ConcurrentHashMap 源码分析 (jdk1.8)
jdk1.7分析
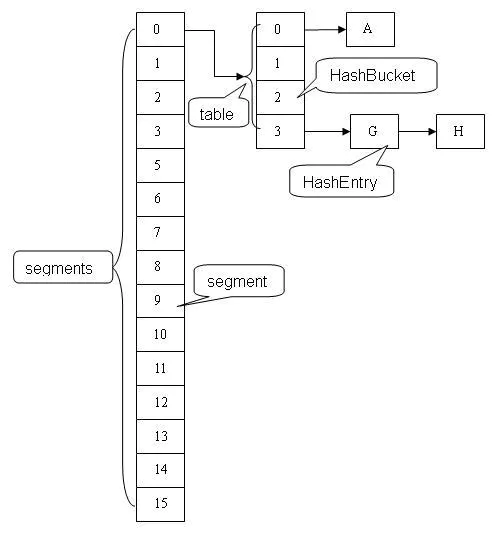
ConcurrentHashMap采用 分段锁的机制,实现并发的更新操作,底层采用数组+链表的存储结构。
其包含两个核心静态内部类 Segment和HashEntry。
Segment继承ReentrantLock用来充当锁的角色,每个 Segment 对象守护每个散列映射表的若干个桶。
HashEntry 用来封装映射表的键 / 值对;
每个桶是由若干个 HashEntry 对象链接起来的链表。
一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组,下面我们通过一个图来演示一下 ConcurrentHashMap 的结构:
jdk1.8分析
1.8的实现已经抛弃了Segment分段锁机制,利用CAS+Synchronized来保证并发更新的安全,底层采用数组+链表+红黑树的存储结构。
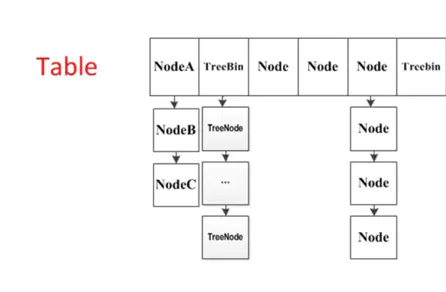
Node
Node:保存key,value及key的hash值的数据结构。
class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
... 省略部分代码
}
ForwardingNode:一个特殊的Node节点,hash值为-1,其中存储nextTable(扩容后的表)的引用。
final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
只有table发生扩容的时候,ForwardingNode才会发挥作用,作为一个占位符放在table中表示当前节点为null或者已经被移动。
1.初始化 new ConcurrentHashMap();

