N80-第6周作业
简述DDL,DML,DCL,DQL,并且说明mysql各个关键字查询时候的先后顺序
SQL程序语言有四种类型,对数据库的基本操作都属于这四类,它们分别为;
数据定义语言(DDL)
数据查询语言(DQL)
数据操纵语言(DML)
数据控制语言(DCL)
1 数据定义语言(DDL)
DDL(Data Definition Language,数据定义语言)
主要用于维护存储数据的结构,这种结构包括数据库,表、视图、索引、同义词、聚簇等。
代表指令:
create 创建数据库和数据库的一些对象
drop 删除数据库/表、索引、条件约束以及数据表的权限等
alter 修改数据库表的定义及数据属性
2数据查询语言(DQL)
主要用于对数据库对象中包含的数据进行操作
代表指令:
insert 向数据库中插入一条数据
delete 删除表中的一条或者多条记录
updata 修改表中的数
3数据操纵语言(DML)
主要用于查询数据库当中的数据
代表指令:
selete查询表中的数据from查询哪张表、视图where约束条件
4数据控制语言(DCL)
主要控制数据库对象的权限管理、事务和实时监视。
代表指令:
grant分配权限给用户revoke废除数据库中某用户的权限rollback退回到某一点 (回滚)commit提交
mysql各个关键字查询时候的先后顺序

在SQL语句中每个关键字都会按照顺序往下执行,而每一步操作,会生成一个虚拟表,最后的虚拟表就是最终结果。
FROM : 对FROM左边的表和右边的表计算笛卡尔积,产生虚表VT1;
ON : 对虚拟表VT1进行ON筛选,只有那些符合条件的行才会被记录在虚拟表VT2中;
JOIN :如果是OUT JOIN,那么将保留表中(如左表或者右表)未匹配的行作为外部行添加到虚拟表VT2中,从而产生虚拟表VT3;
WHERE :对虚拟表VT3进行WHERE条件过滤,只有符合的记录才会被放入到虚拟表VT4;
GROUP BY:根据GROUP BY子句中的列,对虚拟表VT4进行分组操作,产生虚拟表VT5;
CUBE|ROLLUP:对虚拟表VT5进行CUBE或者ROLLUP操作,产生虚拟表VT6;
HAVING :对虚拟表VT6进行 HAVING 条件过滤,只有符合的记录才会被插入到虚拟表VT7中;
SELECT :执行SELECT操作,选择指定的列,插入到虚拟表VT8中;
DISTINCT :对虚拟表VT8中的记录进行去重,产生虚拟表VT9;
ORDER BY :将虚拟表VT9中的记录按照进行排序操作,产生虚拟表VT10;
LIMIT :取出指定行的记录,产生虚拟表VT11,并将结果返回。
*******************************************************************************************************************************************************************************************************************
注意
commit
在数据库的插入、删除和修改操作时,只有当事务在提交到数据库时才算完成。在事务提交前,只有操作数据库的这个人才能有权看到所做的事情,别人只有在最后提交完成后才可以看到。提交数据有三种类型:显式提交、隐式提交及自动提交。
显式提交
用commit命令直接完成的提交为显式提交。commit;
隐式提交
用SQL命令间接完成的提交为隐式提交。这些命令有:
alter、audit、comment、connect、create、disconnect、drop、exit、grant、noaudit、quit、revoke、rename。
自动提交
若把autocommit设置为on,则在插入、修改、删除语句执行后,系统将自动进行提交。set autocommit on;
*******************************************************************************************************************************************************************************************************************
.自行设计10个sql查询语句,需要用到关键字[GROUP BY/HAVING/ORDER BY/LIMIT],至少同时用到两个。
前提
我们先创建一个表 mysql是支持重定向的 vim 1.sql mysql -u -p -h < 1.sql
/*------------员工信息库-------------*/ (1.sql内容)
create database staff;
use staff;
create table yunwei(id int not null primary key,name char(4) not null,age tinyint(3) unsigned not null,sex enum('man','woman') not null);
create table caiwu(id int not null primary key,name char(4) not null,age tinyint(3) unsigned not null,sex enum('man','woman') not null);
insert into yunwei values(1,'张三',20,'man'),(2,'张四',21,'man'),(3,'张莉',22,'woman'),(4,'张五',23,'man'),(5,'张六',24,'man'),(6,'张丽',25,'woman');
insert into caiwu values(1,'李一',24,'man'),(2,'李莉',23,'woman'),(3,'李二',22,'man'),(4,'李三',21,'man'),(5,'李四',20,'man'),(6,'李丽',19,'woman');
命令 select * from staff.yunwei;
+----+--------+-----+-------+
| id | name | age | sex |
+----+--------+-----+-------+
| 1 | 张三 | 20 | man |
| 2 | 张四 | 21 | man |
| 3 | 张莉 | 22 | woman |
| 4 | 张五 | 23 | man |
| 5 | 张六 | 24 | man |
| 6 | 张丽 | 25 | woman |
+----+--------+-----+-------+
简单查询
直接查询
语法:select 字段 from 表名;

