
Bookkeeper学习记录
Bookkeeper学习记录
一、简介
Apache bookkeeper是一个分布式,可扩展,容错(多副本),低延迟的存储系统,其提供了高性能,高吞吐的存储能力。Bookkeeper实现了append方式的写操作。
作为 Pulsar 的 Segment storage。
二、概念
ledger:账本,一个日志文件。
ledger storage:存储
DB ledger storage:entry 索引存储在 rockDB中。
Sorted ledger storage:entry 索引存储在 文件中。
bookie:
用来存储 Entry 数据。
我们可以把 bookie 视为一个「Key/Value database」,是一个针对整个 BookKeeper 逻辑进行设计的专用database。
Key 指上文提到的 ledger ID + entry ID 构成的标识组件。value 是指存到 ledger 里的 entry,追加和读取操作,都是针对某一个值去运行的。
格式:(LID,EID)->Entry
cursor:游标
消费状态,类似于 kafka 的 offset,但是有所不同。
以log的形式存储在 BookKeeper 中,每次消费记录追加到此日志中,可能产生消费空洞(跨序号消费),待 broker 集群恢复后,直接补充消费即可。
reder:non-durable cursor
消费状态只存储在内存中,不持久化到cursor log。
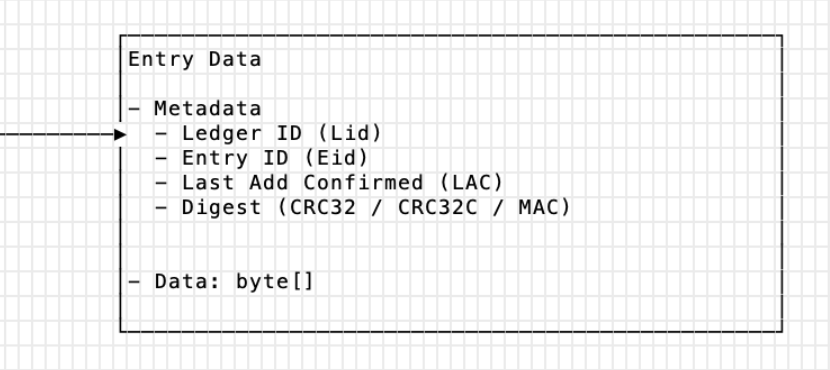
三、元数据
Ledger Metadata


Entry Metadata
四、指标
客户端在创建 ledger 时,会出现 Ensemble、Write Quorum 和 Ack Quorum 这些数据指标。
- Ensemble —— 用哪几台 bookie 去存储 ledger 对应的 entry
- Write Quorum ——对于一条 entry,需要存多少副本
- Ack Quorum —— 在写 entry 时,要等几个 response
例如:(E,W,A)->(5,3,2),表示总体是需要 5 台 bookie,但是每条 entry 只会占用 3 台 bookie 去存放,并只需等待其中的 2 台 bookie 给出应答即可。
五、存储
【写】
Journals:ledger 持久化文件,不考虑顺序,只负责追加写入来自不同 ledger 的对应的 Entry 。同步写(fsync),顺序写(不随机),低时延。数据刷盘成功之后,对应的Journal文件清除。
Write cache:缓存写入Journals的日志,并按照 LederID,EntryID 进行排序。
【读】
Entry logs:消息文件,存储 Write cache 刷盘的数据。
Index files:索引文件,存储 EntryID,以及对应Entry 在 Entry log中的位置。
Read cache:读缓存。
六、读放大、写放大、空间放大
基于 LSM-Tree(Log Structured-Merge Tree) 的存储系统越来越常见了,如 RocksDB、LevelDB。
LSM-Tree 能将离散的随机写请求都转换成批量的顺序写请求(WAL + Compaction),以此提高写性能。但也带来了一些问题:
- 读放大(Read Amplification)。LSM-Tree 的读操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次 I/O。特别是 range query 的情况,影响很明显。
- 空间放大(Space Amplification)。因为所有的写入都是顺序写(append-only)的,不是 in-place update ,所以过期数据不会马上被清理掉。
RocksDB 和 LevelDB 通过后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据),但也因此带来了写放大(Write Amplification)的问题。
- 写放大。实际写入 HDD/SSD 的数据大小和程序要求写入数据大小之比。正常情况下,HDD/SSD 观察到的写入数据多于上层程序写入的数据。
在 HDD 作为主流存储的时代,RocksDB 的 compaction 带来的写放大问题并没有非常明显。这是因为:
- HDD 顺序读写性能远远优于随机读写性能,足以抵消写放大带来的开销。
