N80-42-王滔 第十周作业
哨兵机制实现原理,并搭建主从哨兵集群。
高可用的定义一般有以下两个解释:
解释1:它与被认为是不间断操作的容错技术有所不同。是目前企业防止核心系统因故障而无法工作的最有效保护手段
解释2:高可用一般指服务的冗余,一个服务挂了,可以自动切换到另外一个服务上,不影响客户体验。
主要就是当我们服务存在异常的时候,可以自动进行容错或者抵抗异常,从而达到不影响到用户正常使用的一种技术
原理
哨兵是一个分布式系统,可以在一个架构中运行多个哨兵进程,这些进程使用流言协议(gossip protocols)来传播Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master。哨兵模式的具体工作原理如下:
1、心跳机制:
(1)Sentinel 与 Redis Node:Redis Sentinel 是一个特殊的 Redis 节点。在哨兵模式创建时,需要通过配置指定 Sentinel 与 Redis Master Node 之间的关系,然后 Sentinel 会从主节点上获取所有从节点的信息,之后 Sentinel 会定时向主节点和从节点发送 info 命令获取其拓扑结构和状态信息。
(2)Sentinel与Sentinel:基于 Redis 的订阅发布功能, 每个 Sentinel 节点会向主节点的 sentinel:hello 频道上发送该 Sentinel 节点对于主节点的判断以及当前 Sentinel 节点的信息 ,同时每个 Sentinel 节点也会订阅该频道, 来获取其他 Sentinel 节点的信息以及它们对主节点的判
2、 判断主主机是否下线
3、 基于Raft算法选举领头sentinel
4、 故障转移:
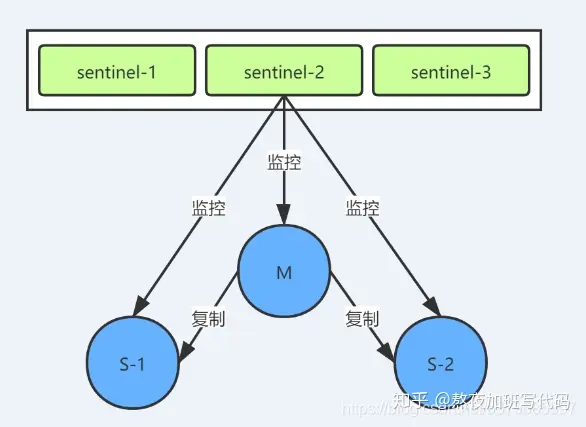
Sntinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
原理:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性
(最少一主一从 设置哨兵高可用 就是从主机一直监控主主机 检测住住挂了 就从主机就上位了 )
打开哨兵配置文件 vim sentinel.conf #端口默认为26379。 port:26479 #关闭保护模式,可以外部访问 protected-mode:no #设置为后台启动 daemonize:yes #日志文件 logfile:./sentinel-26479.log #指定主机IP地址和端口,并且指定当有2台哨兵认为主机挂了,则对主机进行容灾切换 sentinel monitor mymaster 173.x.x.x 6479 2 #当在Redis实例中开启了requirepass,这里就需要提供密码 sentinel auth-pass mymaster 230216 #这里设置了主机多少秒无响应,则认为挂了 sentinel down-after-milliseconds mymaster 3000 #主备切换时,最多有多少个slave同时对新的master进行同步,这里设置为默认的1 sentinel parallel-syncs mymaster 1 #故障转移的超时时间,这里设置为三分钟 sentinel failover-timeout mymaster 180000 #sentinel工作目录(默认/tmp) dir ./sentinel-work-26479 #守护进程pid存储文件(默认位置 /var/run/redis-sentinel.pid) pidfile /var/run/redis-sentinel_26479.pid # 当在Redis实例中开启了requirepass,所有连接Redis实例的客户端都要提供密码 # sentinel auth-pass <master-name> <password> sentinel auth-pass mymaster 230216 其他两个也设置一样 这样主机挂了 其他就选举新的的主机
总结redis cluster工作原理,并搭建集群实现扩缩容
扩容原理
- redis cluster可以实现对节点的灵活上下线控制
- 3个主节点分别维护自己负责的槽和对应的数据,如果希望加入一个节点实现扩容,就需要把一部分槽和数据迁移和新节点
-
准备新节点
-
准备两个配置文件redis_6379.conf和redis_6380.conf
-
daemonize yes port 6379 logfile "/var/log/redis/redis_6379.log" pidfile /var/run/redis/redis_6379.pid dir /data/redis/6379 bind 10.0.0.103 protected-mode no # requirepass 123456 appendonly yes cluster-enabled yes cluster-node-timeout 15000 cluster-config-file /opt/redis/conf/nodes-6379.conf # 另一份配置文件 daemonize yes port 6380 logfile "/var/log/redis/redis_6380.log" pidfile /var/run/redis/redis_6380.pid dir /data/redis/6379 bind 10.0.0.103 protected-mode no # requirepass 123456 appendonly yes cluster-enabled yes cluster-node-timeout 15000 cluster-config-file /opt/redis/conf/nodes-6380.onf
创建文件夹
mkdir -p /var/log/redis
touch /var/log/redis/redis_6379.log
touch /var/log/redis/redis_6380.log
mkdir -p /var/run/redis
mkdir -p /data/redis/6379
mkdir -p /data/redis/6380
mkdir -p /opt/redis/conf
[root@node04 redis]# bin/redis-server conf/redis_6379.conf
[root@node04 redis]# bin/redis-server conf/redis_6380.conf
[root@node04 opt]# ps -ef | grep redis
root 1755 1 0 19:06 ? 00:00:00 redis-server 10.0.0.103:6379 [cluster]
root 1757 1 0 19:06 ? 00:00:00 redis-server 10.0.0.103:6380 [cluster]
新节点加入集群
root@node01 opt]# redis-cli -c -h 10.0.0.100 -p 6380
10.0.0.100:6380> cluster meet 10.0.0.103 6379
OK
10.0.0.100:6380> cluster meet 10.0.0.103 6380
OK
集群内新旧节点经过一段时间的通信之后,所有节点会更新它们的状态并保存到本地
10.0.0.100:6380> cluster nodes
# 可以看到新加入两个服务(10.0.0.103:6379/10.0.0.103:6380)都是master,它们还没有管理slot
4fb4c538d5f29255f6212f2eae8a761fbe364a89 10.0.0.101:6380@16380 master - 0 1585048391000 7 connected 0-5460
690b2e1f604a0227068388d3e5b1f1940524c565 10.0.0.102:6379@16379 master - 0 1585048389000 3 connected 10923-16383
1be5d1aaaa9e9542224554f461694da9cba7c2b8 10.0.0.101:6379@16379 master - 0 1585048392055 2 connected 5461-10922
724a8a15f4efe5a01454cb971d7471d6e84279f3 10.0.0.103:6379@16379 master - 0 1585048388000 8 connected
ed9b72fffd04b8a7e5ad20afdaf1f53e0eb95011 10.0.0.103:6380@16380 master - 0 1585048391046 0 connected
89f52bfbb8803db19ab0c5a90adc4099df8287f7 10.0.0.100:6379@16379 slave 4fb4c538d5f29255f6212f2eae8a761fbe364a89 0 1585048388000 7 connected
86e1881611440012c87fbf3fa98b7b6d79915e25 10.0.0.102:6380@16380 slave 1be5d1aaaa9e9542224554f461694da9cba7c2b8 0 1585048389033 6 connected
8c13a2afa76194ef9582bb06675695bfef76b11d 10.0.0.100:6380@16380 myself,slave 690b2e1f604a0227068388d3e5b1f1940524c565 0 1585048390000 4 connected
新节点刚开始都是master节点,但是由于没有负责的槽,所以不能接收任何读写操作,对新节点的后续操作,一般有两种选择:
- 从其他的节点迁移槽和数据给新节点
- 作为其他节点的slave负责故障转移
redis-trib.rb工具也实现了为现有集群添加新节点的命令,同时也实现了直接添加为slave的支持:
:
# 新节点加入集群
redis-trib.rb add-node new_host:new_port old_host:old_port
# 新节点加入集群并作为指定master的slave
redis-trib.rb add-node new_host:new_port old_host:old_port --slave --master-id <master-id>
缩容
确认下线节点的角色
10.0.0.103:6380> cluster nodes
...
