hadoop-2.6.0-cdh5.4.5.tar.gz(CDH)的3节点集群搭建(含zookeeper集群安装)
关于几个疑问和几处心得!
a.用NAT,还是桥接,还是only-host模式?
答: hostonly、桥接和NAT
b.用static的ip,还是dhcp的?
答:static
c.别认为快照和克隆不重要,小技巧,比别人灵活用,会很节省时间和大大减少错误。
d.重用起来脚本语言的编程,如paython或shell编程。
对于用scp -r命令或deploy.conf(配置文件),deploy.sh(实现文件复制的shell脚本文件),runRemoteCdm.sh(在远程节点上执行命令的shell脚本文件)。
e.重要Vmare Tools增强工具,或者,rz上传、sz下载。
f.大多数人常用

Xmanager Enterprise *安装步骤
用到的所需:
1、VMware-workstation-full-11.1.2.61471.1437365244.exe
2、CentOS-6.5-x86_64-bin-DVD1.iso
3、jdk-7u69-linux-x64.tar.gz
4、hadoop-2.6.0-cdh5.4.5.tar
5、apache-cassandra-2.2.1-bin.tar.gz
6、apache-flume-1.6.0-bin.tar.gz
7、apache-tomcat-7.0.65.tar.gz
8、flume-ng-1.5.0-cdh5.4.5.tar.gz
9、hbase-1.0.0-cdh5.4.5.tar.gz
10、hive-1.1.0-cdh5.4.5.tar.gz
11、protobuf-2.5.0.tar.gz
12、sqoop-1.4.5-cdh5.4.5.tar.gz
13、zookeeper-3.4.5-cdh5.4.5.tar.gz
机器规划:
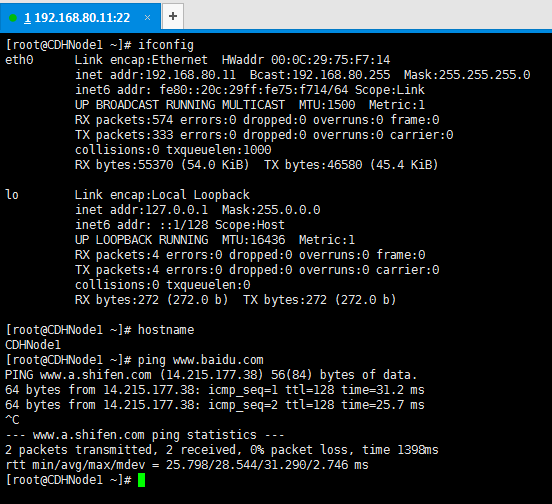
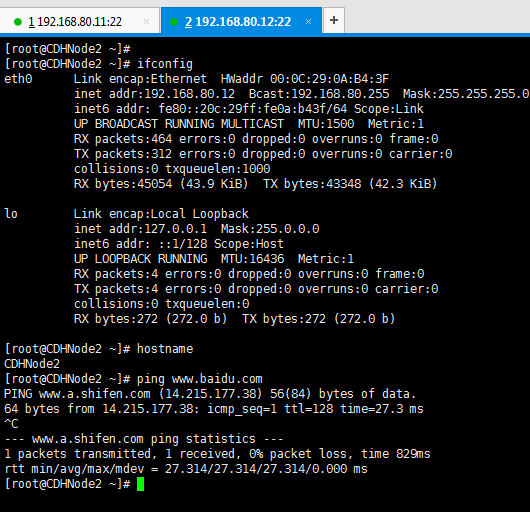