- HDD 的写入量基本不影响其使用寿命。
现在 SSD 逐渐成为主流存储,compaction 带来的写放大问题显得越来越严重:
- SSD 顺序读写性能比随机读写性能好一些,但是差距并没有 HDD 那么大。所以,顺序写相比随机写带来的好处,能不能抵消写放大带来的开销,这是个问题。
- SSD 的使用寿命和其写入量有关,写放大太严重会大大缩短 SSD 的使用寿命。因为 SSD 不支持覆盖写,必须先擦除(erase)再写入。而每个 SSD block(block 是 SSD 擦除操作的基本单位) 的平均擦除次数是有限的。
所以,在 SSD 上,LSM-Tree 的写放大是一个非常值得关注的问题。而写放大、读放大、空间放大,三者就像 CAP 定理一样,需要做好权衡和取舍。
七、顺序读写、随机读写
顺序 / 随机 I/O
顺序 I/O :指的是本次 I/O 给出的初始扇区地址和上一次 I/O 的结束扇区地址是完全连续或者相隔不多的。反之,如果相差很大,则算作一次随机 I/O。
而发生随机I/O可能是因为磁盘碎片导致磁盘空间不连续,或者当前block空间小于文件大小导致的。
顺序 I/O 比随机 I/O 效率高的原因是:在做连续 I/O 的时候,磁头几乎不用换道,或者换道的时间很短;而对于随机 I/O,如果这个 I/O 很多的话,会导致磁头不停地换道,造成效率的极大降低。
疑问:
1、LedgerID 和 EntryID 是什么时候产生的?
【答】在客户端调用 Bookie client 时产生。在Plusar中 即 Broker 调用 Bookie 时产生。
2、消息顺序
由于同一个Bookie 同一时刻只有一个writer,所以可以保证其生产的EntryID 有序。*客户端发出去的顺序*。
读取时也是如此,没有所谓的顺序,通过 LedgerID 和 EntryID 通过 key-value 的方式读取对应 bookie中的信息,bookie没有主从的概念,彼此对等。
全局逻辑有序,物理存储无序。
3、低延时
因为bookie 是对等的,没有主从概念,所以可以并行读取(根据LedgerID 和 EntryID 同时读取多个 bookie)。
4、BookKeeper 的一致性,在客户端完成?
【答】是。在Plusar中对应的就是 broker,broker 会进行一个 topic-partition的选主动作,由选出来的主broker来新建ledger并写入内容,
如果broker发生了重新选举,则新建ledger进行写入,保证永远不回写入老的ledger中。
同时 bookie 通过 fsync机制,确保同一时刻只有一个writer,从而保证了整体的一致性。
LAC 决定的,LAC存储在 Entry Metadata中。
类似 RAFT 算法。
5、负载均衡
broker负载均衡,由 broker leader 中 loadmanager 模块实现。
bookie负载均衡,由客户端BookKeeper clientLib 完成,均衡到对应的bookie中。
6、日志副本复制
同 RAFT。
待确认
1、segment 和 fragment 是一回事儿吗?
【答】
segment 可以看作是抽象, ledger 可以看作是它的一种实现。
segment 其实就是 ledger。
fragment 如 元数据第二张图,末尾部分。(0开始的存储在一个fragment,7开始的存储在另一个fragment)
2、segment 就是 entry log 吗?
【答】不是,参考问题1。entry log 是其具体表现形式。
3、segment 有固定大小限制吗?
【答】可配置,按大小,或者按照时间。
4、ledger 写满是什么意思?ledger 大小是固定的吗?
【答】大小,或者 时间。
参考资料
5 张图带你了解 Pulsar 的存储引擎 BookKeeper
深入解析 Apache BookKeeper 系列:第一篇 — 架构原理
深入解析 Apache BookKeeper 系列:第二篇 — 写操作原理
深入解析 Apache BookKeeper 系列:第三篇 —— 读取原理
翟佳:高可用、强一致、低延迟——BookKeeper的存储实现
博文推荐|Pulsar 的消息存储机制和 Bookie 的 GC 机制原理
博文推荐|Apache BookKeeper 洞察(一) — 外部共识和动态成员
LSM-Tree 的写放大写放大、读放大、空间放大RockDB 写放大简单分析参考文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号