# 10.0.0.103:6380是slave
# 10.0.0.103:6379是master
724a8a15f4efe5a01454cb971d7471d6e84279f3 10.0.0.103:6379@16379 master - 0 1585055101000 8 connected 0-1364 5461-6826 10923-12287
ed9b72fffd04b8a7e5ad20afdaf1f53e0eb95011 10.0.0.103:6380@16380 slave 724a8a15f4efe5a01454cb971d7471d6e84279f3 0 1585055099000 0 connected
下线master节点的slot迁移到其他master
[root@node01 redis]# redis-trib.rb reshard 10.0.0.100:6379
......
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1364
What is the receiving node ID? 1be5d1aaaa9e9542224554f461694da9cba7c2b8
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:724a8a15f4efe5a01454cb971d7471d6e84279f3
Source node #2:done
Ready to move 1364 slots.
Source nodes:
M: 724a8a15f4efe5a01454cb971d7471d6e84279f3 10.0.0.103:6379
slots:0-1364,5461-6826,10923-12287 (4096 slots) master
1 additional replica(s)
Destination node:
M: 1be5d1aaaa9e9542224554f461694da9cba7c2b8 10.0.0.101:6379
slots:6827-10922 (4096 slots) master
1 additional replica(s)
Resharding plan:
.......
[root@node01 redis]# redis-trib.rb reshard 10.0.0.100:6379
......
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1364
What is the receiving node ID? 4fb4c538d5f29255f6212f2eae8a761fbe364a89
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:724a8a15f4efe5a01454cb971d7471d6e84279f3
Source node #2:done
.......
[root@node01 redis]# redis-trib.rb reshard 10.0.0.100:6379
......
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 690b2e1f604a0227068388d3e5b1f1940524c565
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1:724a8a15f4efe5a01454cb971d7471d6e84279f3
Source node #2:done
.......
10.0.0.103:6380> cluster nodes
1be5d1aaaa9e9542224554f461694da9cba7c2b8 10.0.0.101:6379@16379 master - 0 1585056902000 9 connected 0-1363 6827-10922
4fb4c538d5f29255f6212f2eae8a761fbe364a89 10.0.0.101:6380@16380 master - 0 1585056903544 12 connected 2729-6826 10923-12287
690b2e1f604a0227068388d3e5b1f1940524c565 10.0.0.102:6379@16379 master - 0 1585056903000 11 connected 1364-2728 12288-16383
# 10.0.0.103:6379的slot已经迁移完成
724a8a15f4efe5a01454cb971d7471d6e84279f3 10.0.0.103:6379@16379 master - 0 1585056903000 10 connected
ed9b72fffd04b8a7e5ad20afdaf1f53e0eb95011 10.0.0.103:6380@16380 myself,slave 4fb4c538d5f29255f6212f2eae8a761fbe364a89 0 1585056898000 0 connected
89f52bfbb8803db19ab0c5a90adc4099df8287f7 10.0.0.100:6379@16379 slave 4fb4c538d5f29255f6212f2eae8a761fbe364a89 0 1585056901000 12 connected