192.168.80.11 ---------------- CDHNode1
192.168.80.12 ---------------- CDHNode2
192.168.80.13 ---------------- CDHNode3
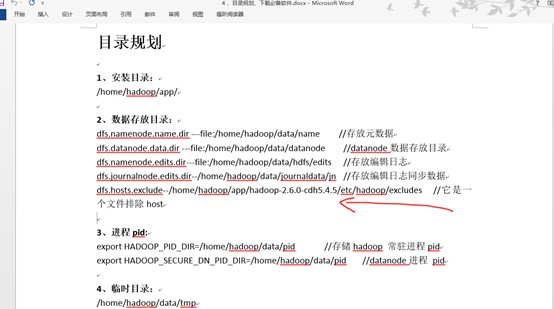
目录规划:
1、安装目录:
/home/hadoop/app/
2、数据存放目录:
dfs.namenode.name.dir ---file:/home/hadoop/data/name //存放元数据
dfs.datanode.data.dir ---file:/home/hadoop/data/datanode //datanode数据存放目录
dfs.namenode.edits.dir---file:/home/hadoop/data/hdfs/edits //存放编辑日志
dfs.journalnode.edits.dir--/home/hadoop/data/journaldata/jn //存放编辑日志同步数据
dfs.hosts.exclude--/home/hadoop/app/hadoop-2.6.0-cdh5.4.5/etc/hadoop/excludes //它是一个文件排除host
3、进程pid:
export HADOOP_PID_DIR=/home/hadoop/data/pid //存储hadoop 常驻进程pid
export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/data/pid //datanode进程 pid
4、临时目录:
/home/hadoop/data/tmp
第一步:安装VMware-workstation虚拟机,我这里是VMware-workstation11版本。
详细见 ->
VMware workstation 11 的下载
VMWare Workstation 11的安装