条件查询
关键字为where,通常位于表名后面
语法:select 字段 from 表名 where 条件;

模糊查询
关键字是like,通常位于条件字段后面
语法:select 字段 from 表名 where 字段 like ‘%数据%’

算数运算符
| 符号 | 作用 |
|---|---|
| > | 大于 |
| < | 小于 |
| = | 等于 |
| != | 不等于 |
| <> | 与!=同义,不等于 |
| >= | 大于等于 |
| <= | 小于等于 |


逻辑运算符
| and | 与,同时满足多个条件 |
| or | 或,满足多个条件中的一个即可 |
| not | 否,不满足条件 |
查询yunwei表中性别为女,或年龄为23的记录


in与not in运算符
| in | 在一个条件列表中 |
| not in | 不在一个条件列表中 |


排序查询
关键字为order by与asc,desc,通常位于表名之后
排序分为两种,升序(asc)和降序(desc)
语法:select 字段 from 表名 order by 字段 排序方式;

高级查询
范围运算
关键字为between…and…,通常位于条件字段后面。
语法:select 字段 from 表名 where 字段 between 范围1 and 范围2;


限制查询
关键字为limit,通常位于表名后面。
语法:select 字段 from 表名 limit n,m;
imit可以强制指定查询结果的记录条数。
n是开始记录行,0表示第一条记录,m表示显示行,从n开始,共显示几行记录。
时刻注意开始范围时从0开始的,1表示的是第二行,而非第一行。
显示范围就是共显示几条记录,并不是结束范围。
例如:查询yunwei表中第2-4行记录

嵌套查询
没有关键字,嵌套查询分为查询语句和子查询语句,在查询语句中含有子查询语句,所以叫做嵌套查询。
嵌套子查询通常位于查询语句的条件之后。
例如:在caiwu表中查询名称为张三的字段。
先在caiwu表中添加一个张三字段,并且年龄不同
失败了
平均值avg()
关键字为avg(),通常位于select之后
格式:select avg(字段) from 表名;
例如:查询caiwu表中年龄字段的平均值
用于统计数值平均值