8c13a2afa76194ef9582bb06675695bfef76b11d 10.0.0.100:6380@16380 slave 690b2e1f604a0227068388d3e5b1f1940524c565 0 1585056900000 11 connected
86e1881611440012c87fbf3fa98b7b6d79915e25 10.0.0.102:6380@16380 slave 1be5d1aaaa9e9542224554f461694da9cba7c2b8 0 1585056904551 9 connected
忘记节点
Redis提供了cluster forget{downNodeId}命令来通知其他节点忘记下线节点,当节点接收到cluster forget {down NodeId}命令后,会把nodeId指定的节点加入到禁用列表中,在禁用列表内的节点不再与其他节点发送消息,禁用列表有效期是60秒,超过60秒节点会再次参与消息交换。也就是说当第一次forget命令发出后,我们有60秒的时间让集群内的所有节点忘记下线节点
线上操作不建议直接使用cluster forget命令下线节点,这需要跟大量节点进行命令交互,建议使用redis- trib.rb del-node {host:port} {downNodeId}命令
另外,先下线slave,再下线master可以防止不必要的数据复制
总结 LVS的NAT和DR模型工作原理,并完成DR模型实战。
一、负载均衡LVS基本介绍 LVS是 Linux Virtual Server 的简称,也就是Linux虚拟服务器。这是一个由章文嵩博士发起的一个开源项目,它的官方网站是 http://www.linuxvirtualserver.org。 LVS是Linux内核标准的一部分。LVS是一个实现负载均衡集群的开源软件项目,通过 LVS 的负载均衡技术和 Linux操作系统可以实现一个高性能高可用的 Linux 服务器集群,它具有良好的可靠性、可扩展性和可操作性。 LVS架构从逻辑上可分为调度层、Server集群层和共享存储。LVS实际上相当于基于IP地址的虚拟化应用。 二、LVS的组成 LVS 由2部分程序组成,包括 ipvs 和 ipvsadm。 ipvs(ip virtual server):工作在内核空间,是真正生效实现调度的代码。 ipvsadm:工作在用户空间,负责为ipvs内核框架编写规则,定义谁是集群服务,而谁是后端真实的服务器(Real Server) 三、LVS相关术语 DS:Director Server, 指的是前端负载均衡器节点。 RS:Real Server, 后端真实的工作服务器。 VIP:向外部直接面向用户请求,作为用户请求的目标的IP地址。 DIP:Director Server IP, 前端负载均衡器IP地址,主要用于和内部主机通信。 RIP:Real Server IP, 后端服务器的IP地址。 CIP:Client IP, 访问客户端的IP地址 四、LVS的工作模式介绍 LVS负载均衡常见的有三种工作模式,分别是地址转换(简称NAT模式)、IP隧道(简称TUN模式)和直接路由(简称DR模式),其实企业中最常用的是 DR 实现方式,而 NAT 配置上比较简单和方便,下面总结 DR 和 NAT 原理和特点:
(1) LVS-NAT原理 一般只能配置20台
类似于防火墙的私有网络结构,Director Server作为所有服务器节点的网关,,即作为客户端的访问入口,也是各节点回应客户端的访问出口,其外网地址作为整个群集的VIP地址,其内网地址与后端服务器Real Server在同一个物理网络,Real Server必须使用私有IP地址
- RS必须使用私有IP地址,网关指向DIP。
- DIP与RIP必须在同一网段内。
- DS作为所有服务器节点的网关,也就是说请求和响应报文都需要经过Director Server。
- 支持端口映射
- 高负载场景中,Director Server压力比较大,易成为性能瓶颈。
2. LVS-DR模式 一般使用 配置200台 但有暴露ip的风险 一般要设置多ip防止泄露
(1) LVS-DR原理
Director Server作为群集的访问入口,但不作为网关使用,后端服务器池中的Real Server与Director Server在同一个物理网络中,发送给客户机的数据包不需要经过Director Server。为了响应对整个群集的访问,DS与RS都需要配置有VIP地址。
(2) LVS-DR模型的特点
- RS和DS必须在同一个物理网络中。
- RS可以使用私有地址,也可以使用公网地址,如果使用公网地址,可以通过互联网对RIP进行直接访问。
- 所有的请求报文经由Director。 Server,但响应报文必须不能经过Director Server。
- RS的网关绝不允许指向DIP(不允许数据包经过director)。
- RS上的lo接口配置VIP的IP地址。
LVS-DR模式需要注意的是: 保证前端路由将目标地址为VIP报文统统发给Director Server,而不是RS。
解决方案是:修改RS上内核参数(arp_ignore和arp_announce)将RS上的VIP配置在lo接口的别名上,并限制其不能响应对VIP地址解析请求。
- arp_ignore=1表示系统只响应目的IP为本地IP的ARP请求。
- arp_announce=2表示系统不使用IP包的源地址来设置ARP请求的源地址,而选择发送接口的IP地址。