VMware Workstation 11安装之后的一些配置
第二步:安装CentOS系统,我这里是6.6版本。推荐(生产环境中常用)
详细见 ->
CentOS 6.5的安装详解
CentOS 6.5安装之后的网络配置
CentOS 6.5静态IP的设置(NAT和桥接都适用)
CentOS 命令行界面与图形界面切换
网卡eth0、eth1...ethn谜团
Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置
第三步:VMware Tools增强工具安装
详细见 ->
VMware里Ubuntukylin-14.04-desktop的VMware Tools安装图文详解
第四步:准备小修改(学会用快照和克隆,根据自身要求情况,合理位置快照)
详细见 ->
CentOS常用命令、快照、克隆大揭秘
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
1、ssh的安装(SSH安装完之后的免密码配置,放在后面)
2、静态IP的设置
3、hostname和/etc/hosts
4、永久关闭防火墙
5、时间同步
1 软件环境准备
|
虚拟机 |
VMWare11 |
|
操作系统 |
CentOS6.5 |
|
JDK |
|
|
远程连接 |
XShell |
|
|
|
2 主机规划
由于我要安装3个节点的集群环境,所以我们分配好ip地址和主机功能
|
|
CDHNode1 /192.168.80.11 |
CDHNode2 /192.168.80.12 |
CDHNode3 /192.168.80.13 |
|
namenode |
是 |
是 |
否 |
|
datanode |
否 |
是 |
是 |
|
resourcemanager |
是 |
是 |
否 |
|
journalnode |
是 |
是 |
是 |
|
zookeeper |
是 |
是 |
是 |
|
日志采集服务器 |
是 |
是 |
否 |
|
