctx.stroke();
ctx.closePath();
}
ctx.restore();
}
};
上面的代码,我不想给出详细的说明了,但是有两行你需要自己得出结论:
- "var x = "
- "var radius = "
过程可能令人费解沮丧,但这是很好的练习机会,不要放弃,直至理解他们。
最终,我们还要加入一些代码,功能就是每隔五秒生成一个随机点作为迷点数据:
var run = function() {
nodes = new NodeList(3);
for (var i in data)
{
nodes.add( new Node(data[i]) );
}
var random_rooms = Math.round( Math.random() * 10 );
var random_area = Math.round( Math.random() * 2000 );
nodes.add( new Node({rooms: random_rooms, area: random_area, type: false}) );
nodes.determineUnknown();
nodes.draw("canvas");
};
window.onload = function() {
setInterval(run, 5000);
run();
};
如果你想对k值做些调整,可以在上述的 run() 方法中实施。
kNN算法不是一个十分复杂的分类器,但是有很多非常棒的应用,更令人兴奋的地方在于你不必把它当作一个分类器,kNN背后的概念能十分灵活地解决非分类器方面的问题。对于解决下列问题,kNN可能依然是非常好的候选方案。
- 哪个颜色名称(blue, red, green, yellow, grey, purple等等)与给定的 RGB 值接近? 这种算法在图像搜索中非常有用,比如“搜索紫色的图片”。
- 你正在创建一个约会网站,并且想为针对某个人的情况给出的匹配排序。特征可能包括未知,年龄,身高,用kNN算法找出20个最靠近的邻居并排序。
- 快速找出与给定文档相似的5个文档。特征就是文档中的单词。解决这种问题并不需要十分复杂的算法。
- 给出以前电商顾客的数据,分析出当前正在浏览网站的潜在购买者会不会发生购买行为? 特征可能是一天中的时间段,浏览页数,位置,链接来源等。
弱点及说明
kNN存在两个问题。
一、如果数据训练充满整个空间,到处都是,那么该算法就会力不从心。也就是说,数据在某些特征上需要是可分割的或聚集的。图像上的随机斑点是没有任何帮助的。只有非常少的机器学习算法可以从密集随机数据中识别出模式。
二、如果数据集增加到数千的规模,将会出现计算效率问题,距离计算也会让算法在效率上雪上加霜。一个可行的方法是首先滤掉在特征值区间意外的那些数据。例如,迷点数据的房间数是3,我们可能就没有必要把那些房间数大于6的也考虑在内了。
下面是 JSFiddle 的链接,已知点已经用颜色标出,迷点为灰色,kNN的猜测结果是围绕迷点的一个圆圈。半径内囊括了3个最近的邻居,5秒钟之内会产生一个新的随机迷点,并给出计算结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号