3. xtrabackup备份和还原数据库练习
安装部署xtrabackup
https://www.percona.com/doc/percona-xtrabackup/8.0/index.html 官方下载
数据备份与恢复
--创建用户
CREATE USER 'bkpuser'@'localhost' IDENTIFIED BY '你的密码';
--授权
GRANT BACKUP_ADMIN,PROCESS,RELOAD,LOCK TABLES,REPLICATION CLIENT ON *.* TO 'bkpuser'@'localhost';
-- 查询权限
GRANT SELECT ON *.* TO 'bkpuser'@'localhost';
FLUSH PRIVILEGES;
-- 查看
SHOW GRANTS FOR 'bkpuser'@'localhost';
数据备份
您可以在每次完整备份之间执行多次增量备份,例如每周一次完整备份和每天一次增量备份,或者每天一次完整备份和每小时一次增量备份。增量备份之所以有效,是因为每个InnoDB页面都包含一个日志序列号或LSN。LSN是整个数据库的系统版本号。每个页面的LSN显示它最近的更改时间。
增量备份实际上并不将数据文件与先前备份的数据文件进行比较,增量备份只需读取页面并将其LSN与上次备份的LSN进行比较。但是,您仍然需要完整备份来恢复增量更改;如果没有完整备份作为基础,增量备份就毫无用处。
备份
xtrabackup --backup -u用户名 -p --target-dir=保存路径
恢复数据库
xtrabackup --prepare --target-dir=备份保存路径
4. 实现mysql主从复制,主主复制和半同步复制
原理:将主服务器的binlog日志复制到从服务器上执行一遍,达到主从数据的一致状态。
过程:从库开启一个I/O线程,向主库请求Binlog日志。主节点开启一个binlog dump线程,检查自己的二进制日志,并发送给从节点;从库将接收到的数据保存到中继日志(Relay log)中,另外开启一个SQL线程,把Relay中的操作在自身机器上执行一遍
优点:
作为备用数据库,并且不影响业务
可做读写分离,一般是一个写库,一个或多个读库,分布在不同的服务器上,充分发挥服务器和数据库的性能,但要保证数据的一致性
扩展:
SQL线程执行完Relay log中的事件后,会将当前的中继日志Relay log删除,避免它占用更多的磁盘空间
为保证从库重启后,仍然知道从哪里开始复制,从库默认会创建两个文件master.info和relay-log.info,分别记录了从库的IO线程当前读取主库binlog的进度和SQL线程应用Relay-log的进度。可通过show slave status \G命令查看从库当前复制的状态
、一主多从架构 (MySQL的主从复制有两种复制方式,分别是异步复制和半同步复制)
在主库的请求压力非常大时,可通过配置一主多从复制架构实现读写分离,把大量对实时性要求不是很高的请求通过负载均衡分发到多个从库上去读取数据,降低主库的读取压力。而且在主库出现宕机时,可将一个从库切换为主库继续提供服务
双主复制/Dual Master架构
双主复制架构适用于需要进行主从切换的场景
在只有一个主库的架构下,当主库宕机后,将其中一个从库切换为主库继续提供服务。原来的主库就没有数据来源了,那么当这个新的主库接收到新的数据时,原来的主库却没有同步,因此他们的数据差异越来越大,那么原来的主库就无法成为主从复制环境中的一员了。当原来的主库恢复正常后,需要重新将其添加进复制环境中去。
那为了避免重复添加主库的问题,双主复制应运而生。两个数据库互为主从,当主库宕机恢复后,由于它还是原来从库(现在主库)的从机,所以它还是会复制新的主库上的数据。那么无论主库的角色怎么切换,原来的主库都不会脱离复制环境。
需要至少两台主机安装mysql 最好同版本
192.168.123.144 主
192.168.124.145 从
首先安装数据库
在主主机创建远程连接的账号
CREATE USER 'wang'@'%' IDENTIFIED BY '123456';
主主机授权 (这里我是所有数据库都授权了)
GRANT ALL ON *.* TO 'wang'@'%' ALL 是所有权限 *.*是所有库的所有权限

在mysql配置文件 配置一个专属ip 这个mysql机都不一样
主主机
[mysqld]
log-bin=mysql-bin //从主服务器上同步日志文件记录到本地
server-id=1
宿主机
[mysqld]
log-bin=mysql-bin //从主服务器上同步日志文件记录到本地
server-id=2
relay-log-index = slave-relay-bin.index /建立索引文件,定义relay-log的位置和名称
第三部就是 在宿主机上用远程账号登录主数据库
然后再执行
change master to master_host='192.168.247.144',master_useser='wang',master_password='123456',master_log_file='master-binn.000001
master_host 主数据库ip
master_useser 用户名
master_password 密码
master_log_file 2进制名 可用show master status; 查看
在start slave; //开启从复制 就可以了