同hashmap一样,无参构造并没有真正初始化,真正初始化是在第一次put数据时
2.有参构造 new ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel);
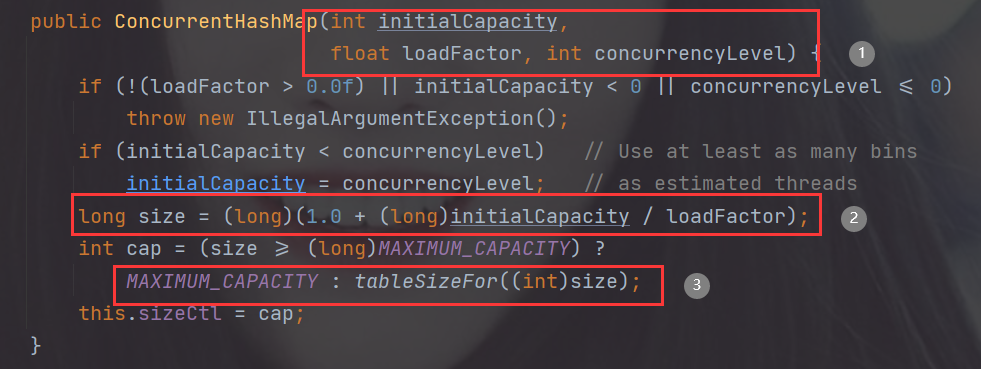
1.一共有三个参数,initialCapacity是实际容量,loadFactor是负载因子(默认为0.75,是经验值), concurrencyLevel是并发级别(默认为1)
2.计算出我们需要的table的长度,由于实际容量=table的长度*loadFactor,则table的长度=实际容量/loadFactor
3.tableSizeFor()算出我们实际需要的table的长度cap。确保总是2的幂,比如initialCapcity是100则计算出的cap为256。这里cap有最大值为2^30
3.第一次put数据,初始化table
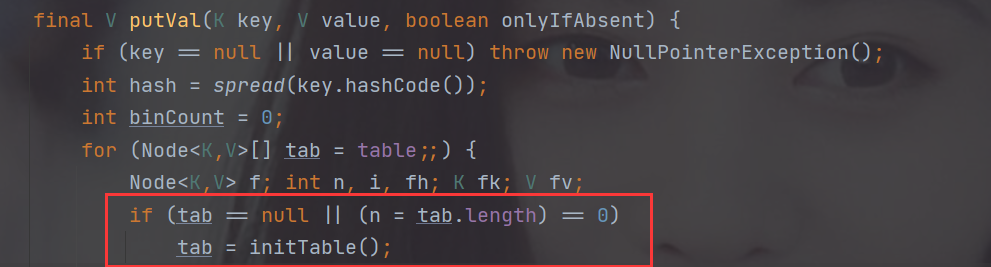
首先介绍一个重要的变量:
sizeCtl :默认为0,用来控制table的初始化和扩容操作
- -1 代表table正在初始化
- -N 表示有N-1个线程正在进行扩容操作
如果sizeCtl>0:
- 如果table未初始化,表示table需要初始化的大小
- 如果table初始化完成,表示table的容量,默认是table大小的0.75倍
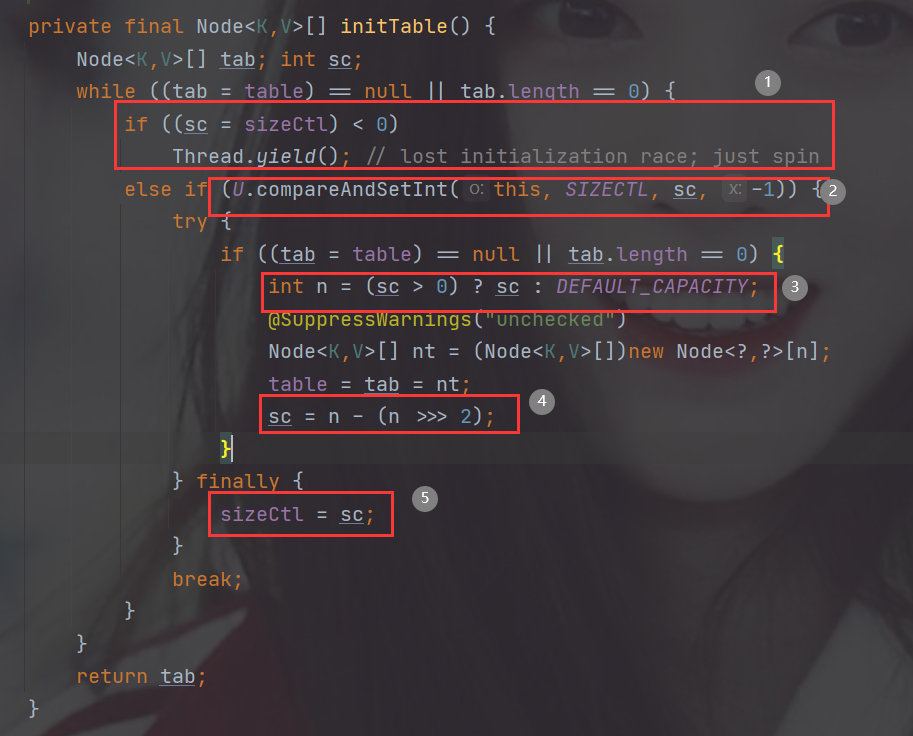
1.首先判断sizeCtl是否<0,如果是则说明已经有线程在初始化table(Node[])了,就把当前线程挂起
2.通过CAS操作将sizeCtl设置为-1,注意只有一个线程可以设置成功继续往下运行
3.判断我们传进来的sizeCtl(sc记录了函数刚传进来时的sizeCtl)是否>0,如果大于零则这个sizeCtl的值为 table需要初始化的大小,否则为table为默认的大小16
4.sc = n - (n >>> 2); 实际上是计算 0.75*table的长度= table的可用的容量。 很奇怪,真正的容量不应该是 table的长度 * 负载因子 吗? 为什么乘固定值0.75?
5.把table真正容量赋给sizeCtl
4.put操作
首先计算key的hash值,计算在table中的位置,采用CAS操作判断该位置有没有元素,如果该位置没有元素的话。采用一个CAS操作,放入Node节点

