
从源码角度理清memcache缓存服务
memcache作为缓存服务器,用来提高性能,大部分互联网公司都在使用。
前言
文章的阅读的对象是中高级开发人员、系统架构师。
本篇文章,不是侧重对memcache的基础知识的总结,比如set,get之类的命令如何使用不会介绍。是考虑到,此类基础知识网络已经有一大把资料,所以更加倾向于深入性的知识点。文章侧重的重点是对memcache的原理理清楚、在实战中自己所遇到的坑、自己的思考心得与理解。
好记性不如烂笔头,整理文章的初衷是为了加深自己的理解,对知识进行梳理,人的大脑会逐步遗忘,记下来的文字,方便以后查阅。
本文太长,一时看得晕,请挑你你需要的部分看。或者收藏起来,以后有更新部分,可以继续访问。笔者以后也会将一些疑惑的知识点,继续完善到文章中去。
文章为原创,转摘欢迎你注明出处,谢谢!
一、memcache的原理
关系型数据库的数据是放入在硬盘上的。磁盘的瓶颈是i/0(机械设备,靠磁盘片旋转来定位数据)。
而memchace利用内存的速度快,把数据存入到内存中。内存这个设备有个特点,断电后,内存里面的所有数据就会丢失。
基于这个特点,我们在架构的系统中使用memcache时,放入memcache中的数据,最终还是要在磁盘上有备份,不然丢失掉了。没地方去找了。
memcache本质就是在管理着一大片的内存区域。我们的程序去跟memcache提供的接口存储和获取数据。注意,这个内存,memcache是跟操作系统去申请内存的。
二、memcache管理内存的机制
先了解memcache的数据类型,方便理解后续知识。
memcache只提供了一种数据类型:key->value。key是字符串,value也必须是字符串。
2.1、额外知识点:操作系统与内存的关系
理解一个大前提非常重要:内存是操作系统在管理。
操作系统是责与所有硬件交换(硬盘,磁盘,内存、外设打印机等)。我们电脑插槽那个内存,也是操作系统在统一管理。
于是,在操作系统运行下的所有软件(mysql,memcache,nginx等等),需要内存的时候,都是要去跟操作系统申请内存。
软件向操作系统申请内存的办法
每次跟操作系统申请内存的最小单位是页(page)。就像称重规定最小单位是克,人自己这么约定的。
关键词:一次申请的最小单位是页(page)。
注:并不是说一次只能申请一页(4kb)。是指只能按照4k*n为单位进行申请内存。
操作系统是这样管理内存的:
把内存划分成等份大小的份(一块一块的)。这种在操作系统概念中叫做分页法。
有分页又有分段,概念容易弄晕了。其实,分段技术早于分页技术。过去是操作系统是使用分段技术来管理内存(程序运行在哪个内存区间,这就是段)
但是分段法存在一些缺陷,所以后来操作系统使用分页法了。
2.2、核心机制:slab机制介绍
memcache借鉴了linux操作系统中的slab管理器的模式,使用slab方式来管理从操作系统申请到的内存。
2.2.1、借鉴了linux的slab管理器
slab分配器主要的功能就是对频繁分配和释放的小对象提供高效的内存管理。它的核心思想是实现一个缓存池,分配对象的时候从缓存池中取,释放对象的时候再放入缓存池。
memcache也使用这样的办法:模拟实现了一个slab分配器,把从操作系统申请到内存缓存起来,即便是删除数据了,这部分内存也不会返回给操作系统,只是标识一个状态"空闲"。目的是方便下回使用。slab管理器的核心思想其实就是:对频繁使用的小对象进行缓存起来,不要释放掉。最终避免频繁的申请、释放操作造成性能问题(耗资源)。
实际上早期的memcache版本并没有采用slab管理器的思路,后来的版本才改善,使用slab机制。
memcache在使用slab机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的(对操作系统申请内存和释放内存)。 但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下, 会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
2.2.2、slab class 和slab page、chunks的关系
把相同大小的内存块,归类到一个组,这个组叫做slab class。这样子是解决了linux的slab管理器的思想。
memcache向操作系统申请内存,是以slab page为单位的,slab page的大小是1m。也就是每次申请1m(这个值可以修改,启动的时候-I参数指定,最小1K,最大128M)。
注:这个page不是操作系统概念中的page,memcahce中的page与操作系统的page不是一回事。一些文章中用page来称呼,我以前被误导了,以为是操作系统概念中的page,操作系统概念中的page,一个单位是4kb。而memcache这里是1m了。个人理解,memcache之所以要称呼为page,是因为这是从操作系统申请的内存空间,恰好操作系统分配内存给应用软件是以page为单位的。
一个slab page里面会有很多的chunks(大小相同的内存块),chunks是真正存储key->value的区域(其实就是划分出来的内存小块)。
memcache从操作系统申请内存,一次跟操作系统申请1m大小的内存(1m认为就是一个slab page)。
然后把这个1m的内存,分成相等大小的chunks。比如1m=1024kb=1024*1024b=103445504(字节)。