主主复制就是 两个都是主机 没有从
就是两边都执行一次主从复制操作
. 用mycat实现mysql的读写分离

1.配置多个数据源,根据业务需求访问不同的数据,指定对应的策略:增加,删除,修改操作访问对应数据,查询访问对应数据,不同数据库做好的数据一致性的处理。由于此方法相对易懂,简单,不做过多介绍。
2. 动态切换数据源,根据配置的文件,业务动态切换访问的数据库:此方案通过Spring的AOP,AspactJ来实现动态织入,通过编程继承实现Spring中的AbstractRoutingDataSource,来实现数据库访问的动态切换,不仅可以方便扩展,不影响现有程序,而且对于此功能的增删也比较容易。
3. 通过mycat来实现读写分离:使用mycat提供的读写分离功能,mycat连接多个数据库,数据源只需要连接mycat,对于开发人员而言他还是连接了一个数据库(实际是mysql的mycat中间件),而且也不需要根据不同业务来选择不同的库,这样就不会有多余的代码产生。
Mycat安装和配置
安装步骤
#安装Java环境(mycat基于java)
yum install java-1.8.0-openjdk.x86_64
# 下载mycat
wget http://dl.mycat.io/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
# 解压
tar -zxvf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
# 剪切到/usr/local下
mv mycat /usr/local/
# 创建专门运行mycat账号
adduser mycat
# 切换到mycat文件夹路径下
cd /usr/local
# 将文件权限赋给mycat账号
chown mycat:mycat -R mycat
#配置环境变量并添加 export JAVA_HOME=/usr export MYCAT_HOME=/usr/local/mycat(如下图所示)
vim /etc/profile

# 刷新环境变量文件 source /etc/profile # 切换mycat用户 su mycat #切换目录 cd /usr/local/mycat/bin/ #启动mycat ./mycat start
好了,mycat启动成功,我们来看一下读写分离的配置和mycat的连接配置!
配置Mycat的读写分离
配置读写分离信息
#进入配置文件
vi /usr/local/mycat/conf/schema.xml