采集服务器负载均衡 |
是 |
是 |
是 |
|
目标网站(web)程序 |
是 |
否 |
是 |
注意:Journalnode和ZooKeeper保持奇数个,最少不少于 3 个节点。
3 CDHNode1、CDHNode2、CDHNode3的静态IP、网络配置、主机名、用户名和用户组
1、 CDHNode1、CDHNode2、CDHNode3的Linux安装省略,不再赘述。

2、 CDHNode1、CDHNode2、CDHNode3的静态IP、网络配置、主机名、用户名、用户组

新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
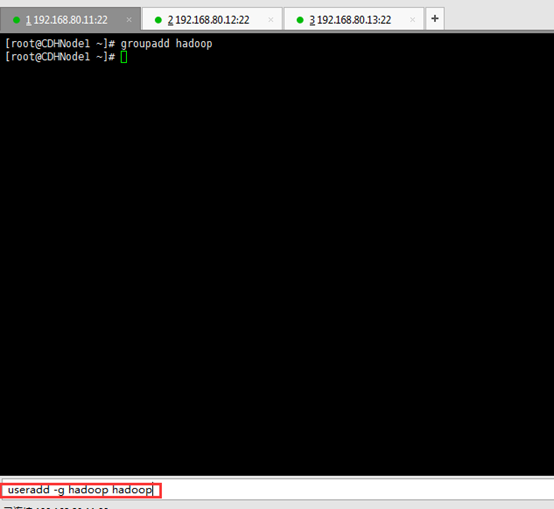
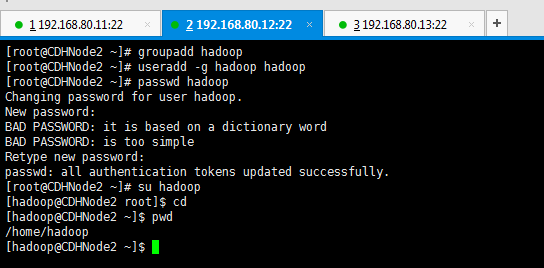
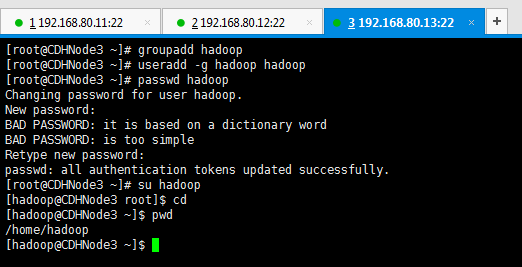
groupadd hadoop 创建hadoop用户组
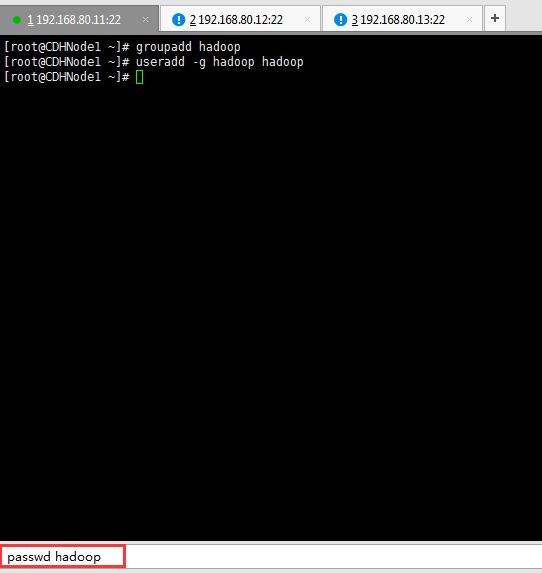
useradd -m -g hadoop hadoop 新建hadoop用户并增加到hadoop用户组中
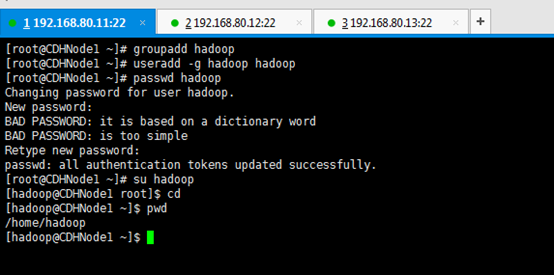
passwd hadoop hadoop用户密码,为hadoop
 ‘’
‘’
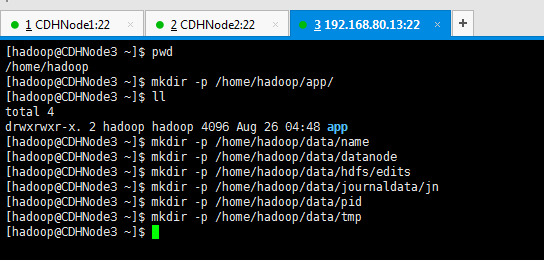
4 、目录规划、下载必备软件
目录规划
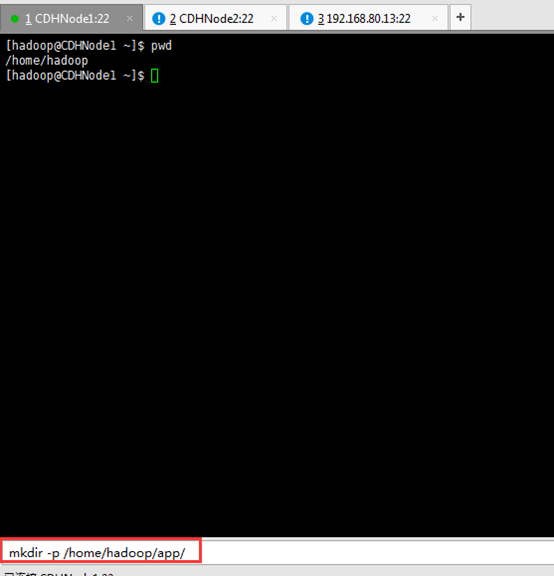
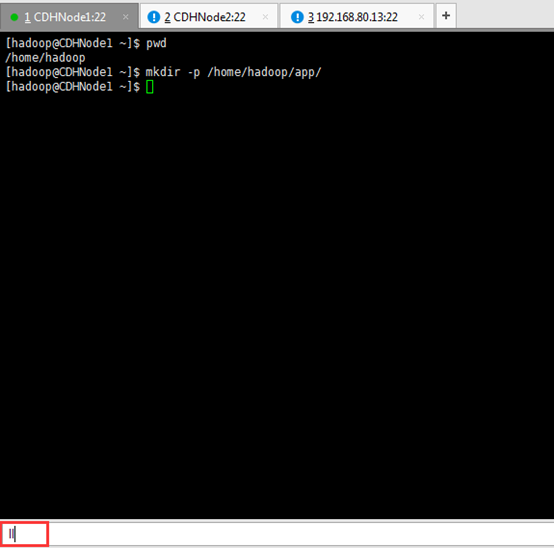
1、安装目录:
/home/hadoop/app/
2、数据存放目录:
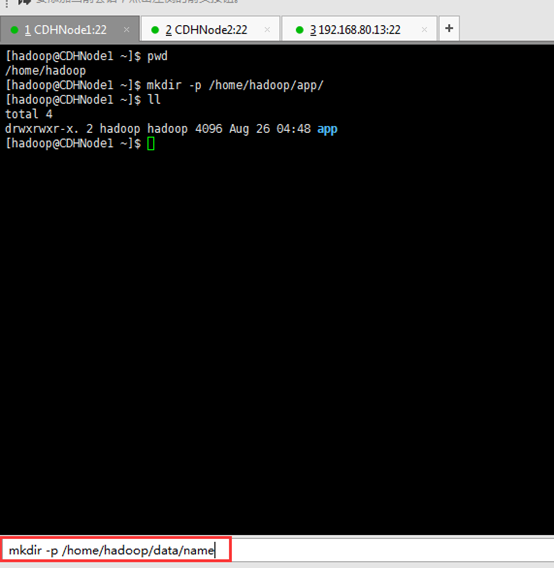
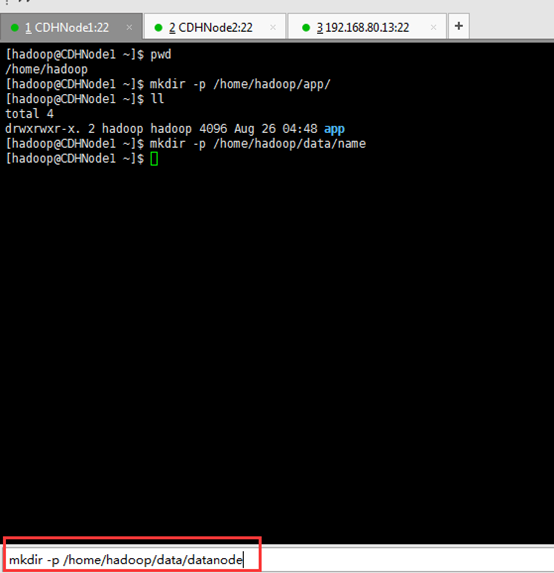
