ElasticSearch学习记录
一、简介
ElasticSearch是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。
Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
二、概念
1、节点[Node]:单个 Elastic 实例称为一个节点 //分为 Master Node,Data Node,Coordinating Node
2、集群[Cluster]:一组节点构成一个集群
3、索引[Index]:含有相同属性的文档集合。// 倒排索引(Inverted Index)
4、分片[Shard]:每个索引都有多个分片,每个分片都是 Lucene 索引 //一个索引分成了几份 ,Elasticsearch 跨这些分片分配数据和请求,还会跨数据节点分配分片。
5、备份[Replicas]:拷贝一份分片就完成分片的备份 //即,一个分片的副本,用于容错
6、分段[Segment]:Shard的最小存储组成部分。
7、文档[Document]:可以被索引的基础数据单位,是存储在ES中的一个JSON格式的字符串。
8、类型[Type]:索引可以定义一个或多个类型,文档必须属于一个类型
9、分词器[Analyzer]:分词组件
10、词条[Term]:索引词,指拆分出来的单个词,是一个能被索引的精确值。
recovery:代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有 couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway:代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,
当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。
es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
Master Node: 负责集群中的元数据管理,索引的创建、删除、分片分配等,不负责检索与聚合。
Data Node:数据存储节点,主要保存分片数据,如分片的CRUD、搜索、聚合。所以数据节点的负载一般较高,比较消耗CPU、IO、内存等,建议采用高配置的硬件。