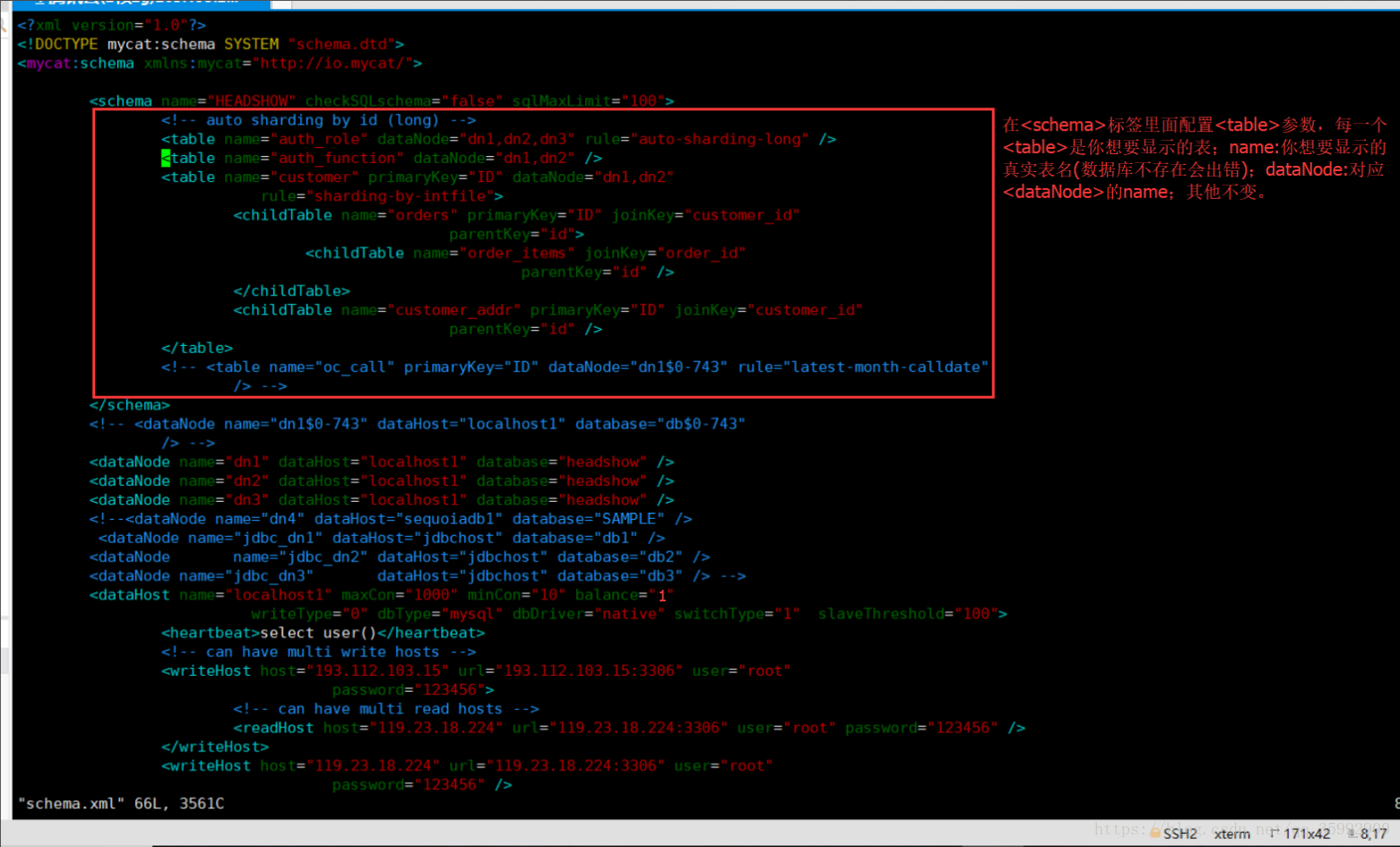

#进入配置文件 vi /usr/local/mycat/conf/server.xml


balance指的负载均衡类型,目前的取值有4种:
1. balance=”0”, 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
2. balance=”1”,全部的readHost与stand bywriteHost参与select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。
3. balance=”2”,所有读操作都随机的在writeHost、readhost上分发。
4. balance=”3”,所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost不负担读压力
注意:balance=3只在1.4及其以后版本有,1.3没有。
writeType属性:
1.writeType=”0”,所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后以切换后的为准,切换记录在配置文件中:dnindex.properties.
2.writeType=”1”,所有写操作都随机地发送到配置的writeHost,1.5以后废弃不推荐。
switchType指的是切换的模式,目前的取值也有4种:
1. switchType=’-1’ 表示不自动切换
2. switchType=’1’ 默认值,表示自动切换
3. switchType=’2’ 基于MySQL主从同步的状态决定是否切换,心跳语句为 show slave status
4. switchType=’3’基于MySQLgalary cluster的切换机制(适合集群)(1.4.1),心跳语句为 show status like ‘wsrep%’。
实现openvpn部署,并且测试通过,输出博客或者自己的文档存档
OpenVPN原理及部署使用
VPN技术通过密钥交换、封装、认证、加密手段在公共网络上建立起私密的隧道,保障传输数据的完整性、私密性和有效性。OpenVPN是近年来新出现的开放源码项目,实现了SSL VPN的一种解决方案。 传统SSL VPN通过端口代理的方法实现,代理服务器根据应用协议的类型(如http,telnet等)做相应的端口代理,客户端与代理服务器之间建立SSL安全连接,客户端与应用服务器之间的所有数据传输通过代理服务器转发。这种实现方式烦琐,应用范围也比较窄:仅适用于用TCP固定端口进行通信的应用系统,且对每个需要代理的端口进行单独配置;对于每个需要用到动态端口的协议都必须重新开发,且在代理中解析应用协议才能实现代理,如FTP协议;不能对TCP以外的其它网络通信协议进行代理;代理服务器前端的防火墙也要根据代理端口的配置变化进行相应调整。 OpenVPN以一种全新的方式实现了SSL VPN的功能,克服了传统SSL VPN的一些缺陷,扩展了应用领域,并且防火墙上只需开放TCP或UDP协议的一个端口。
第一步 网上冲浪,查看防火墙端口绑定规则
在网上疯狂的搜索着关于CISCO ASA5515-X的网络配置,查看防火墙中关于公网IP:x.x.x.x与主机之间端口射映关系,因为不断的变更交接人,记录的网络配置信息和文档早已随着时间飞逝了,这时候不免想来句你妹的...
ciscoasa# show nat
...
ciscoasa# show run object
...
通过查看一波nat、object和service之后,发现了防火墙上配置的Public IP与内部服务OpenVPN主机之间端口的映射关系,于是赶紧找几个还有气的主机进行业务恢复
第二步 照着葫芦画个瓢
这是一台Centos7主机
[root@vpn ~]# cat /etc/redhat-release
CentOS Linux release 7.7.1908 (Core)
首先就是将其IP地址修改为防火墙内规则制定的主机IP
[root@vpn ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens160
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens160"
UUID="aa08d0dd-5ba5-412c-84ab-716b885c4d89"
DEVICE="ens160"
ONBOOT="yes"
IPADDR="172.16.99.129"
PREFIX="24"
GATEWAY="192.168.99.254" # 修改成需要的IP地址
IPV6_PRIVACY="no"
PEERDNS="yes"
DNS1="114.114.114.114"
第三步 配置OpenVPN环境
在找对IP访问的映射关系之后,就是抓紧恢复服务,于是有了下面的安装配置段:
- 使用