假设平分的大小是88个字节。那么就是103445504/88=90112个chunks。
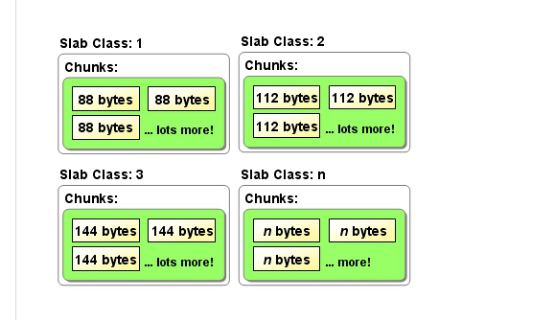
如上图:slab class 1里面都是88字节的chunks。slab class 2里面都是112字节的chunks。
一个slab class里面可能有多个slab page。至少是一个slab page(当chunks不够用的的时候,就会跟操作系统申请新的slab page加入到slab class中)。如下图表示slab class里面有多个slab page了(一个slab calss下面的每个page,其拥有的chunks数量都是一样的)。
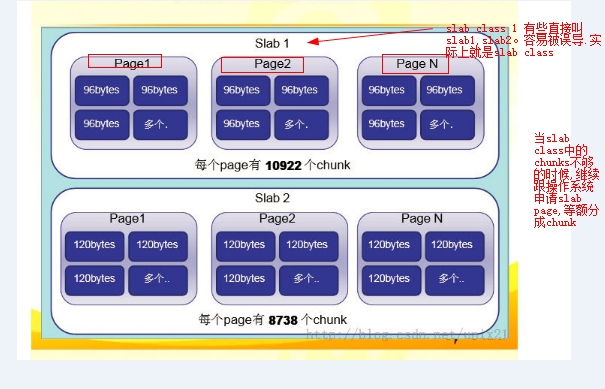
思考:每个slab class中的chunks的大小是由什么决定的呢?
由上一个slab class中的chunks大小决定。计算公式为:当前slab class中的chunks大小=上一个slab class的chunks大小*增长因子。
增长因子默认是1.25。比如上一个是288,那么288*1.25=360。下一个slab class中的chunks大小是:360*1.25=456。
注:启动memcache的时候,第一个slab class里面的chunks都是48个字节。这个值是可以配置的。
2.2.3、往memcache添加key的内部机制
添加一个key->value的步骤如下:
1、先定位到合适的slab
判断逻辑是这样:新加入一个key->value(也叫item),先计算这个key->value的整体大小。假设是118个字节。
那么去slab列表里面,寻找哪个slab能够存储下。最终找到是144字节的chunks组(slab3)能够存储。
思考:为什么是slab class 3,而不是slab class 4、slab class 5呢?
memcache的计算办法是,优先选择最小的slab class。源码在slabs.c中的slabs_clsid()函数中。这个函数传入一个容量进去,返回能够存储其容量的slab class编号。
2、定位到合适的slab后
到这一步,现在找到slab3是可以存放。于是进入到slab3里面去。那slab3里面有没有空闲空间来存储呢?
所以得先看看slab3里面是不是有空闲的chunks。memcache为每个slab维护了一个空闲链表。通俗理解就是:记录这个slab那些chunks空间是可以用的。包括过期、删除状态(标识为软删除)。
在该slab class中,会优先选择过期的chunks空间和删除掉的chunk进行来存储,其次将选择未使用过的chunk(即完全空着,从来没有用过的chunks)进行存储。
思考:这样做的好处是什么?不要污染掉真正空闲的地方。空闲的trunk是没有存储任何数据的。而被删除和过期的trunks则里面存储了数据,所以优先使用。借鉴这种思想。
通过上面步骤,在当前slab class里面假设找到了可以用的chunks,那么返回一个chunks以供使用。
假设当前slab class中没有可用的chunkns,怎么办呢?
此时,memcache就会跟操作系统去申请内存了。默认一次申请1m的内存空间。申请1m。然后继续切分。
注意:关于切分,很多这里没有说透,以前我被误导了。这时候其实不是新开slab class。是对当前的slab class 3进行的操作:
当前的slab class 3里面的chunks都是144个字节。那么好,新申请的1m内存,就按照144个字节来切分。计算方法列出来看看:
1m=1024k=1024*2014b=103445504字节。
103445504/144字节=718317个块(chunks)。
这718317个chunks,就会加到slab class 3里面去。
三、memcahce的监控
使用一个php语言开发的界面管理工具。名称叫做memadmin。
下载地址:http://www.oschina.net/p/memadmin

根据实战经验,要注意的一个监控项,就是LRU数。通过这可以看出,是不是发生了内存不够的情况了。如下图:
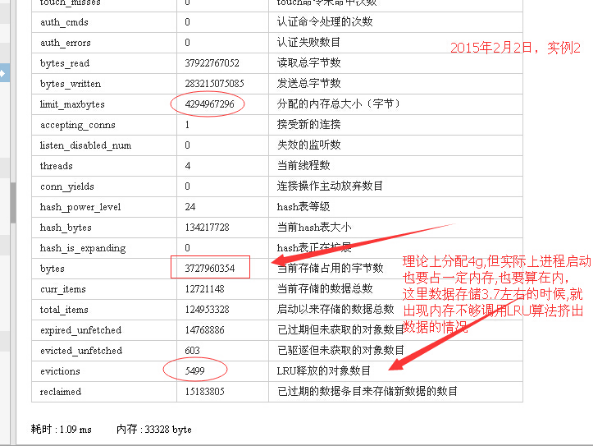
另外一个项,bytes,当前存储占用了多少字节。这个项的值,我们会被误导。
比如显示占据的存储空间是3.7g。远远没有达到最大分配的内存数4g。但是这个阶段却发生了lru剔除数据的现象。
其实有些slab class占据着内存空间。这些内存空间并没有机会被新加入的key->value来使用,于是导致了某些slab class无法继续申请新的内存的现象。
而lru只是针对当前访问的slab class进行的。并不是针对全局(所有slab class)进行。
通俗点理解如下:
slab class 1
slab class 2
slab class1 中有大量空闲的内存空间,而新加入的key->value都是进入到slab class 2去。slab class2中没有空闲的内存空间了。 memcache就跟操作系统申请内存,操作系统没有足够的内存给予memcache(发生LRU算法的大前提后续有文字解释),这个时候 memcache迫不得已了,就会执行lru算法。
研究这里的统计值是怎么算出来的,可以避免被误导
这个统计值的计算标准是怎么样的? 什么时候会更新呢?