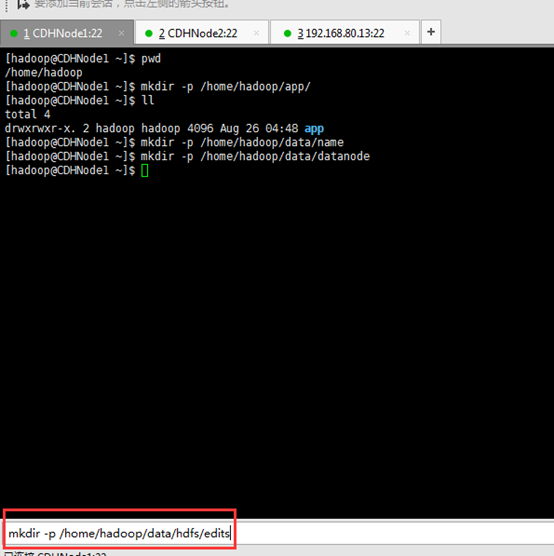
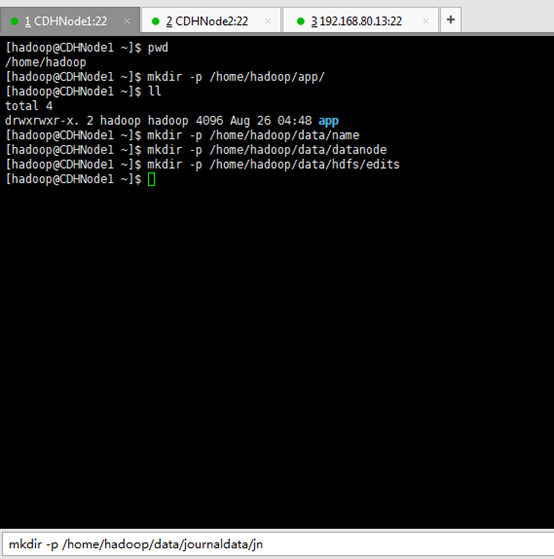
dfs.namenode.name.dir ---file:/home/hadoop/data/name //存放元数据
dfs.datanode.data.dir ---file:/home/hadoop/data/datanode //datanode数据存放目录
dfs.namenode.edits.dir---file:/home/hadoop/data/hdfs/edits //存放编辑日志
dfs.journalnode.edits.dir--/home/hadoop/data/journaldata/jn //存放编辑日志同步数据
dfs.hosts.exclude--/home/hadoop/app/hadoop-2.6.0-cdh5.4.5/etc/hadoop/excludes //它是一个文件排除host
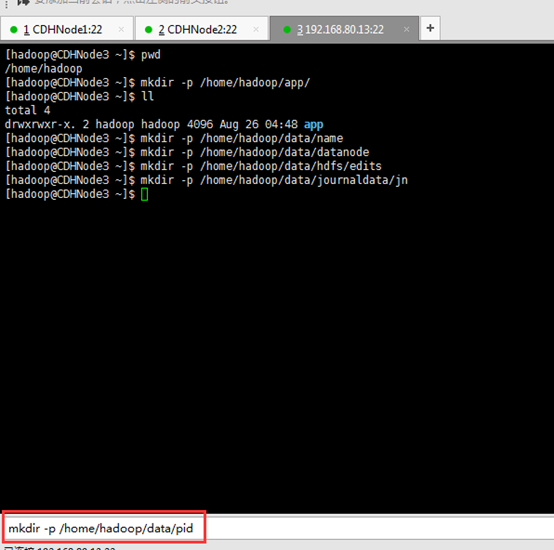
3、进程pid:
export HADOOP_PID_DIR=/home/hadoop/data/pid //存储hadoop 常驻进程pid
export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/data/pid //datanode进程 pid
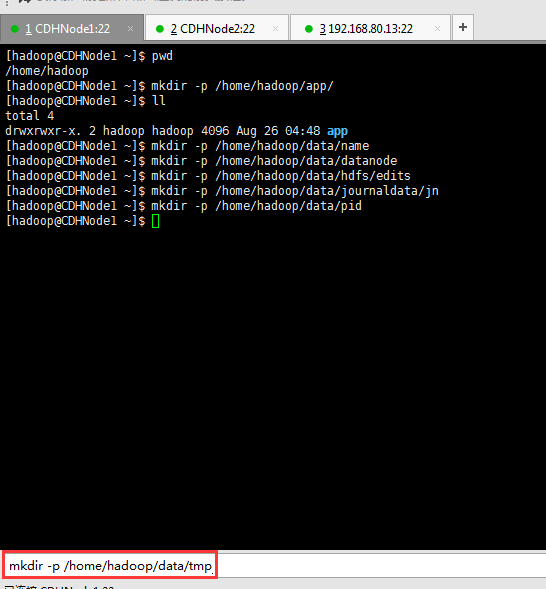
4、临时目录:
/home/hadoop/data/tmp


1、安装目录:
/home/hadoop/app/
2、数据存放目录:
dfs.namenode.name.dir ---file:/home/hadoop/data/name //存放元数据
dfs.datanode.data.dir ---file:/home/hadoop/data/datanode //datanode数据存放目录