easy-rsa制作OpenVPN所需的证书以及客户端证书
yum install openvpn
mkdir /data/tools -p
wget -P /data/tools https://github.com/OpenVPN/easy-rsa/releases/download/3.0.1/EasyRSA-3.0.1.tgz
tar zxf EasyRSA-3.0.1.tgz
cp -rf EasyRSA-3.0.1 /etc/openvpn/easy-rsa
cd /etc/openvpn/easy-rsa
./easyrsa init-pki # 初始化证书目录pki
./easyrsa build-ca nopass
# 创建根证书,提示输入Common Name,名称随意,但是不能和服务端证书或客户端证书名称相同
./easyrsa gen-dh # 生成Diffle Human参数,它能保证密钥在网络中安全传输
- 制作
CA证书
./easyrsa init-pki # 初始化证书目录pki
- 制作服务端
OpenVPN Server证书
./easyrsa build-server-full server nopass # server是服务端证书名称,可以用其它名称
- 制作客户端证书
./easyrsa build-client-full barry nopass # barry是客户端证书名称,可以用其它名称
- 配置LDAP认证
yum install openvpn-auth-ldap -y
[root@vpn openvpn]# ls -al /usr/lib64/openvpn/plugin/lib/openvpn-auth-ldap.so
-rwxr-xr-x 1 root root 133320 Sep 6 2019 /usr/lib64/openvpn/plugin/lib/openvpn-auth-ldap.so
- 准备LDAP认证配置文件
<LDAP>
# LDAP server URL
URL ldap://192.168.99.130
# Bind DN (If your LDAP server doesn't support anonymous binds)
BindDN cn=openvpn,dc=openldap,dc=kubemaster,dc=top
Password openvpn_Passsword
# Network timeout (in seconds)
Timeout 15
# Enable Start TLS
#TLSEnable no
# Follow LDAP Referrals (anonymously)
#FollowReferrals no
# TLS CA Certificate File
#TLSCACertFile /usr/local/etc/ssl/ca.pem
# TLS CA Certificate Directory
#TLSCACertDir /etc/ssl/certs
# Client Certificate and key
# If TLS client authentication is required
#TLSCertFile /usr/local/etc/ssl/client-cert.pem
#TLSKeyFile /usr/local/etc/ssl/client-key.pem
# Cipher Suite
# The defaults are usually fine here
# TLSCipherSuite ALL:!ADH:@STRENGTH
</LDAP>
<Authorization>
# Base DN
BaseDN "ou=People,dc=openldap,dc=kubemaster,dc=top"
# User Search Filter
SearchFilter "(&(uid=%u))"
# Require Group Membership
RequireGroup false
# Add non-group members to a PF table (disabled)
#PFTable ips_vpn_users
<Group>
BaseDN "ou=Groups,dc=example,dc=com"
SearchFilter "(|(cn=developers)(cn=artists))"
MemberAttribute uniqueMember
# Add group members to a PF table (disabled)
#PFTable ips_vpn_eng
</Group>
</Authorization>
- 配置服务端配置文件
[root@vpn openvpn]# cat server.conf |egrep -v '^$|^#|^\;'
port 11194
proto tcp
dev tun
ca /etc/openvpn/easy-rsa/pki/ca.crt
