哈希算法与一致性哈希算法
哈希算法:取哈希后模节点的数目
假设有一个由A、B、C三个节点组成的KV服务,每个节点存放不同的KV数据。通过哈希算法,每个key都可以寻址到对应的服务器,比如,查询key是key-01,计算公式为hash(key-01)%3,经过计算寻址到了编号为1的服务器节点A
但如果服务器数量发生变化,基于新的服务器数量来执行哈希算法的时候,就会出现路由寻址失败的情况,Proxy无法找到之前寻址到的那个服务器节点
假如3个节点不能满足业务需求了,这时增加了一个节点,节点的数量从3变化为4,那么之前的hash(key-01)%3=1就变成了hash(key-01)%4=X,因为取模运算发生了变化,所以这个X大概率不是1(假设是2),这时再查询就会找不到数据了,因为key-01对应的数据存储在节点A上
一致性哈希算法:取哈希后模2^32
哈希算法是对节点的数量进行取模运算,而一致性哈希是对2^32取模。
一致性哈希将整个哈希值空间组成一个虚拟的圆环,也就是哈希环:
在一致性哈希中,通过执行哈希算法,将节点映射到哈希环上。假设哈希算法函数为c-hash(),比如选择节点的主机名作为参数执行c-hash(),每个节点就能确定其在哈希环上的位置:
当需要对指定key的值进行读写的时候,通过下面2步进行寻址:
将key作为参数执行c-hash()计算哈希值,并确定此key在环上的位置
从这个位置沿着哈希环顺时针行走,遇到的第一个节点就是key对应的节点
假设key-01、key-02、key-03三个key,经过哈希算法c-hash()计算后,在哈希环上的位置如下图:
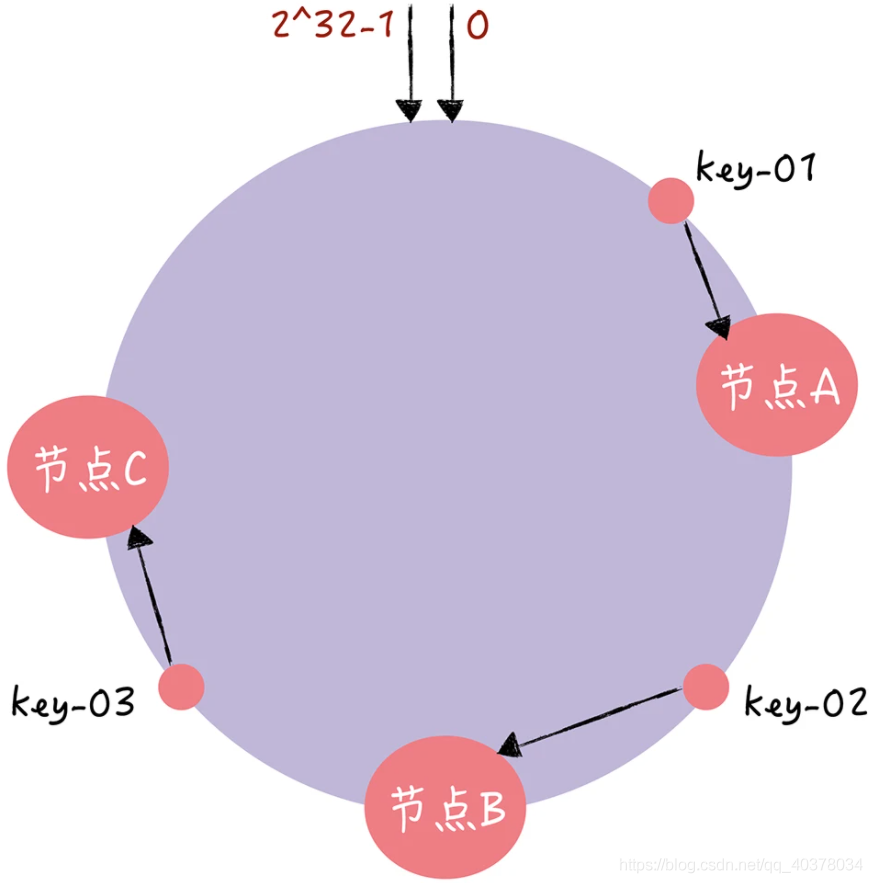
1)假设,现在节点C故障了:
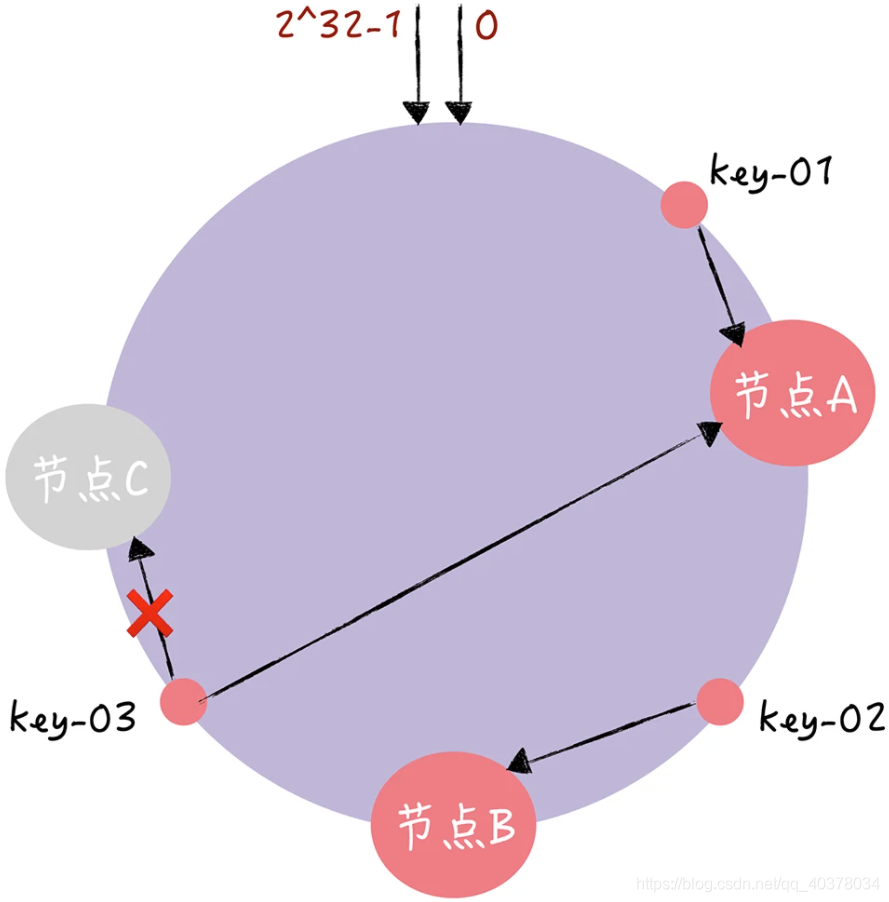