-
LVS的负载调度算法
最常用的有四种;轮询(rr)、加权轮询(wrr)、最少连接(lc)和加权最少连接(wlc)。
- 轮询(rr):将收到的访问请求按照顺序轮流调度到不同的服务器上,不管后端真实服务器的实际连接数和系统负载。
- 加权轮询(wrr):给RS设置权重,权重越高,那么分发的请求数越多,权重的取值范围0–100。根据每台服务器的性能,给每台服务器添加权值,如果RS1的权值为1,RS2的权值为2,那么调度到RS2的请求会是RS1的2倍。权值越高的服务器,处理的请求越多。这种算法是对rr算法的一种优化和补充。
- 最少连接(lc):根据后端RS的连接数来决定把请求分发给谁,比RS1连接数比RS2连接数少,那么请求就优先发给RS1。
- 加权最少连接(wlc):根据后端RS的权重和连接数来决定把请求分发给谁,权重较高,连接数少的RS会优先处理请求
脚本
DR模型
#!/bin/bash ##第一步就是在路由器执行echo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf #sysctl -p ###后端下载nginx,redis等等 ##后端配置 ## yum install -y ipvsadm ## echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore ## echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce ## echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore ## echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce ## ifconfig lo:1 10.0.0.100/32 ##lvs配置 ## ipvsadm -A -t 10.0.0.100:80 -s rr ## ipvsadm -a -t 10.0.0.100:80 -r 后端地址1:80 -g ## ipvsadm -a -t 10.0.0.100:80 -r 后端地址2:80 -g ## ipvsadm -Ln ##-------------------------------------------------------------## ##实施一共要5台主机 ##前端网管指向路由(两个网卡)的同网段的地址 ##然后再lvs建立一个回环网卡ifconfig lo:1 10.0.0.100/32 ##后端 也建议ifconfig lo:1 10.0.0.100/32 ##后端网关和lvs网关指向路由同网段网卡地址
NAT模型
路由器操作
总结 http协议的通信过程详解
一次HTTP通信的过程
先放一张图,这个图上就基本说明了通信的过程,我觉得还是比较详细的。
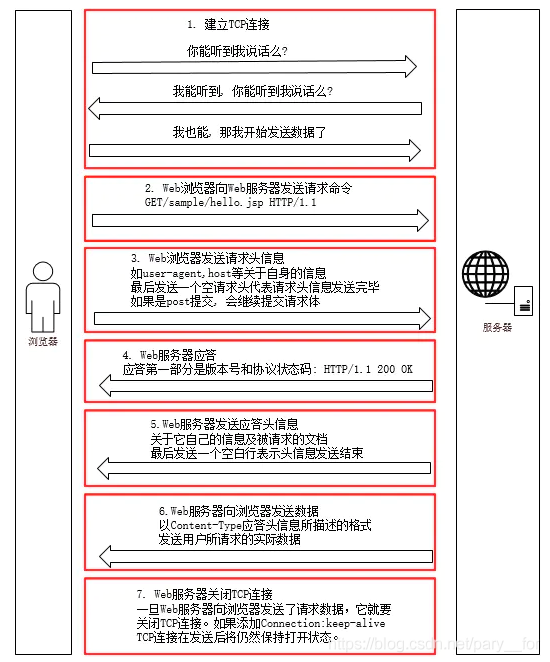
文字说明过程如下 1. 建立TCP连接 Web浏览器首先要通过网络与Web服务器之间通过TCP建立连接,TCP与IP协议共同构建Internet HTTP协议是比TCP处于更高层的应用层协议,只有当低层协议建立练接之后才能进行更高层次的连接 TCP连接的端口号一般是80 2. Web浏览器向Web服务器发送请求行 建立TCP连接之后,Web浏览器会向Web服务器发送请求命令 3. Web浏览器向服务器发送请求头 浏览器发送请求信息之后,还要以头信息的形式发送相关信息,并以空行代表发送结束 4. Web服务器应答 Web服务器接收请求后返回应答,第一部分是协议的版本号和应答状态码 例:“HTTP/1.1 200OK” 5. Web服务器发送应答头 服务器也会随着应答发送一些相关信息,并以空行代表发送结束 6. Web服务器发送数据 Web服务器向浏览器发送头信息之后,就以Content-Type格式发送用户所请求的信息 7. Web服务器关闭TCP连接 一般情况下,一旦Web服务器向浏览器发送请求数据后,就要关闭TCP连接了 若浏览器或者服务器的头信息中加入了这样一段代码:connection:Keep-alive 则TCP连接会保持打开状态,可以继续通过相同的连接发送请求 文章知识点与官方知识档案匹
总结 网络IO模型和nginx架构
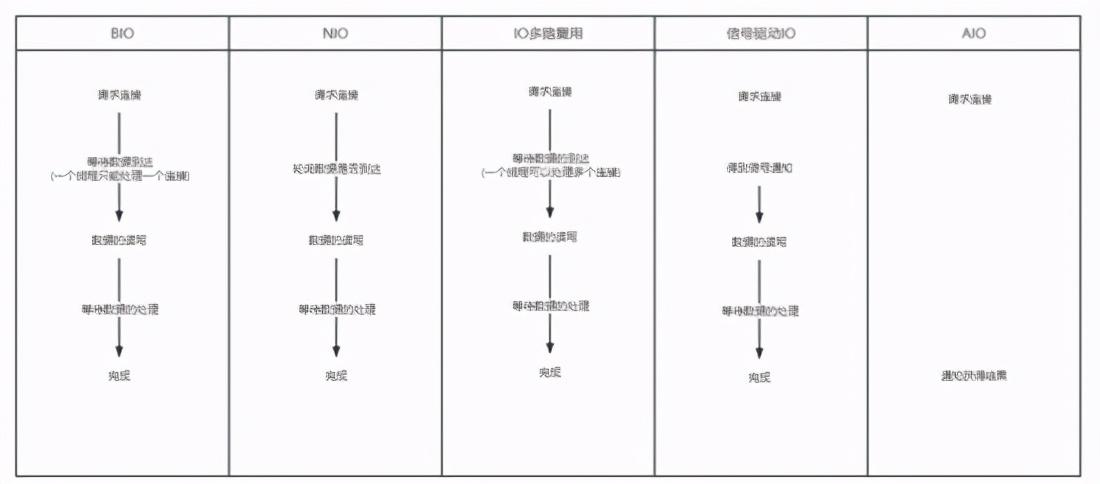
网络IO基本概念理解 IO分别表示输入(input)和输出(output)。它描述的是计算机的数据流动的过程,因此IO第一大特征是有数据的流动;那么对于IO的整个过程大体上分为2个部分, 第一个部分为IO的调用,第二个过程为IO的执行 。IO的调用指的就是系统调用,IO的执行指的是在内核中相关数据的处理过程,这个过程是由操作系统完成的,与程序员无关。 IO多路复用是指 内核 一旦发现进程指定的一个或者多个IO条件准备读取,它就通过该 进程 ,目前支持I/O多路复用的系统调用有 select 、 poll 、 epoll ,I/O多路复用就是通过一种机制,一个进程可以监视多个描述符(socket),一旦某个描述符就绪(一般是读就绪或者写就绪),能够通过程序进行相应的读写操作。 描述符(socket)在windows中可以叫做句柄。我们可以理解成一个文件对应的ID。IO其实就是对 对同步 异步 阻塞 非阻塞在网络中的理解 可以先看以前写的文章: 对同步 异步 阻塞 非阻塞在网络中的理解 阻塞IO:请求进程一直等待IO准备就绪。 非阻塞IO:请求进程不会等待IO准备就绪。 同步IO操作:导致请求进程阻塞,直到IO操作完成。 异步IO操作:不导致请求进程阻塞。 举个小例的来理解阻塞,非阻塞,同步和异步的关系,我们知道编写一个程序可以有多个函数,每一个函数的执行都是相互独立的;但是,对于一个程序的执行过程,每一个函数都是必须的,那么如果我们需要等待一个函数的执行结束然后返回一个结果(比如接口调用),那么我们说该函数的调用是阻塞的,对于至少有一个函数调用阻塞的程序,在执行的过程中,必定存在阻塞的一个过程,那么我们就说该程序的执行是同步的,对于异步自然就是所有的函数执行过程都是非阻塞的