cert /etc/openvpn/easy-rsa/pki/issued/server.crt
key /etc/openvpn/easy-rsa/pki/private/server.key # This file should be kept secret
dh /etc/openvpn/easy-rsa/pki/dh.pem
server 10.8.0.0 255.255.255.0 # 这里是openvpn server的IP地址池
ifconfig-pool-persist ipp.txt
push "dhcp-option DNS 114.114.114.114" # 下发给客户端的DNS
push "dhcp-option DNS 8.8.8.8"
client-to-client
duplicate-cn
keepalive 10 120
comp-lzo
max-clients 50
user root
group root
persist-key
persist-tun
status openvpn-status.log
log openvpn.log
log-append openvpn.log
verb 3
mute 10
client-cert-not-required
plugin /usr/lib64/openvpn/plugin/lib/openvpn-auth-ldap.so "/etc/openvpn/auth/ldap.conf"
username-as-common-name
push "route 192.168.0.0 255.255.0.0"
push "route 192.168.99.0 255.255.255.0" # 下发给客户端的需要走VPN的网络流量,其它网段不走VPN,可正常上网。
- 开启路由转发
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
sysctl -p
OpenVPN防火墙的配置,这里是最重要的一环,注意不要把你的网络设备名称写错了。
iptables -t nat -A POSTROUTING -s 10.8.0.0/16 -o ens160 -j MASQUERADE # 网络设备为ens160
- 配置
OpenVPN的启停脚本
#!/bin/bash
echo "OpenVPN ..........[STOP]"
ps -ef |grep openvpn | grep -v grep | awk '{print $2}' | xargs kill
echo "OpenVPN ..........[START]"
/usr/local/openvpn/sbin/openvpn --config /etc/openvpn/server.conf &
- 开机服务自启,将下面内容写到
/etc/rc.local
/usr/local/openvpn/sbin/openvpn --daemon --config /etc/openvpn/server.conf > /dev/null 2>&1 &
exit 0
- 客户端的配置
# 把服务器上这三个文件拷贝下来和客户端的配置文件放在一起
/etc/openvpn/easy-rsa/pki/private/barry.key
/etc/openvpn/easy-rsa/pki/issued/barry.crt
/etc/openvpn/easy-rsa/pki/ca.crt
# 客户端配置文件内容
client
dev tun
proto tcp
resolv-retry infinite
nobind
remote PUBLIC_ADDRESS 11194 # 就是与192.168.99.129上的11194绑定的那个公网IP地址
persist-key
persist-tun
ca ca.crt
ns-cert-type server
cert barry.crt
key barry.key
verb 3 # 日志等级
comp-lzo
auth-user-pass
这样基本上就完成了OpenVPN的搭建部署,也可能是我最后一次整这玩意儿。下面是配置OpenVPN时候遇到的问题
- 明明在openvpn服务端配置了服务端同一网段的下发路由,但就是ping不通服务端同一网段的其他主机,那你需要认真检查下面的配置,包括网卡设备名
iptables -t nat -A POSTROUTING -s 10.8.0.0/16 -o ens160 -j MASQUERADE # 网络设备为ens160
sudo iptables -nL -t nat # 查看
- 为什么连上了OpenVPN我所有的流量都经过OpenVPN了,那是你启用了下面的配置,这个配置你也可以用于科学*/上网
push "redirect-gateway def1 bypass-dhcp"
- 给客户端指定固定的
VPN地址
client-config-dir ccd # 表示指定固定IP地址的客户端配置文件存储在openvpn服务端配置文件统计目录下的ccd目录里面