问什么要用tabat方法要采用CAS方法getReferenceVolatile获得table指定索引的元素而不是直接table[index]?
在java内存模型中,我们已经知道每个线程都有一个工作内存,里面存储着table的副本,虽然table是volatile修饰的,但不能保证线程每次都拿到table中的最新元素,Unsafe.getReferenceVolatile可以直接获取指定内存的数据,保证了每次拿到数据都是最新的。
如果CAS添加Node成功后会执行addCount(1L, binCount);方法 判断是否需要扩容
如果CAS失败,说明有别的线程在添加这个元素,会自旋重复以上流程
如果该位置的Node的hash值为 -1则说明当前Node是ForwardingNode节点,意味有其它线程正在扩容,则一起进行扩容操作。
其余情况把新的Node节点按链表或红黑树的方式插入到合适的位置,这个过程采用同步内置锁实现并发
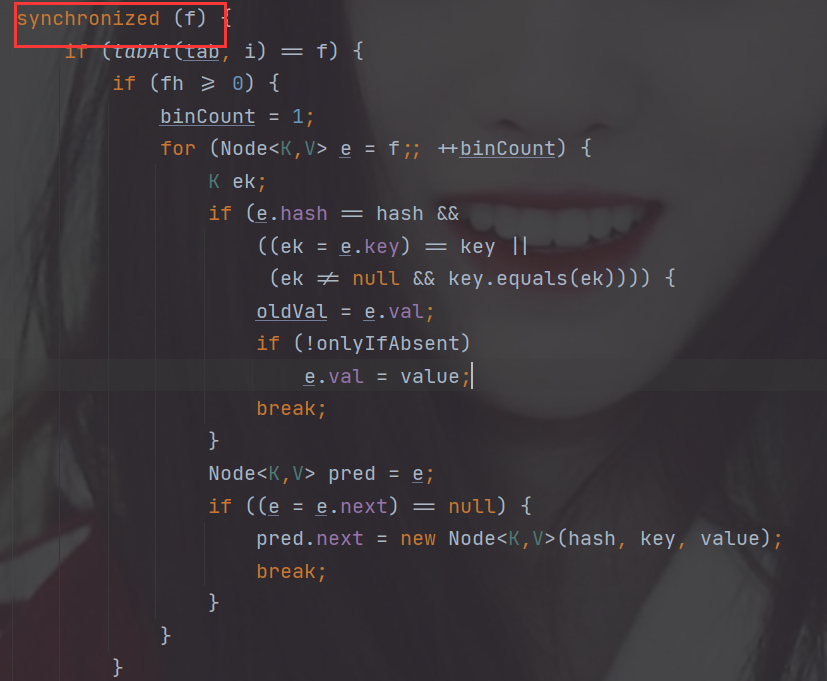
我们可以看到只是对需要操作的Node节点加锁,而不是对整个ConcurrentHashMap(这也是与HashTable的最大不同,HashTable是对整个表加锁)
我们可以看到,这里红黑树的节点是TreeBin
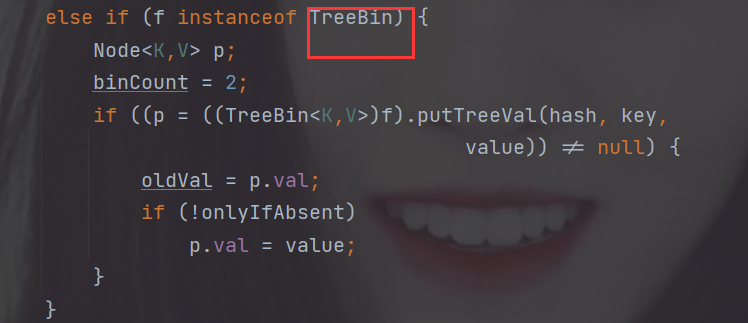
再然后判断节点数如果>=8 则树化(注意树的bitcount被赋值为2,也就是说只有链表的bitcount才有可能>=8 只有链表能树化!)
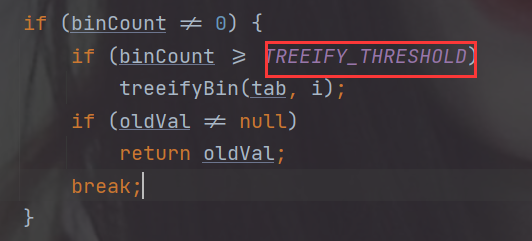
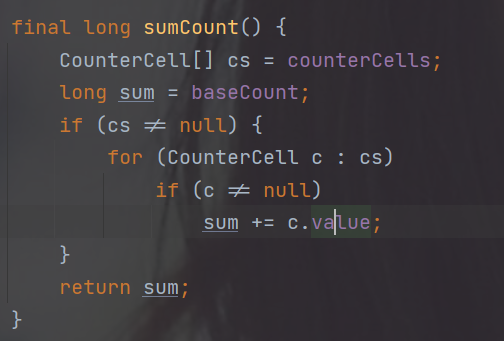
5.addCount()
在putVal方法执行完成以后,会通过addCount来增加ConcurrentHashMap中的元素个数
那么如何保证addCount的并发安全呢?(有多个线程对ConcurrentHashMap进行了增加)