1、添加一个item成功后,会增加统计值。
每次添加一个key,就会让这个统计项的值增加。可以这么理解:增加一个key->value成功后,就更新掉那个总数值。比如新增加的 key->value大小是220个字节,而恰好定位到slab class 3。假设里面的chunks大小是260个字节。
实际上统计总数的时候,就会增加260个字节。虽然只占220个字节。但是chunks的机制,260-220=40个字节,也是空着的,不能被拿来使用(相当于内存碎片了),那么会按照260个字节来说。
2、delete命令和get命令的时候,会减小统计值。
经我测验:只有delete和get命令时才会将占据的内存统计值减小值。get命令,会判断当前读取的key是否过期,若过期了,则会把对应的内存空间标识为可用状态,同时就会将统计总数值减小。
测验思路如下:故意添加一个失效期只有50秒的key,这个key的大小是298个字节。然后去memcache命令行使用stats命令查看内存占用的空间(或者memadmin界面工具也可以)。因为添加了一个值,于是发现统计总数增加了298个字节。
50秒过后,再去运行stats命令,发现统计值并没有变化。
当我使用get命令查询这个key时,memcache会检查这个key已经过期,则会自动更新掉统计值。delete命令也是类似。
3、flush_all的用途是将所有的key都设置为过期,运行这个命令所占内存会不会清0呢?
结论:运行flush_all命令后,统计值是不会有变化的。
解释:使用flush_all是不会访问到所有key的。只是设置一个类似于这样的标记:flush_all_time=记录上一次失效的时间。
思考:从上面做实验来看,这个统计所占据的内存值,只能做一个大概的。并不不是很准确的。比如一个item占着内存空间260个字节,实际上这个item已 经过期了。由于一直没有机会使用get命令读取这个item,那么memcache的总数统计项中,并没有减掉这个260个字节。所以看起来统计值是接近 4g了。我们会觉得,内存是不是不够用了,其实不必担忧,重点是看有没有发生LRU计数项。这个是很重要的数据。
四、memcache的长连接实验
memcache服务端提供了tcp协议接口来操作。所以paython,java,php都可以基于这个协议来与memcache通信。
php链接memcache服务端,使用的是memcached扩展(客户端)。
客户端链接memcache服务端,有长连接和短连接两种方式。
4.1、短连接与长连接的比较
到底哪种方式效率高? 性能更好呢?
笔者认为是长连接。既然设置了长连接,那么肯定有它用武之地。当遇到大量的并发请求的时候,长连接可以发挥出性能优势。主要是基于:tcp连接数会更少。如果大量的客户端连接memcache服务,在linux可以看到很多的tcp连接。
我的测验办法是:使用ab命令去发起大量请求到一个php文件。而这个php文件就是去与memcache服务进行交互。马上在linux使用命令netstat -n -p | grep 11211查看11211这个端口的tcp连接情况。
使用短连接,看到效果如下:
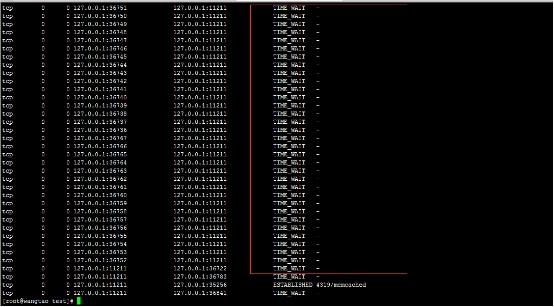

客户端频繁地与memcache服务,实际上就是一个这样的过程:建立连接>释放连接。
遇到大量的请求,频繁的建立>释放tcp连接,是需要耗费linux文件句柄的。会使得linux服务器文件句柄达到极限。处理不过来。
另外导致的问题是,cpu的负载高。建立和释放释放资源(连接),实际上是比较耗费cpu资源的。大量重复建立和释放连接,会让cpu的负载变高。
如下命令可以统计指定端口的tcp连接总数:
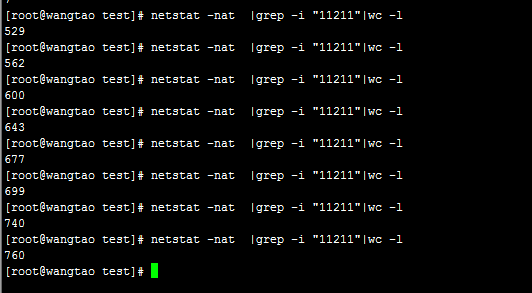