Coordinating Node:协调节点,查询时的主搜索节点A(不一定是主节点),其余节点做分查询,最后做聚合。
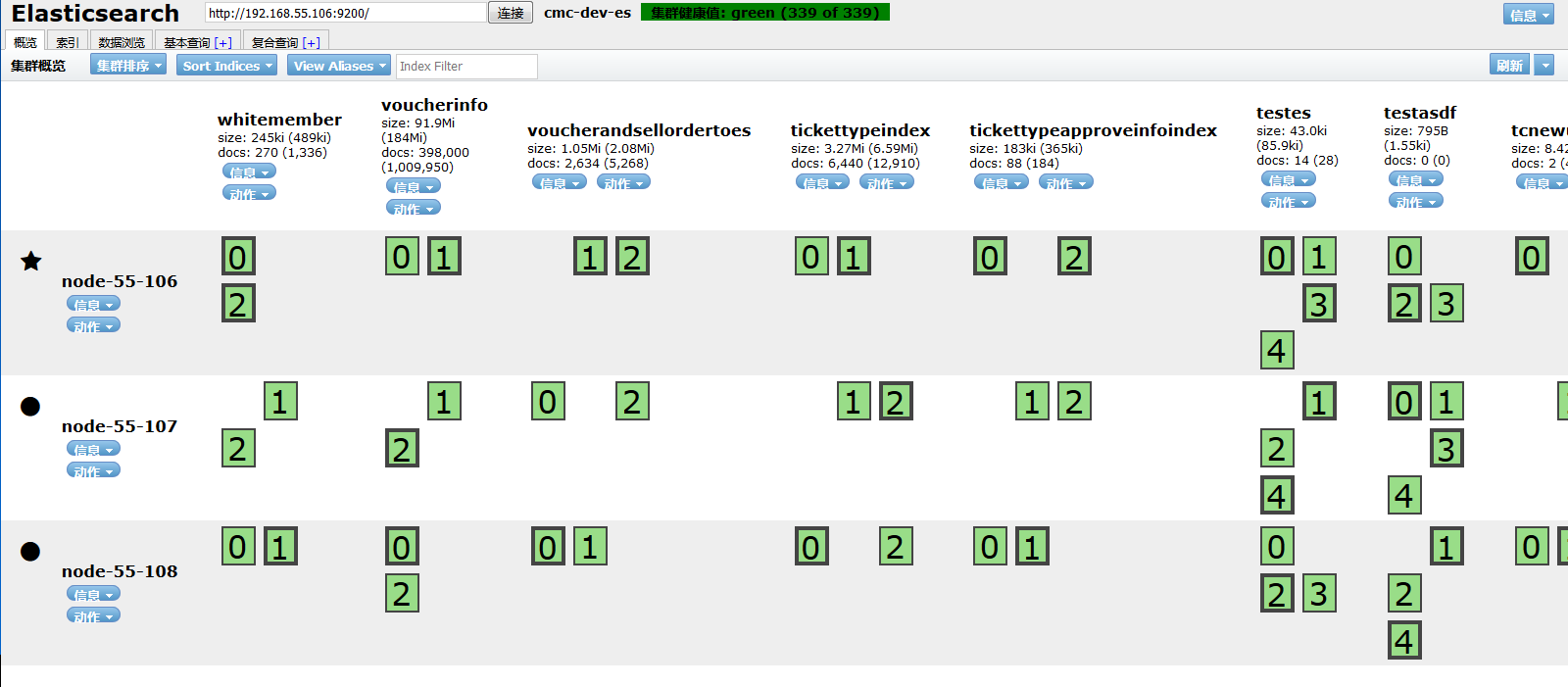
三、集群图例
elasticsearch-head
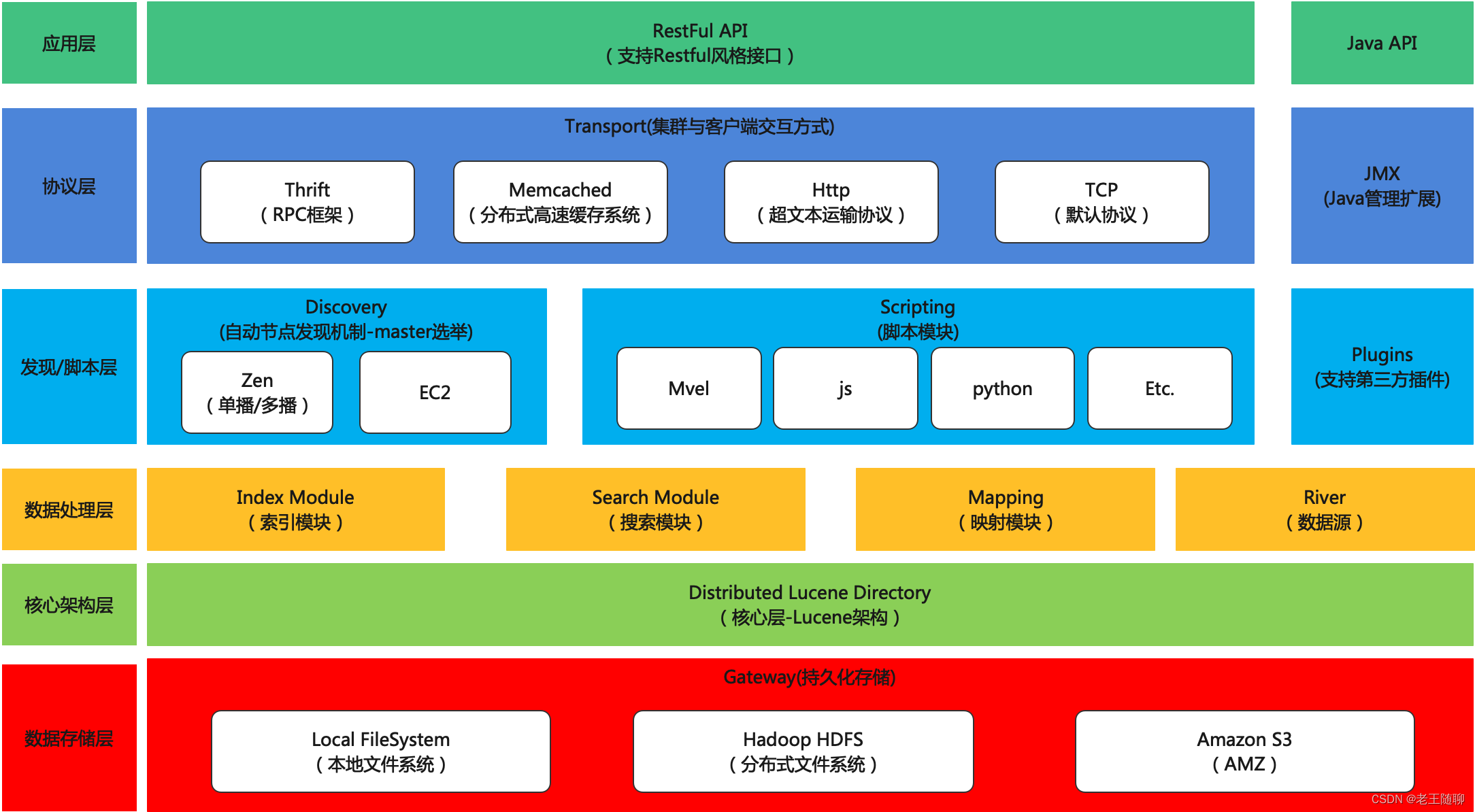
四、架构分层
五、底层
1、倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
2、分片原理
分片路由算法:hash 取模
shard = hash(routing) % number_of_primary_shards
routing值是一个任意字符串,它默认是_id但也可以自定义。
这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),
余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
设置分片数量和副本数量
// 创建指定分片数量、副本数量的索引 PUT /job_idx_shard_temp { "mappings":{ "properties":{ "id":{"type":"long","store":true}, //...... } }, "settings":{ "number_of_shards":3, "number_of_replicas":2 } } // 查看分片、主分片、副本分片 GET /_cat/indices?v
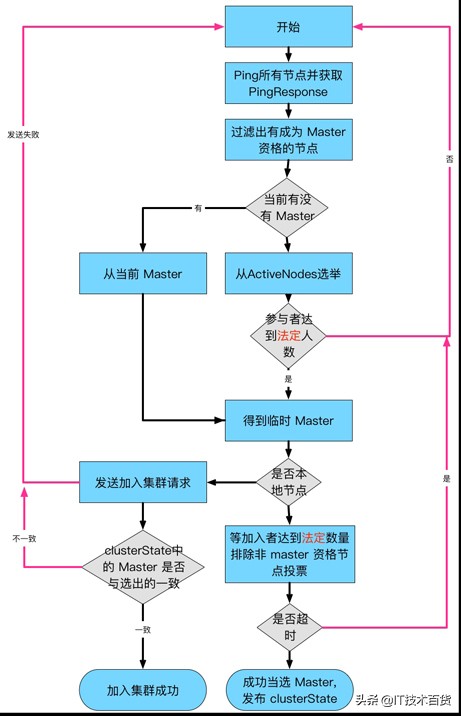
3、集群Master选举
基于 Bully 算法(霸道算法)实现。
4、脑裂(split brain)
脑裂问题,就是同一个集群中的不同节点,对于集群的状态,有了不一样的理解,同时存在多个 Leader。
5、去中心化
一个 es 集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。
es 的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,
因为从外部来看 es 集群,在逻辑上是个整体,你与任何一个节点的通信和与整个 es 集群通信是等价的。
基础资料:
ELK官网:https://www.elastic.co/
ELK官网文档:https://www.elastic.co/guide/index.html