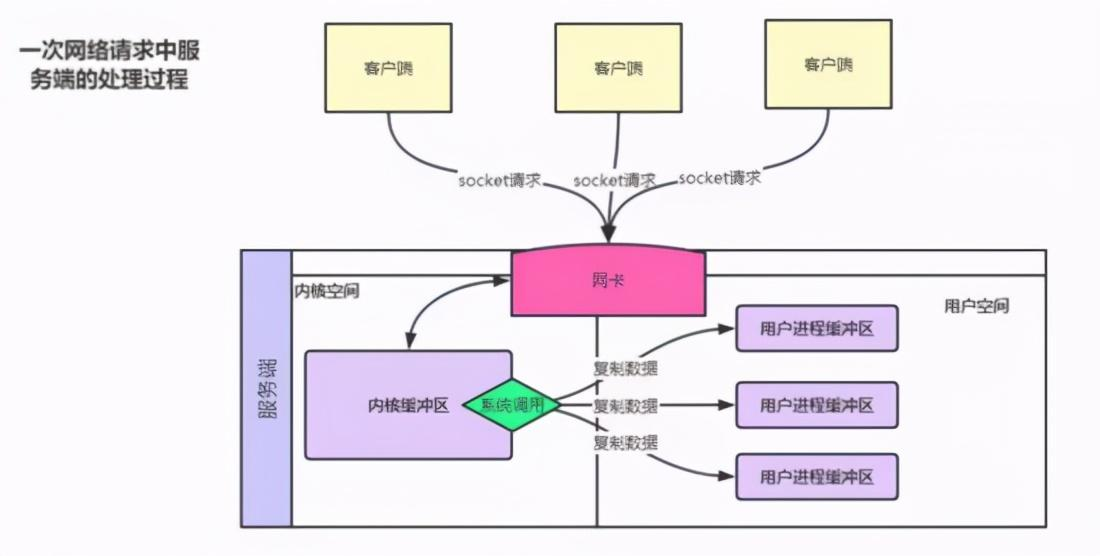
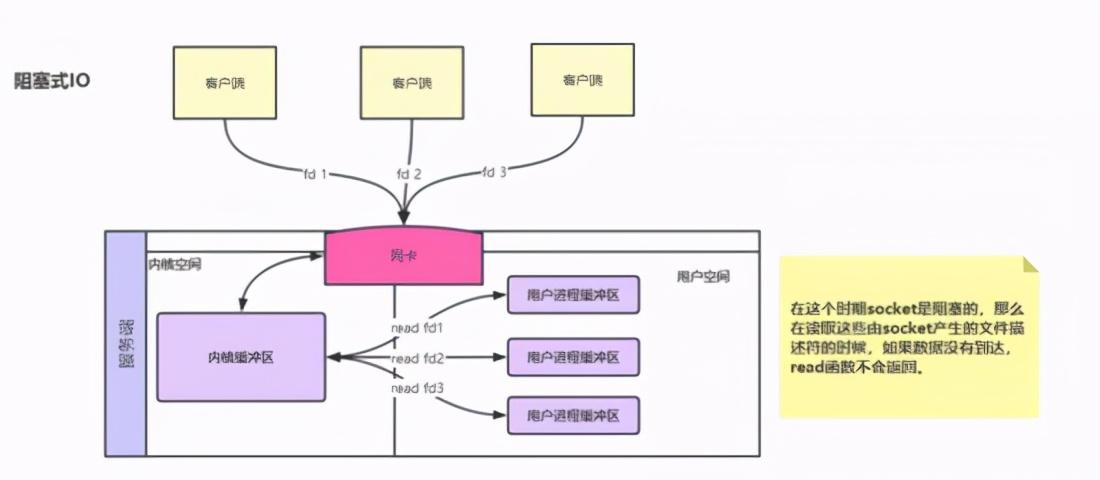

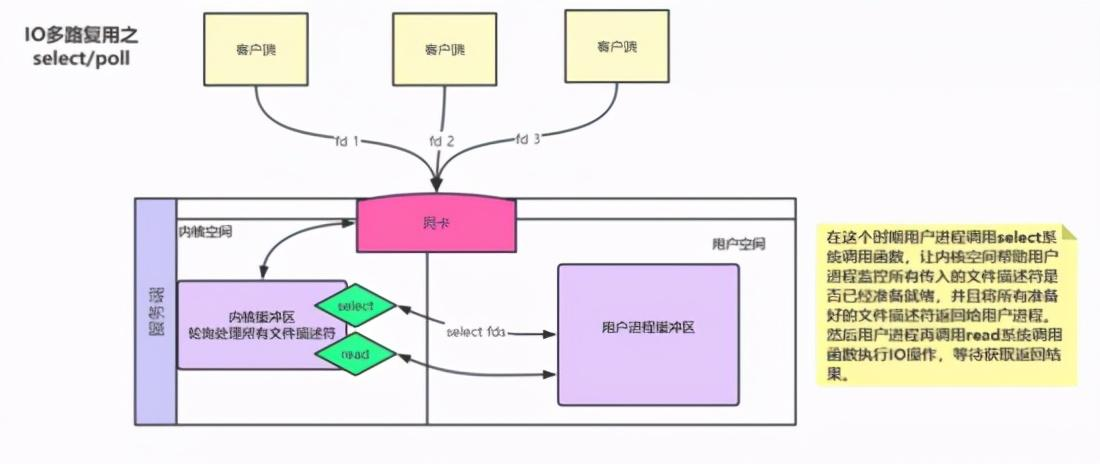
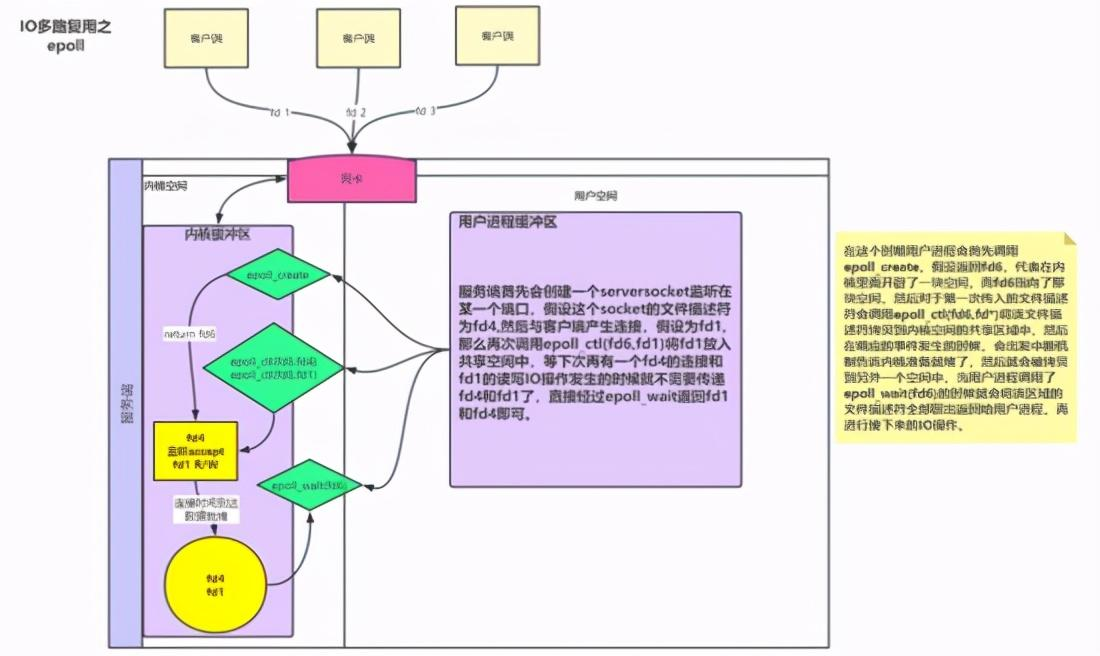
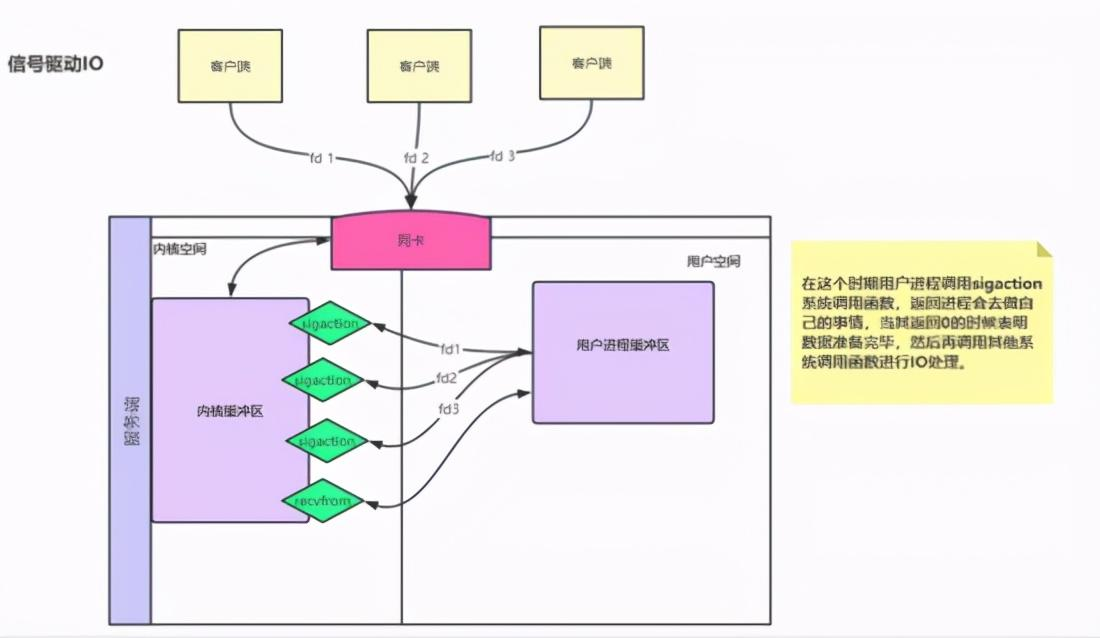
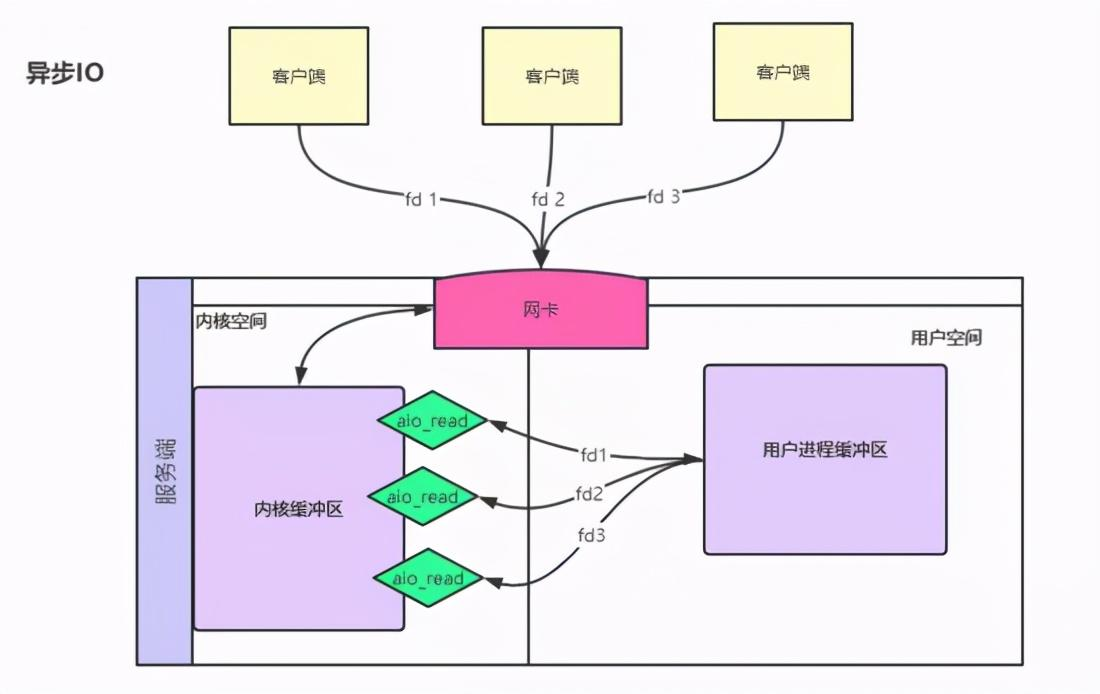
前四种模型的主要区别于第一阶段,因为他们的第二阶段都是一样的:在数据从内核拷贝到应用进程的缓冲区期间,进程都会阻塞。相反,异步 IO 模型在这两个阶段都不会阻塞,从而不同于其他四种模型。
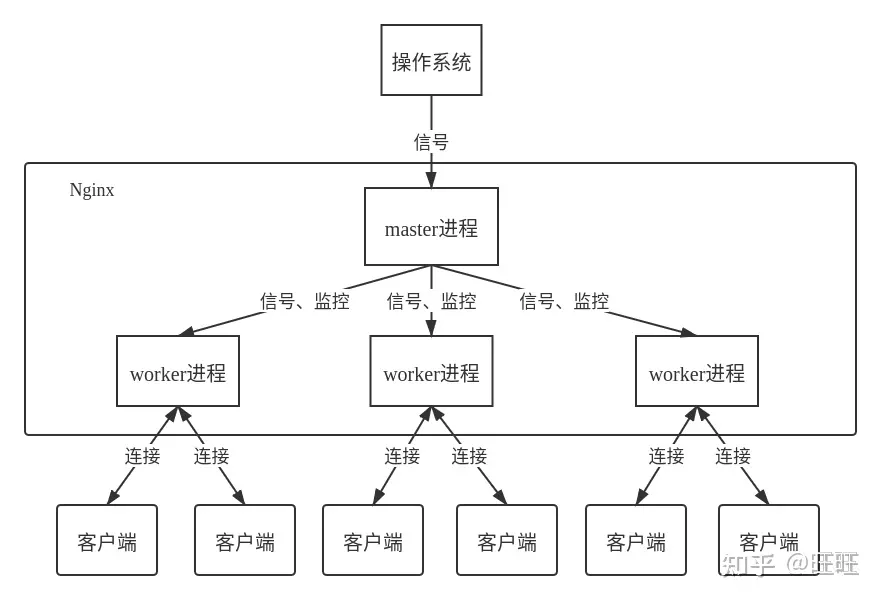
nginx框架
完成nginx编译安装脚本
1 #!/bin/bash 2 #配置环境 3 yum -y install gcc gcc-c++ 4 yum install -y pcre pcre-devel 5 yum install -y openssl openssl-devel 6 yum install -y zlib zlib-devel wget make 7 #创建用户nginx 8 useradd nginx 9 passwd nginx 10 #https://nginx.org/ nginx编译包地址 11 wget http://nginx.org/download/nginx-1.17.0.tar.gz 12 tar -vzxf nginx-1.17.0.tar.gz 13 cd nginx-1.17.0/ 14 ./configure \ 15 --prefix=/etc/nginx \ 16 --sbin-path=/usr/sbin/nginx \ 17 --conf-path=/etc/nginx/nginx.conf \ 18 --error-log-path=/var/log/nginx/error.log \ 19 --http-log-path=/var/log/nginx/access.log \ 20 --pid-path=/var/run/nginx.pid \ 21 --lock-path=/var/run/nginx.lock \ 22 --http-client-body-temp-path=/var/cache/nginx/client_temp \ 23 --http-proxy-temp-path=/var/cache/nginx/proxy_temp \ 24 --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp \ 25 --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp \ 26 --http-scgi-temp-path=/var/cache/nginx/scgi_temp \ 27 --user=nginx \ 28 --group=nginx \ 29 --with-file-aio \ 30 --with-threads \ 31 --with-http_addition_module \ 32 --with-http_auth_request_module \ 33 --with-http_dav_module \ 34 --with-http_flv_module \ 35 --with-http_gunzip_module \ 36 --with-http_gzip_static_module \ 37 --with-http_mp4_module \ 38 --with-http_random_index_module \ 39 --with-http_realip_module \ 40 --with-http_secure_link_module \ 41 --with-http_slice_module \ 42 --with-http_ssl_module \ 43 --with-http_stub_status_module \ 44 --with-http_sub_module \ 45 --with-http_v2_module \ 46 --with-mail \ 47 --with-mail_ssl_module \ 48 --with-stream \ 49 --with-stream_realip_module \ 50 --with-stream_ssl_module \ 51 --with-stream_ssl_preread_module 52 make &&make install 53 ##Nginx编译时编译Lua如下 54 ##LuaJIT官网:http://luajit.org/ 55 wget http://luajit.org/download/LuaJIT-2.0.2.tar.gz 56 tar -axv -f LuaJIT-2.0.2.tar.gz 57 cd LuaJIT-2.0.2 58 make install PREFIX=/etc/LuaJIT 59 export LUAJIT_LIB=/etc/LuaJIT/lib 60 export LUAJIT_INC=/etc/LuaJIT/include/luajit-2.0 61 ##安装ngx_devel_kit 项目地址:https://github.com/simplresty/ngx_devel_kit 62 wget https://github.com/simplresty/ngx_devel_kit/archive/v0.3.1rc1.zip 63 ##安装lua-nginx-module 项目地址:https://github.com/openresty/lua-nginx-module 64 wget https://github.com/openresty/lua-nginx-module/archive/v0.10.13.tar.gz 65 tar -axf v0.3.1rc1.tar.gz && tar -zxf v0.10.9rc7.tar.gz 66 mv lua-nginx-module-0.10.9rc7/ lua-nginx-module && mv ngx_devel_kit-0.3.1rc1/ ngx_devel_kit 67 cd ../ 68 ./configure \ 69 --prefix=/etc/nginx \ 70 --sbin-path=/usr/sbin/nginx \ 71 --conf-path=/etc/nginx/nginx.conf \ 72 --error-log-path=/var/log/nginx/error.log \ 73 --http-log-path=/var/log/nginx/access.log \ 74 --pid-path=/var/run/nginx.pid \ 75 --lock-path=/var/run/nginx.lock \ 76 --http-client-body-temp-path=/var/cache/nginx/client_temp \ 77 --http-proxy-temp-path=/var/cache/nginx/proxy_temp \ 78 --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp \ 79 --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp \ 80 --http-scgi-temp-path=/var/cache/nginx/scgi_temp \ 81 --user=nginx \ 82 --group=nginx \ 83 --with-compat \ 84 --with-file-aio \ 85 --with-threads \ 86 --with-http_addition_module \ 87 --with-http_auth_request_module \ 88 --with-http_dav_module \ 89 --with-http_flv_module \ 90 --with-http_gunzip_module \ 91 --with-http_gzip_static_module \ 92 --with-http_mp4_module \ 93 --with-http_random_index_module \ 94 --with-http_realip_module \ 95 --with-http_secure_link_module \ 96 --with-http_slice_module \ 97 --with-http_ssl_module \ 98 --with-http_stub_status_module \ 99 --with-http_sub_module \ 100 --with-http_v2_module \ 101 --with-mail \ 102 --with-mail_ssl_module \ 103 --with-stream \ 104 --with-stream_realip_module \ 105 --with-stream_ssl_module \ 106 --with-stream_ssl_preread_module \ 107 --add-module=/root/ngx_devel_kit \ 108 --add-module=/root/lua-nginx-module \ 109 --with-ld-opt="-Wl,-rpath,$LUAJIT_LIB" 110 make -j2 && make install 111 nginx -V 112 ##mkdir -p /var/cache/nginx/client_temp 自启动 113 ##开机启动 114 cat >> /usr/lib/systemd/system <<EOF 115 [Unit] 116 Description=nginx //描述 117 After=syslog.target