
AMQP(Advanced Message Queuing Protocol, 高级消息队列协议)是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
RabbitMQ是一个实现了AMQP协议标准的开源消息代理和队列服务器。
1、基本概念
在服务器中,三个主要功能模块连接成一个处理链完成预期的功能:
1)“exchange”接收发布应用程序发送的消息,并根据一定的规则将这些消息路由到“消息队列”。
2)“message queue”存储消息,直到这些消息被消费者安全处理完为止。
3)“binding”定义了exchange和message queue之间的关联,提供路由规则。
使用这个模型我们可以很容易的模拟出存储转发队列和主题订阅这些典型的消息中间件概念。
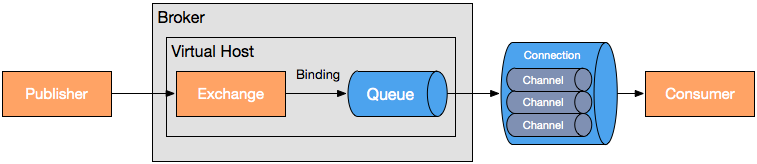
上图中各个模块的说明如下:
-
Broker: 接收和分发消息的应用,RabbitMQ Server就是Message Broker。
-
Virtual host: 出于多租户和安全因素设计的,把AMQP的基本组件划分到一个虚拟的分组中,类似于网络中的namespace概念。当多个不同的用户使用同一个RabbitMQ server提供的服务时,可以划分出多个vhost,每个用户在自己的vhost创建exchange、queue等。
-
Connection: publisher、consumer和broker之间的TCP连接。断开连接的操作只会在client端进行,Broker不会断开连接,除非出现网络故障或broker服务出现问题。
-
Channel: 如果每一次访问RabbitMQ都建立一个Connection,在消息量大的时候建立TCP Connection的开销将是巨大的,效率也较低。Channel是在connection内部建立的逻辑连接,如果应用程序支持多线程,通常每个thread创建单独的channel进行通讯,AMQP method包含了channel id帮助客户端和message broker识别channel,所以channel之间是完全隔离的。Channel作为轻量级的Connection极大减少了操作系统建立TCP connection的开销。
-
Exchange: message到达broker的第一站,根据分发规则,匹配查询表中的routing key,分发消息到queue中去。常用的类型有:direct (point-to-point), topic (publish-subscribe) and fanout (multicast)。
-
Queue: 消息最终被送到这里等待consumer取走。一个message可以被同时拷贝到多个queue中。
-
Binding: exchange和queue之间的虚拟连接,binding中可以包含routing key。Binding信息被保存到exchange中的查询表中,用于message的分发依据。
2、核心概念
1)Exchange和Binding
交换机Exchange拿到一个消息之后会将它路由给队列。Exchange使用哪种方式路由是由Binding规则决定的。
a)直连交换机
根据消息携带的路由键(routing key)将消息投递给对应队列。直连交换机用来处理消息的单播路由。
Message中的“routing key”如果和Binding中的“binding key”一致, Direct exchange则将message发到对应的queue中。
b)主题交换机
通过对消息的路由键和队列到交换机的绑定模式之间的匹配,将消息路由给一个或多个队列。主题交换机用来实现消息的多播路由。
c)扇形交换机
将消息路由给绑定到它身上的所有队列,且不理会路由键。扇形交换机用来处理消息的广播路由。
2)ACK - 消息确认
默认情况下,如果Message 已经被某个Consumer正确的接收到了,那么该Message就会被从queue中移除。当然也可以让同一个Message发送到很多的Consumer。
如果一个queue没被任何的Consumer Subscribe(订阅),那么,如果这个queue有数据到达,那么这个数据会被cache,不会被丢弃。当有Consumer时,这个数据会被立即发送到这个Consumer,这个数据被Consumer正确收到时,这个数据就被从queue中删除。
那么什么是正确收到呢?通过ack。每个Message都要被acknowledged(确认,ack)。我们可以显示的在程序中去ack,也可以自动的ack。如果有数据没有被ack,那么:
RabbitMQ Server会把这个信息发送到下一个Consumer。
如果这个app有bug,忘记了ack,那么RabbitMQ Server不会再发送数据给它,因为Server认为这个Consumer处理能力有限。
而且ack的机制可以起到限流的作用(Benefitto throttling):在Consumer处理完成数据后发送ack,甚至在额外的延时后发送ack,将有效的balance Consumer的load。
当然对于实际的例子,比如我们可能会对某些数据进行merge,比如merge 4s内的数据,然后sleep 4s后再获取数据。特别是在监听系统的state,我们不希望所有的state实时的传递上去,而是希望有一定的延时。这样可以减少某些IO,而且终端用户也不会感觉到。
3)创建队列
Consumer和Procuder都可以通过 queue.declare 创建queue。对于某个Channel来说,Consumer不能declare一个queue,却订阅其他的queue。当然也可以创建私有的queue。这样只有app本身才可以使用这个queue。queue也可以自动删除,被标为auto-delete的queue在最后一个Consumer unsubscribe后就会被自动删除。那么如果是创建一个已经存在的queue呢?那么不会有任何的影响。需要注意的是没有任何的影响,也就是说第二次创建如果参数和第一次不一样,那么该操作虽然成功,但是queue的属性并不会被修改。
那么谁应该负责创建这个queue呢?是Consumer,还是Producer?