当我使用ab命令并发请求php的时候,从上图看到11211端口的tcp连接数一直在增加。
使用长连接的效果,同样使用ab命令并发请求php,
长连接的测验办法:可以在linux通过命令,看到即便是请求结束后,还是能够看到这些连接。
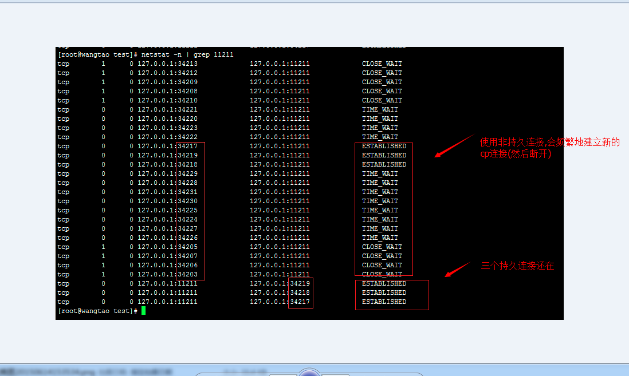
上图的状态为established。就是一直在保持连接状态的tcp连接。
当使用长连接的时候,在linux服务端看到的连接总数,也比较少。
可以预先开多少个连接。
4.2、长连接的优势
思考:什么情况下使用长连接,什么情况下使用短连接呢?
高并发请求下,才能看到长连接带来的明显效益:tcp连接复用、资源消耗少(主要是cpu负载)。
很多人表面看觉得,使用长连接(持久连接),会占着资源一直不释放掉。消耗太多资源。从直觉上,更加喜欢建立>断开连接的操作方式,明显感觉会释放资 源,所以会减少资源消耗。我们可能以为,来2000个请求,使用持久连接,就会建立2000个连接,即便请求完毕后,2000个连接也一直维护着。于是比 较耗费资源。
持久连接,是一种复用技术。预先创建500个连接,放入连接池里面。当有请求来的时候,先去连接池里面看,是 否有空闲状态的连接,有就拿过来使用。若没有可用连接,则创建一个连接,用完这个连接后,是释放掉,还是接着放入连接池呢?可以进行配置的。可以配置连接 池中保持多少个连接在等待请求。
并不是说,2万个客户端请求,那么就要一直维护着2万个连接。实际上连接池里面维护的可能是1000个连接(可以自己配置),连接池中这1000个连接是与服务端(比如mysql、memcache)维持着通信状态的。
在计算机中有一个经验:频繁地创建资源和释放资源(比如建立连接),带来的开销比维护这些资源都要高.维护只需要在内存中发送心跳包,需要的时候从内存中调 用出,由于已经在内存中了,不用去创建资源了,直接从内存中调出来的数据很快的。操作系统linux中著名的slab机制管理内存空间,就是基于这个原来 做的。slab管理机制,会将内存区域自己维护起来,减少频繁地申请和释放内存资源,内存其实没有释放,只是标识了一个状态:可用、不可用。
需要的时候,直接拿过来使用(避免申请耗费cpu资源)。
现在发现,学到一个思想:频繁使用的资源,要缓存起来。目的是避免频繁地去申请、释放。设计一个连接池方案,是一种成熟的技术,不会那么弱智。
平时大部分应用都用不上连接池
平时我们使用短连接,是建立tcp连接,用完后释放掉tcp连接。我们习以为常,实际上是因为大部分应用不会遇到连接数瓶颈(建立连接用完只要快速释放,看起来速度很快),所以没有使用连接池带来的好处。
这很像http请求场景:大量的http请求80端口。建立连接>传输完数据>断开连接,也是一次短连接的过程。我们看不到问题。
我们使用数据库连接池技术(长连接就是维护着一个连接池,叫法不同),平时开发中并不需要使用,而是在高并发情况下,才会看到使用数据库连接池带来的明显效果。
连接池技术是针对高并发情况下进行的优化,在没达到连接瓶颈的时候,用了跟没用,看不出明显速度区别的。
五、思考与解惑
思考1:配置memcahce的最大内存空间为2g。那么,memcache是不在是启动的时候,就跟操作系统申请那么多的内存空间呢?
不是。如果会一开始就跟操作系统申请这么多的内存。这样的坏处明显。比如memcache存储的数据量一直都维持在1g的容量,而memache就跟操作申请2g内存,完全是浪费内存资源。memcache默认会创建n个slab cass。但实际上每个slab class也只跟操作系统申请了1m的内存。
memcache占有多少内存,key->value的数据越来越多,跟操作系统申请的内存越来越多。
思考2:当数据过期时,或者是说将数据删除后,占据内存有没有被释放掉呢?