network.target remote-fs.target nss-lookup.target \\描述服务类别 118 119 [Service] 120 Type=forking //设置运行方式,后台运行 121 PIDFile=/usr/local/nginx/logs/nginx.pid //设置PID文件 122 ExecStart=/usr/local/nginx/sbin/nginx //启动命令 123 ExecReload=/bin/kill -s HUP $MAINPID //重启命令 124 ExecStop=/bin/kill -s QUIT $MAINPID //关闭命令 125 PrivateTmp=true //分配独立的临时空间 126 *注意命令需要写绝对路径 127 [Install] ///服务安装的相关设置,可设置为多用户 128 WantedBy=multi-user.target 129 EOF
. 总结nginx核心配置,并实现nginx多虚拟主机
Nginx虚拟主机 虚拟Web主机指的是在同一台物理服务器中发布多个Web站点或应用 独立的网站,独立的项目甚至独立的功能模块都可以使用虚拟主机进行发布 Nginx可以基于不同的IP、不同的端口以及不同的域名实现不同的虚拟主机 虚拟主机内的资源收到虚拟主机配置文件内容约束,与其他虚拟主机相对独立 Nginx的配置文件的组成部分: 主配置文件:nginx.conf 子配置文件: include conf.d/*.conf fastcgi, uwsgi,scgi 等协议相关的配置文件 mime.types:支持的mime类型,MIME
|
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
worker_processes 4;pid logs/nginx.pid;events { worker_connections 1024;}http { default_type application/octet-stream; sendfile on; keepalive_timeout 65; server { listen 192.168.2.158:80; server_name localhost; location / { root html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } server { listen 192.168.2.159:80; server_name localhost; location / { root test; index index.html ; } }<br>} |
worker_processes 4;pid logs/nginx.pid;events { worker_connections 1024;}http { default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; sendfile on; keepalive_timeout 65; include port2.conf; server { listen 80; server_name localhost; location / { root html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } }}
server {
listen 81; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root test; index index.html ; } error_page 404 /baselogin.PNG; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; }}# 基本用法 access_log /var/logs/nginx-access.log 该例子指定日志的写入路径为/var/logs/nginx-access.log,日志格式使用默认的combined。 access_log /var/logs/nginx-access.log buffer=32k gzip flush=1m 该例子指定日志的写入路径为/var/logs/nginx-access.log,日志格式使用默认的combined,指定日志的缓存大小为32k,日志写入前启用gzip进行压缩,压缩比使用默认值1,缓存数据有效时间为1分钟。 使用log_format自定义日志格式 Nginx预定义了名为combined日志格式,如果没有明确指定日志格式默认使用该格式: log_format combined '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"'; 如果不想使用Nginx预定义的格式,可以通过log_format指令来自定义。 # 语法 log_format name [escape=default|json] string ...; name 格式名称。在access_log指令中引用。 escape 设置变量中的字符编码方式是json还是default,默认是default。 string 要定义的日志格式内容。该参数可以有多个。参数中可以使用Nginx变量。 