1.该方法有两个参数,x是增加的元素个数,check是是否进行扩容检查,check>=0就要进行扩容检查
2.首先我们通过CAS操作,对baseCount进行增加,注意此时只有一个线程能对baseCount进行增加

3.CAS失败的线程会转去对CounterCell[] 进行增加。每个线程会取该数组的一个随机元素进行增加

4.最后真正的节点个数是 baseCount+CounterCell[]中所有元素总和
6.扩容操作
当 更新后的键值对总数 >= 阈值sizeCtl时候,即table的元素数量达到容量阈值sizeCtl,需要对table进行扩容。
整个扩容分为两部分:
构建一个nextTable,大小为table的两倍。
把table的数据复制到nextTable中。
这两个过程在单线程下实现很简单,但是ConcurrentHashMap是支持并发插入的,扩容操作自然也会有并发的出现,这种情况下,第二步可以支持节点的并发复制,这样性能自然提升不少,但实现的复杂度也上升了一个台阶。
先看第一步,构建nextTable,毫无疑问,这个过程只能只有单个线程进行nextTable的初始化,具体实现如下:
1.还是通过CAS操作修改sizeCtl的值,确保只有一个线程能够构建nextTable (数组的长度是原来的两倍)


然后把Node从Table移动到nextTable:
ConcurrentHashMap按照每个线程处理一个区间内的数据迁移 进行调度,比如线程A处理索引[0-15]位置的 线程B处理索引[16-31]位置的....
1.首先根据运算得到需要遍历的次数i,然后利用tabAt方法获得i位置的元素f,初始化一个forwardingNode实例fwd。

2.然后通过对需要移动的Node加锁的方式,实现并发安全

3.如果f == null,则在table中的i位置放入fwd。表明该位置已经迁移过或者正在迁移。其他线程遍历到这个位置发现节点是forwardingNode,会跳过该位置。

4.如果f是链表的头节点,就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上,移动完成,采用Unsafe.putObjectVolatile方法给table原位置赋值fwd。
5.如果f是TreeBin节点,也做一个反序处理,并判断是否需要untreeify,把处理的结果分别放在nextTable的i和i+n的位置上,移动完成,同样采用Unsafe.putObjectVolatile方法给table原位置赋值fwd。
6.get操作
get操作就非常简单了
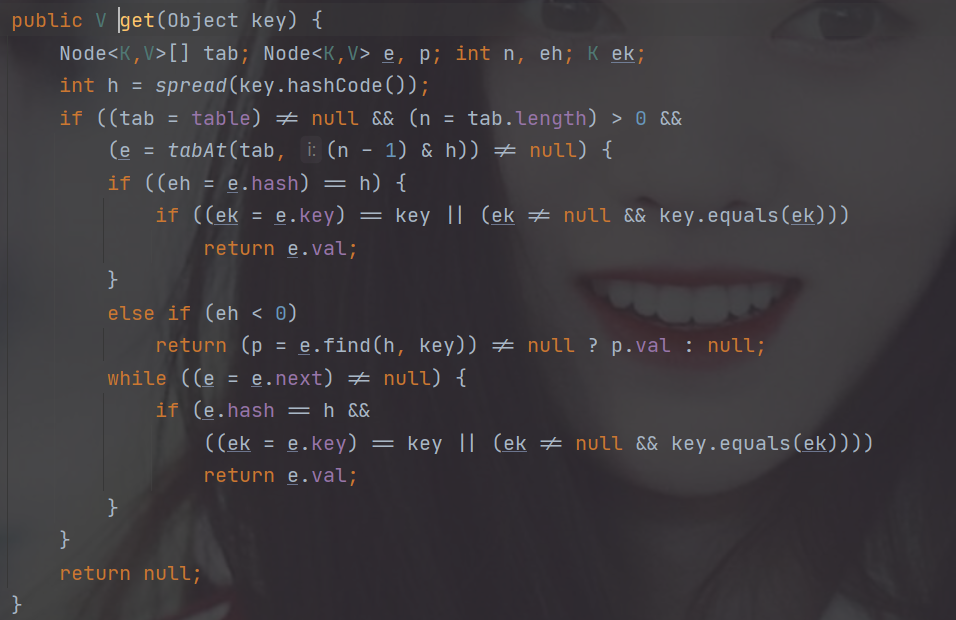
1.判断table是否为空,如果为空,直接返回null。
2.计算key的hash值,并获取指定table中指定位置的Node节点,通过遍历链表或则树结构找到对应的节点,返回value值。
整个过程也并没有涉及并发安全的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号