答案:并没有。memcache只是对自己维护的内存区域标识了一个状态"空闲"、"已被使用"。其实memcache已经从操作系统申请到的内存,比如占了1g了。并没有返回给操作系统的。只有等到memcache进程终止掉了,操作系统会自动回收。
memcache其实是故意不返回的,借鉴了slab管理器的思想。内存没有释放给操作系统,而是自己维护着一个状态。下一次其他数据需要存储的时候,直接拿到这些空闲的内存存储数据即可了。
思考3:memcache对数据的过期是如何检测的?
网上有资料,提到是懒惰删除法。就是在访问这个key(使用get命令读取)的时候,才去判断此key是否过期。若过期了,则将其占据了内存区域(chunk块)标识为空闲状态。
之所以叫做懒惰法,笔者这样理解:平时并不去主动扫描所有key的过期时间,需要用到这个key的时候,才去判断过期。这是懒人做法。如果是勤奋的做法,一般开一个垃圾回收线程,定期去扫描key,发现过期了,就将此块内存区域标为"空闲"状态。但是这样专门开一个线程去扫描,需要耗费cpu资源。
懒惰删除法的缺点是:如果这个key一直没有去访问,那么就永远不知道有没有过期(memcache不会标识其内存区域为空闲状态)。那么这块内存,没法让其他key加入进来使用。 造成了内存的浪费。
redis吸取了这个教训,做了一点改进:每次读取key的时候,选定一个范围内的数据扫描一次。
思考4:LRU列表、空闲chunks列表、空闲chunks总数统计
笔者在看那个LRU算法的时候,网上一些资料,看晕了。需要区分一下概念,源码才能看得明白逻辑:
添加数据的时候,定位到合适的slab class后(比如slab class3),会去LRU列表中,拿最末尾的一个item,若其时间已经过期,则直接返回内存空间使用。
若找不到,则去slab class的空闲空间拿内存空间。
得理清楚上面一些概念,不然搞不明白。从网上弄了一张比较好的图,根据自己的理解,在图中自己加了一点说明:
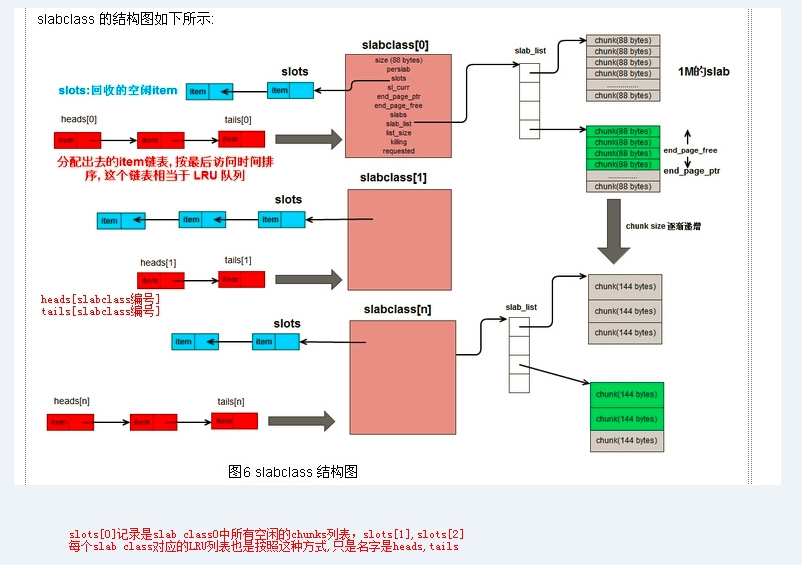
LRU列表: 记录着一个slab class中最近访问的item,按照最近访问时间进行排序。
访问这个列表,有两种方式:一种是使用tails,这是从尾部开始访问,得到的访问时间离现在最远的item; 另外一种是使用heads,从头部开始访问。得到的访问时离现在最近的item。
tails[id],id是一个整数,是slab class的编号。每个slab class都有一个tails队列。使用tails是从尾部开始访问,如果需要从头部开始访问这个列表,那么就使用heads[i]。
注:尾部的数据,就是相对没那么频繁访问的,于是memcache优先从尾部拿一个item来判断是否过期。
空闲item列表slots:源码中完整引用是p->slots,p就表示某个指定的slab class。slots中记录的是可以拿来使用的item(记录的是哪些,是一个列表)。比如一个item被删除,或者代码检测到过期时间已经过期,那么都会把item加到这个空闲列表中去。
sl_curr:源码中完整引用是p->sl_curr,存储是一个整数。统计当前有slab class有多少个空着的item。比如有5个,那么这个项的值就是5。memcache源码中的解释为:total free items in list
上述项的值更新是怎么进行的? do_slabs_free()函数中会有如下代码:
p->slots = it;//slots是存储要回收的空闲items,加到里面去
p->sl_curr++;//给当前slab的空闲item个数+1 。
思考5:LRU算法是在什么时候才会执行?