可以看到,key-01和key-02不会受到影响,只有key-03的寻址被重定位到A。在一致性哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是会寻址到此节点和前一节点之间的数据。比如当节点C宕机了,受影响的数据是会寻址到节点B和节点C之间的数据(例如key-03),寻址到其他哈希环空间的数据不会受到影响
2)如果需要扩容一个节点:
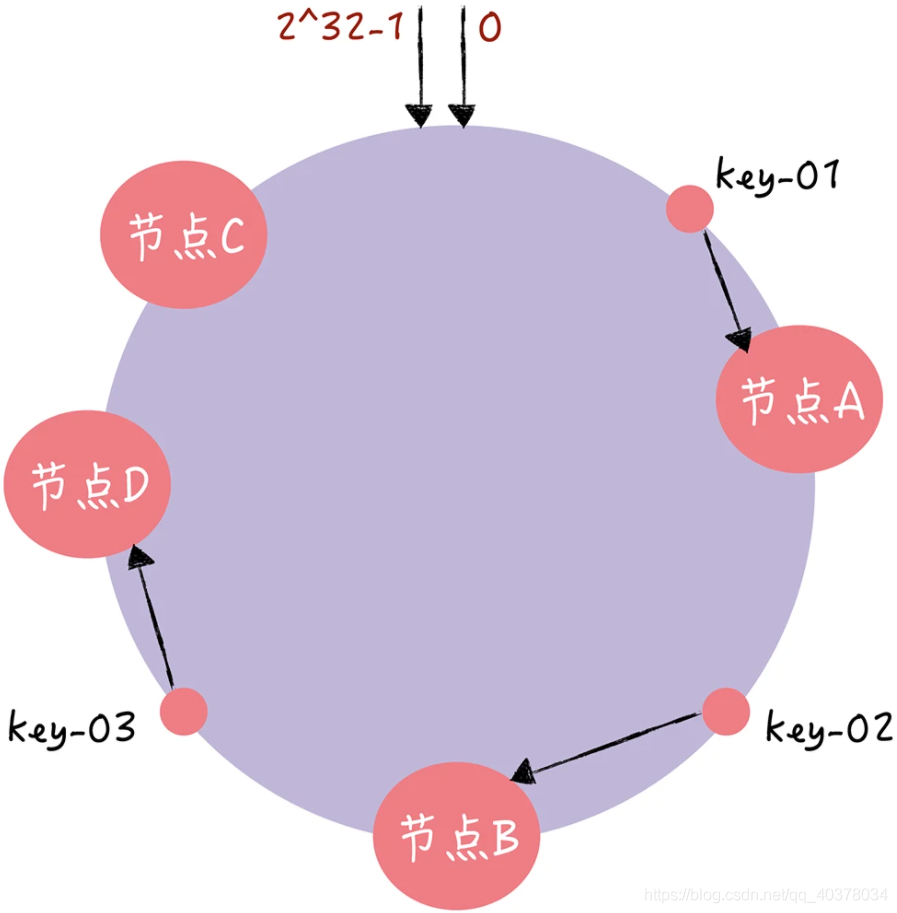
可以看到,key-01、key-02不受影响,只有key-03的寻址被重定位到新节点D。在一致性哈希算法中,如果增加一个节点,受影响的数据仅仅是会寻址到新节点和前一节点之间的数据
使用了一致哈希算法后,扩容或缩容的时候,都只需要重定位环空间中的一小部分数据。也就是说,一致哈希算法具有较好的容错性和可扩展性
当节点数越多的时候,使用哈希算法时,需要迁移的数据就越多,使用一致哈希时,需要迁移的数据就越少
3)、节点太少分布不均匀
在一致性哈希算法中,如果节点太少,容易因为节点分布不均匀造成数据访问的冷热不均,也就是说大多数访问请求都会集中少量几个节点上:

上图中,虽然有3个节点,但访问请求主要集中在节点A上
通过引入虚拟节点解决分布不均匀的问题。对每一个服务器节点计算多个哈希值,每个计算结果位置上都放置一个虚拟节点,并将虚拟节点映射到实际节点。比如,可以在主机名后面增加编号,分别计算Node-A-01、Node-A-02、Node-B-01、Node-B-02、Node-C-01、Node-C-02的哈希值,于是形成6个虚拟节点


 浙公网安备 33010602011771号
浙公网安备 33010602011771号