下面是log_format指令中常用的一些变量: 变量含义$bytes_sent发送给客户端的总字节数$body_bytes_sent发送给客户端的字节数,不包括响应头的大小$connection连接序列号$connection_requests当前通过连接发出的请求数量$msec日志写入时间,单位为秒,精度是毫秒$pipe如果请求是通过http流水线发送,则其值为"p",否则为“."$request_length请求长度(包括请求行,请求头和请求体)$request_time请求处理时长,单位为秒,精度为毫秒,从读入客户端的第一个字节开始,直到把最后一个字符发送张客户端进行日志写入为止$status响应状态码$time_iso8601标准格式的本地时间,形如“2017-05-24T18:31:27+08:00”$time_local通用日志格式下的本地时间,如"24/May/2017:18:31:27 +0800"$http_referer请求的referer地址。$http_user_agent客户端浏览器信息。$remote_addr客户端IP$http_x_forwarded_for当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器也要进行相关的x_forwarded_for设置。$request完整的原始请求行,如 "GET / HTTP/1.1"$remote_user客户端用户名称,针对启用了用户认证的请求$request_uri完整的请求地址,如 "https://daojia.com/" 下面演示一下自定义日志格式的使用: access_log /var/logs/nginx-access.log main log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; 我们使用log_format指令定义了一个main的格式,并在access_log指令中引用了它。假如客户端有发起请求:https://suyunfe.com/,我们看一下我截取的一个请求的日志记录: 112.195.209.90 - - [20/Feb/2018:12:12:14 +0800] "GET / HTTP/1.1"200190"-""Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36""-" 我们看到最终的日志记录中$remote_user、$http_referer、$http_x_forwarded_for都对应了一个-,这是因为这几个变量为空。 设置error_log 错误日志在Nginx中是通过error_log指令实现的。该指令记录服务器和请求处理过程中的错误信息。 # 语法 配置错误日志文件的路径和日志级别。 error_log file [level]; Default: error_log logs/error.log error; 第一个参数指定日志的写入位置。 第二个参数指定日志的级别。level可以是debug, info, notice, warn, error, crit, alert,emerg中的任意值。可以看到其取值范围是按紧急程度从低到高排列的。只有日志的错误级别等于或高于level指定的值才会写入错误日志中。默认值是error。 # 基本用法 error_log /var/logs/nginx/nginx-error.log 它可以配置在:main, http, mail, stream, server, location作用域。 例子中指定了错误日志的路径为:/var/logs/nginx/nginx-error.log,日志级别使用默认的error。 open_log_file_cache 每一条日志记录的写入都是先打开文件再写入记录,然后关闭日志文件。如果你的日志文件路径中使用了变量,如access_log /var/logs/$host/nginx-access.log,为提高性能,可以使用open_log_file_cache指令设置日志文件描述符的缓存。 # 语法 open_log_file_cache max=N [inactive=time] [min_uses=N] [valid=time]; max 设置缓存中最多容纳的文件描述符数量,如果被占满,采用LRU算法将描述符关闭。 inactive 设置缓存存活时间,默认是10s。 min_uses 在inactive时间段内,日志文件最少使用几次,该日志文件描述符记入缓存,默认是1次。 valid:设置多久对日志文件名进行检查,看是否发生变化,默认是60s。 off:不使用缓存。默认为off。 # 基本用法 open_log_file_cache max=1000 inactive=20s valid=1m min_uses=2; 它可以配置在http、server、location作用域中。 例子中,设置缓存最多缓存1000个日志文件描述符,20s内如果缓存中的日志文件描述符至少被被访问2次,才不会被缓存关闭。每隔1分钟检查缓存中的文件描述符的文件名是否还存在。 总结 Nginx中通过access_log和error_log指令配置访问日志和错误日志,通过log_format我们可以自定义日志格式。如果日志文件路径中使用了变量,我们可以通过open_log_file_cache指令来设置缓存,提升性能。 另外,在access_log和log_format中使用了很多变量,这些变量没有一一列举出来,详细的变量信息可以参考Nginx官方文档

 浙公网安备 33010602011771号
浙公网安备 33010602011771号