如果queue不存在,当然Consumer不会得到任何的Message。但是如果queue不存在,那么Producer Publish的Message会被丢弃。所以,还是为了数据不丢失,Consumer和Producer都try to create the queue!反正不管怎么样,这个接口都不会出问题。
queue对load balance的处理是完美的。对于多个Consumer来说,RabbitMQ 使用循环的方式(round-robin)的方式均衡的发送给不同的Consumer。
3、RabbitMQ
send.py

# -*- coding:utf-8 -*-
import pika
from constant import rabbit_config as config
from constant import app_name
# 权限验证
credentials = pika.PlainCredentials(
config.get('username'),
config.get('password')
)
# 链接参数
# virtual_host, 在多租户系统中隔离exchange, queue
params = pika.ConnectionParameters(
host=config.get('host'),
port=config.get('port'),
virtual_host=app_name,
credentials=credentials
)
# 建立链接
connection = pika.BlockingConnection(parameters=params)
# 从链接中获得信道
channel = connection.channel()
# 声明交换机
channel.exchange_declare(
exchange='exchangeA',
exchange_type='direct',
passive=False,
durable=True,
auto_delete=False
)
# consumer创建队列, 如果没有就创建
# 队列一旦被创建, 再进行的重复创建会简单的失效, 所以建议在producer和consumer同时创建队列, 避免队列创建失败
# 创建队列回调函数, callback.
# auto_delete=True, 如果queue失去了最后一个subscriber会自动删除, 队列中的message也会失效.
# 默认auto_delete=False, 没有subscriber的队列会cache message, subscriber出现后将缓存的message发送.
channel.queue_declare(queue='standard', auto_delete=True)
# delivery_mode=2表示让消息持久化, 重启RabbitMQ也不丢失.
# 考虑成本, 开启此功能, 建议把消息存储到SSD上.
props = pika.BasicProperties(content_type='text/plain', delivery_mode=2)
# 发布消息到exchange
channel.basic_publish(
exchange='exchangeA',
routing_key='a_routing_key',
body='Hello World!',
properties=props
)
print(" [x] Sent 'Hello World!'")
# 关闭链接
connection.close()
receive.py
# -*- coding:utf-8 -*-
import pika
from constant import rabbit_config as config
from constant import app_name
# 权限验证
credentials = pika.PlainCredentials(
config.get('username'),
config.get('password')
)
# 链接参数
# virtual_host, 在多租户系统中隔离exchange, queue
params = pika.ConnectionParameters(
host=config.get('host'),
port=config.get('port'),
virtual_host=app_name,
credentials=credentials
)
# 建立链接
connection = pika.BlockingConnection(parameters=params)
# 从链接中获得信道
channel = connection.channel()
# 声明交换机, 直连方式, 后面将会创建binding将exchange和queue绑定在一起
channel.exchange_declare(
exchange='exchangeA',
exchange_type='direct',
passive=False,
durable=True,
auto_delete=False,
)
# consumer创建队列, 如果没有就创建
# 队列一旦被创建, 再进行的重复创建会简单的失效, 所以建议在producer和consumer同时创建队列, 避免队列创建失败
# 创建队列回调函数, callback.
# auto_delete=True, 如果queue失去了最后一个subscriber会自动删除, 队列中的message也会失效.
# 默认auto_delete=False, 没有subscriber的队列会cache message, subscriber出现后将缓存的message发送.
channel.queue_declare(queue='standard', auto_delete=True)
# 通过binding将队列queue和交换机exchange绑定
channel.queue_bind(
queue='standard',
exchange='exchangeA',
routing_key='a_routing_key'
)
# 处理接收到的消息的回调函数
# method_frame携带了投递标记, header_frame表示AMQP信息头的对象
def callback(channel, method_frame, header_frame, body):
channel.basic_ack(delivery_tag=method_frame.delivery_tag)
print(" [x] Received %r" % body)
# 订阅队列, 我们设置了不进行ACK, 而把ACK交给了回调函数来完成
channel.basic_consume(
callback,
queue='standard',
no_ack=True,
)
try:
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
except KeyboardInterrupt:
channel.stop_consuming()
# 关闭链接
connection.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号