只有当申请不到内存的时候。才去做LRU算法。其实这是一种迫不得已的办法:没有内存可用了。为了保证数据能存储进去,只能踢下一些不太使用的数据了
注:有个配置-M可以配置memcache内存不够的时候,禁止数据存储进去,而不是执行LRU算法。不过一般不怎么用,因为数据存储不进去,使用体验不好。
怎么样才算申请不到内存空间呢? 两种情况可能会出现:
1、memcache去跟操作系统申请内存,一方面是操作系统没有足够的内存分配给memcache(总共4g内存,操作系统没有足够内存分配了)。
2、由于memcache启动的时候配置了一个最大限制内存(启动时的-m参数),目前memcache占据的内存,已经超过这个数了。
示范:
/usr/local/memcached/bin/memcached -d -m 1024 -u root -l 127.0.0.1 -p 11211
-m指定了2014,单位是m。也就是最大1g内存。
更加细化到什么命令执行:在执行添加item操作的时候,才有可能去执行LRU算法。get操作不会去执行LRU算法。get命令记得回去判断key的过期,然后标识为过期状态,标识为过期状态,就加到队列中了。这样它占据的内存就可以腾出了使用了。
添加数据涉及到的LRU思路,看源码,LRU算法是在items.c文件中的do_item_alloc()中执行。笔者通过阅读源码理清楚了如下步骤:
步骤1、do_item_alloc()是在新增加key的时候调用的。这个函数的作用是:传入一个key->value,然后函数会计算key->value所需要的大小,比如所需空间是280个字节。那么就会去slab calss列表里面寻找一个能够存储下的slab class。找到一个slab class后,就会进入到slab class里面去搜索了:从LRU列表(LRU列表前面有解释)的尾部,弹出末尾的一个item。判断它的过期时间,如果这个item已经过期,正好可以拿其内存空间来使用。
步骤2、如果第一步拿到的item没有过期,然后才考虑,从当前slab class里面获取空闲的chunks块。
步骤3、如果当前slab class里面没有空闲的chunks,则会申请一个slab page(1m大小)放入到当前slab class里面去 (封装在do_slabs_alloc()中实现)。
步骤4、如果还不成功,那么就执行LRU算法了:将LRU列表中,从尾部踢下一个item。LRU列表是按照最近访问时间来排序的,从尾部踢的一个item,相对来说是最不活跃的item了。
注:每次剔除一个,都会让计数器(监控中的evitions项)加1的。于是就有我们在监控上去看evitions项的值。
上述步骤,每进行一次若没有拿不到item空间,那么会会重复进行5次(封装在一个for循环里面,循环5次)。
函数调用关系依次为:
do_store_item()>>do_item_alloc()>>>slabs_alloc()>>do_slabs_alloc()>>do_slabs_newslab()
do_store_item()在memcache.c文件
do_item_alloc()在items.c文件
slabs_alloc()在slab.c文件
do_slabs_alloc()在slab.c文件
do_slabs_newslab()在slab.c文件
这部分的源码阅读
看memcache源码,在文件items.c文件中,里面的注释是我根据自己理解加的。


/* +----------------------------------------------------------------------- 整个函数的目的是:寻找合适的slab存储一个item,最终返回item空间的的引用 +----------------------------------------------------------------------- 使用场景:保存一个key->value操作的时候。 +-------------------------------------------------------------------- 给定一个key,计算key需要的空间。 把大小传入slabs_clsid()函数,然后返回slab的编号。如果找不到适合大小的slab,则整个返回0 会先计算key->value所需空间,然后寻找合适的slab class +----------------------------------------------------------------------- */ //源码资料参考:http://blog.csdn.net/caiyunl/article/details/7878107 item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes, const uint32_t cur_hv) { uint8_t nsuffix; item *it = NULL; char suffix[40]; //给suffix赋值,并返回item总的长度(除去cas的)。总长度用于决定该item属于哪个slabclass //疑问:value的长度呢? nbytes参数 size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix); /* 从宏ITEM_ntotal可以看出一个item 的实际长度为 sizeof(item) + nkey + 1 + nsuffix + nbytes ( + sizoef(uint64_t), 如果使用了cas) */ if (settings.use_cas) { ntotal += sizeof(uint64_t); } //传入大小,返回一个适合此大小存储的slab编号 unsigned int id = slabs_clsid(ntotal); if (id == 0) return 0;//返回0,则表示从目前的所有slab列表里面找不到适合存储的slab class(因为item太大了) //外面调用这个函数判断,只是设置。如果没有找到合适的slab,为什么没有去创建一个slab呢? //do_slabs_newslab /* 每个 slabclass 都拥有一些 slab, 当所有 slab 都用完时, memcached 会给它分配一个新的 slab, do_slabs_newslab 就是做这个工作的. */ mutex_lock(&cache_lock); //优先去slab的队列尾部寻找过期的item空间,意思是想优先使用这些空间来替换 /* do a quick check if we have any expired items in the tail.. */ int tries = 5;//尝试多少次 int tried_alloc = 0;/*记录是否申请内存失败,根据这个值判断*/ item *search;//这里只是初始化,值在后面赋值 void *hold_lock = NULL; rel_time_t oldest_live = settings.oldest_live;//使用flush_all命令相关的设置 /*从尾部开始搜索,因为尾部的time总是最早的,所以就是一种LRU实现 */ search = tails[id];//每个slab有个自己的tails数组,id就是slab的编号 /* tail这个数组就是维护的是一个slab按照访问时间排序的item,应该只保留部分数据。到时候执行lru算法也踢掉这里面的item。也就是time时间最小的算是距离现在时间最远的,就会被踢掉。 */ /* We walk up *only* for locked items. Never searching for expired. * Waste of CPU for almost all deployments */ /* 循环5次:从最近访问的item队列(tails[id]),尾部开始遍历5个item看看。 这里就是一种lru算法。最近最少使用,其实就是根据访问时间来排序成一个队列。 */ for (; tries > 0 && search != NULL; tries--, search=search->prev) { uint32_t hv = hash(ITEM_key(search), search->nkey, 0); /* Attempt to hash item lock the "search" item. If locked, no * other callers can incr the refcount */ /* FIXME: I think we need to mask the hv here for comparison? */ if (hv != cur_hv && (hold_lock = item_trylock(hv)) == NULL) continue; /* Now see if the item is refcount locked */ if (refcount_incr(&search->refcount) != 2) { refcount_decr(&search->refcount); /* Old rare bug could cause a refcount leak. We haven't seen * it in years, but we leave this code in to prevent failures * just in case */ if (search->time + TAIL_REPAIR_TIME < current_time) { itemstats[id].tailrepairs++; search->refcount = 1; do_item_unlink_nolock(search, hv); } if (hold_lock) item_trylock_unlock(hold_lock); continue; } /* Expired or flushed */ /* 先检查 LRU 队列中最后一个 item 是否过期, 过期的话就把这个 item空间拿来使用 */ if ((search->exptime != 0 && search->exptime < current_time) || (search->time <= oldest_live && oldest_live <= current_time)) { /*优先选择最近最少访问列表中已经过期的一个item来使用*/ itemstats[id].reclaimed++;//替换次数加1,显示在stats命令中的 reclaimed项 if ((search->it_flags & ITEM_FETCHED) == 0) { itemstats[id].expired_unfetched++; } it = search;//把这个空间返回使用,实际上就是替换掉已经过期的item slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal);//虽然属于同一个slabclass,但是长度仍可能不一样,需要修改一下 do_item_unlink_nolock(it, hv); //将过期的item从双向链表和hash表中除去 /* Initialize the item block: */ it->slabs_clsid = 0; } else if ((it = slabs_alloc(ntotal, id)) == NULL) { /* 1、找不到已经过期的chunks空间(),则slabs_alloc()函数是从当前选择的slabclass获取空闲的item空间 2、slabs_alloc()如果找不空闲的chunk空间,会去跟操作系统申请一个page加到当前slab class里面 3、如何这样申请内存空间失败的话:就把 LRU 队列最后一个 item 剔除, 然后分配出来使用(返回) */ tried_alloc = 1;/*记录是否申请内存失败,1标识为失败*/ if (settings.evict_to_free == 0) { //==0表示关掉了LRU踢下线算法,直接不允许存入数据进memcache itemstats[id].outofmemory++; } else { /* 这部分代码就是lru的踢下操作了:执行到这里的时候,已经是迫不得已了: 在当前slab class过期的空间没找到、空闲的空间也没有、跟操作系统申请内存也失败 最下策的办法:甭管了,从LRU列表中踢一下一个来使用吧。 */ itemstats[id].evicted++;//当前的slab被踢下去的总数加1 itemstats[id].evicted_time = current_time - search->time;//最近发生踢下去操作的时间 if (search->exptime != 0) itemstats[id].evicted_nonzero++; if ((search->it_flags & ITEM_FETCHED) == 0) { itemstats[id].evicted_unfetched++;//被剔除的数据中,统计这种数据:从来没有被获取过一次的 } it = search; slabs_adjust_mem_requested(it->slabs_clsid, ITEM_ntotal(it), ntotal); /* 把这个 item 从 LRU 队列和哈希表中移除 */ do_item_unlink_nolock(it, hv); /* Initialize the item block: */ it->slabs_clsid = 0; /* If we've just evicted an item, and the automover is set to * angry bird mode, attempt to rip memory into this slab class. * TODO: Move valid object detection into a function, and on a * "successful" memory pull, look behind and see if the next alloc * would be an eviction. Then kick off the slab mover before the * eviction happens. */ /*如果开启了自动reassign机制,则每发生内存不够挤下去情况,就执行一次优化,是不是异步的,还是同步进行,如果是同步是不要卡在这里等操作完毕呢? 添加数据会受到影响*/ if (settings.slab_automove == 2) slabs_reassign(-1, id); } }// end if refcount_decr(&search->refcount); /* If hash values were equal, we don't grab a second lock */ if (hold_lock) item_trylock_unlock(hold_lock); break; } //end for 循环 /* tried_alloc为1,表示申请分配内存失败。