ELK中文手册:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
ELK中文社区:https://elasticsearch.cn/
ELK-API :https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/transport-client.html
Elasticsearch入门系列~通过Java一系列操作Elasticsearch
查询语法
elasticsearch 基础 —— Query String
19 个很有用的 ElasticSearch 查询语句 篇一
elasticsearch基本操作之--使用QueryBuilders进行查询
Elasticsearch java api 常用查询方法QueryBuilder构造举例
ElasticSearch AggregationBuilders java api常用聚会查询
Elasticsearch java API (17)Aggregations 聚合 函数
Elasticsearch——分页查询From&Size VS scroll
ElasticSearch - 解决ES的深分页问题 (游标 scroll)
Elasticsearch 查询in 和 not in 的实现方式
elasticsearch系列四:搜索详解(搜索API、Query DSL)
elasticsearch系列六:聚合分析(聚合分析简介、指标聚合、桶聚合)
Elasticsearch 清空type下所有documents
工具
windows下安装ElasticSearch的Head插件
elasticsearch 安装部署以及插件head安装,和使用教程
地址:https://github.com/mobz/elasticsearch-head
git clone git://github.com/mobz/elasticsearch-head.git cd elasticsearch-head npm install npm run start open http://localhost:9100/
集群搭建
架构
高可用
腾讯云Elasticsearch集群多可用区容灾实现原理及最佳实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号