route 192.168.40.128 255.255.255.248 # 指定客户端IP的地址
mysql如何实现崩溃后恢复?
MySQL数据库恢复
因为我们既无法从备份恢复,也无法从ibdata1 启动恢复,这个时候我们需要将我们的数据库表以及数据库表数据恢复。
首先我们需要安装一个新的数据库哈,记住了新装一个数据库:
准备工作:
在执行任何操作之前,请将老数据库“ \bin\mysql\mysql5.6.12\data”的完整副本复制备份
我们的恢复需要做的事:是将每个表以及每个表的数据恢复:
你有文件夹 \bin\mysql\mysql5.6.12\data\mydb
在该文件夹中,您有
mytable.frm
mytable.ibd
.frm 表结构
.ibd 实际表数据
开始恢复数据库
cd /
[root@izwz99z5o9dc90keftqhlrz ~]# mkdir download
[root@izwz99z5o9dc90keftqhlrz ~]# cd /download
[root@izwz99z5o9dc90keftqhlrz ~]# wget https://cdn.mysql.com/archives/mysql-utilities/mysql-utilities-1.6.5.tar.gz
[root@izwz99z5o9dc90keftqhlrz ~]# tar xvf mysql-utilities-1.6.5.tar.gz
[root@izwz99z5o9dc90keftqhlrz ~]# cd mysql-utilities-1.6.5
[root@izwz99z5o9dc90keftqhlrz ~]# python setup.py build
[root@izwz99z5o9dc90keftqhlrz ~]# python setup.py install
[root@izwz99z5o9dc90keftqhlrz ~]# mysqldiff --versio
通过 .frm 文件识别表结构
把 .frm 文件上传至linux路径,识别表结构命令如下
[root@izwz99z5o9dc90keftqhlrz ~]# mysqlfrm --diagnostic /download/data/sys_menu.frm
myisam和innodb各自在什么场景使用?"
MyISAM引擎的特点
1、不支持事务(事务就是逻辑上的一组SQL语句操作,组成这组操作的各个SQL语句,执行时要么全部成功,要么全部失败)
2、表级锁定(更新是锁整个表):其锁定机制是表级锁定,虽然可以让锁定的实现成本很小,但是大大的降低了其并发性能。
小结:MyISAM锁定的范围太大
3、读写互相堵塞:不仅会在写入的时候阻塞读取,MyISAM还会在读取的时候阻塞写入,但读本身并不会阻塞另外的读。
4、只会缓存索引:MyISAM可以通过key_buffer_size缓存索引,大大提高访问性能,减少磁盘的I/O,但是缓存区只会缓存索引,不会缓存数据。
5、读取速度较快,占用资源相对少。
6、不支持外键约束,但支持全文索引。
7、MyISQM引擎是mysql_5.5.5之前的索引。
MyISAM引擎使用的生产业务场景
、不需要事务支持的业务(转账、充值、付款这种就不行)。
2、一般为读数据比较多的应用。读写都频繁的不适合,读多或写多都适合。
3、并发访问相对低的业务(纯读、纯写高并发也可以)。
4、数据修改相对较少的业务(阻塞问题)。
5、以读为主的业务,例如:www,blog,图片信息数据库,用户数据库,商品库等业务。
6、对数据一致性要求不是很高的业务。
7、硬件资源比较差的机器可以用MyISAM。
小结:单一对数据库的操作都可以使用MyISAM引擎。
InnoDB引擎特点
、支持事务:支持事务的四个级别(ACID)。
2、行级锁定:通过索引实现,全表扫描仍然是表锁。
3、读写阻塞与事务隔离级别相关。
4、具有非常高效的缓存特性:能缓存索引,也能缓存数据。
5、整个表和主键以cluster方式存储,组成一颗平衡树。
6、所有secondary inex都会保存主键信息。
7、支持分区,表空间,类似oracle数据库。
8、支持外键约束,不支持全文索引。5.5版本以前不支持全文索引,5.5版本之后支持。
9、和MyISAM相比对硬件的资源要求比较高。
InnoDB引擎适用的生产应用场景
1、需要事务支持的业务(具有较好的事务特性)。
2、行级锁定对高并发有很好的适用能力,但需要确保查询是通过索引来来完成的。
3、数据读写及更新都较为频繁的场景,如:BBS、SNS、微博等。
4、数据一致性要求较高的业务,如:充值转账。
5、硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存使用率,尽可能的较少磁盘的I/O。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号