tries表示尝试的次数,总共是5次尝试 这里再尝试一次(看空闲chunks、跟操作系统申请内存),增加成功几率 */ if (!tried_alloc && (tries == 0 || search == NULL)){ it = slabs_alloc(ntotal, id); } if (it == NULL) { itemstats[id].outofmemory++;//内存不够? mutex_unlock(&cache_lock); return NULL; } assert(it->slabs_clsid == 0);//为假,则终止代码执行 assert(it != heads[id]); /* Item initialization can happen outside of the lock; the item's already * been removed from the slab LRU. */ //初始化一些item属性,可以看出这里只是申请了data所需要的空间,而未给data真正的赋值,并且将其连入到LRU和hash表的操作也不在这 it->refcount = 1; /* the caller will have a reference */ mutex_unlock(&cache_lock); it->next = it->prev = it->h_next = 0; it->slabs_clsid = id;//设置所属的slab编号,传入的item,寻找到了合适的slab编号 DEBUG_REFCNT(it, '*'); it->it_flags = settings.use_cas ? ITEM_CAS : 0; it->nkey = nkey; it->nbytes = nbytes; memcpy(ITEM_key(it), key, nkey);//由第二个参数指定的内存区域复制第三个参数长度的字节到第一个参数指定的内存位置去 it->exptime = exptime;//设置item的过期时间 memcpy(ITEM_suffix(it), suffix, (size_t)nsuffix); it->nsuffix = nsuffix; return it; }
思考6:定位slab时,使用最小slab class的原因
看memcache源码,它在寻找slab的时候,有个原则:优先寻找最小的slab进行使用。比如寻找到4个slab是可以存储的,那么会使用最小的那个slab。
源码如下(在slabs.c中):
/* 根据传入item的大小,根据大小查找合适的slab,最终返回slab的编号 */ unsigned int slabs_clsid(const size_t size) { int res = POWER_SMALLEST;//最小slab个数,默认是1,定义在memcached.h头文件中 if (size == 0) return 0; while (size > slabclass[res].size){ //slabclass[res].size每次循环往后面移, 遍历所有的slab,直到找到比它空间大的slab if (res++ == power_largest) /* won't fit in the biggest slab */ //永远不要使用最后一个slab return 0; } /*返回0,则表示找不到适合目前item存储的slab。 res++ == power_largest表示已经是最最后的那个slab class了,那么表明已经找不到适合存储目前item的slab class。*/ return res; }
之所以永远使用是最小的slab,从第一个slab遍历到最后一个slab,始终找到最小的slab来存储,是基于这个特点:每新创建一个slab, chunks的大小都会按照步长来增加
比如第一个slab里面的每个chunks大小是96字节,第二个会是120,第三个152字节,第四个192字节。
思考7:启动memcache进程的时候,可以指定默认创建多少个slab class呢?
slabs.c中slabs_init()函数是初始化slab。看代码是初始化200个。但是实际做试验,发现并没有初始化这么多。
递增趋势。最大一个的slabclass里面的chunk不会大于一个Page的大小(默认1M)。
思考:实际上slab_init()就已经初始化200个slab class了。
只是还没有跟操作系统去申请内存给每个slab class。启动的时候,可以打开预先分配机制。这样启动memcache进程,就会为200个slab class跟操作系统申请内存。
既然已经200个slab class。那么也完全够用了。可以设置刚开始的chunks大小增长的因子默认是1.25。可以修改的。
第一个slab class中的chunk大小是48个字节,然后按照增长因子递增(1.25)。48*1.25*1.25*1.25
199次方。
思考8:如何设置第一个chunks的大小以及增长因子
启动时候-n参数指定chunks的字节数,-f参数指定增长因子
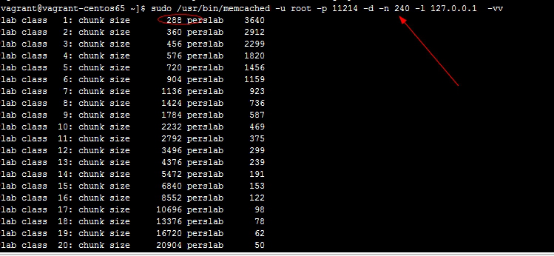
/usr/local/memcached/bin/memcached -d -m 512 -n 240 -l 127.0.0.1 -p 11211 -u root -f 1.48 -vv
--I 指定跟操作系统申请的page大小。
比较重要的几个启动参数:
-f:增长因子,chunk的值会按照增长因子的比例增长(chunk size growth factor).
-n:每个chunk的初始大小(minimum space allocated for key+value+flags),chunk大小还包括本身结构体大小.
-I:每个slab page大小(Override the size of each slab page. Adjusts max item size)
-m:现在memcache的数据最大占据内存(max memory to use for items in megabytes)
思考:理论上是使用 -n 240指定了第一个slab class的中的chunks大小是240个字节。但是启动后,实际上却是288个字节呢? 截图如下:
思考9:定位不到合适的slab class咋办
假设现在存储的item大小是480个字节。由于slab class列表里面最大的chunks也只有260个字节。那么就没有合适的slab class供存储。此时算是定位不到合适的slab class了,咋办?此时memcache,就要新创建slab class吗?
据目前理解是,按照最大的slab class里面的chunks来决定,里面的chunks假设大小是260个字节。如果按照这样,那么就会是260*1.25=325 。
1.25这是增长因子。如果这样子得到是325个字节。如果新创建的slab还是按照325个字节来分chunks。那么还是不够存储当前的480个字节的。所以,我猜测,应该是有其他思路的。
原因是?待解答!
思考10:重新对一个key->value值保存,所需的内存空间增大,会如何办?
假设场景:原来一个key->value计算出大小是需要容量280个字节。恰好存入到slab class3里面。slab class3 里面的所有chunk大小是300字节。但是现在要针对原来的key值,重新保存数据。value的值增大了,于是重新计算key->value需要330个字节。那存储到slab class 3里面是存不下了。那会怎么操作呢?难道将slab class3里面的key移动到新的slab class里面去吗?
待解答。等待看源码理清楚。