dfs.namenode.edits.dir---file:/home/hadoop/data/hdfs/edits //存放编辑日志
dfs.journalnode.edits.dir--/home/hadoop/data/journaldata/jn //存放编辑日志同步数据
dfs.hosts.exclude--/home/hadoop/app/hadoop-2.6.0-cdh5.4.5/etc/hadoop/excludes //它是一个文件排除host
dfs.hosts.exclude--/home/hadoop/app/hadoop-2.6.0-cdh5.4.5/etc/hadoop/excludes //它是一个文件排除host
等到后面,解压了hadoop-2.6.0-cdh5.4.5的安装包后,再新建。
3、进程pid:
export HADOOP_PID_DIR=/home/hadoop/data/pid //存储hadoop 常驻进程pid
export HADOOP_SECURE_DN_PID_DIR=/home/hadoop/data/pid //datanode进程 pid
4、临时目录:
/home/hadoop/data/tmp
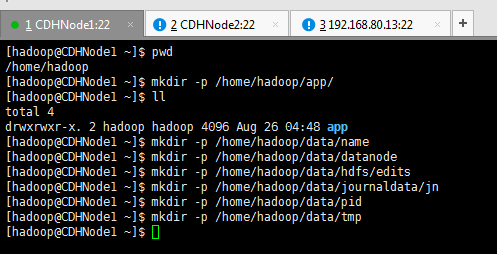
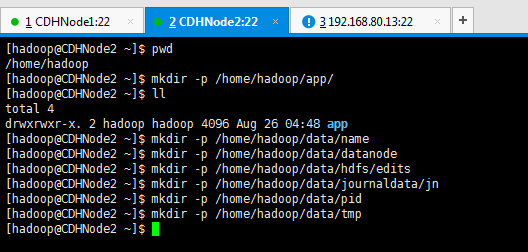
下载必备软件
注:1、在CDHNode1节点上安装,使用yum命令 ,参数-y表示,下载过程中的自动回答yes,有兴趣的话,可以试试不加的情况;install表示从网上下载安装。
2、使用yum命令安装软件必须是root用户。
1、安装lrzsz,可以方便在Xshell上,上传和下载文件,输入rz命令,可以上传文件,sz命令可以从远程主机上下载文件到本地。

2、安装ssh服务器。




3、安装ssh客户端。


5、永久关闭防火墙、时间同步

只有在关机重启后,生效。



关机后,重启。再查看下


时间同步
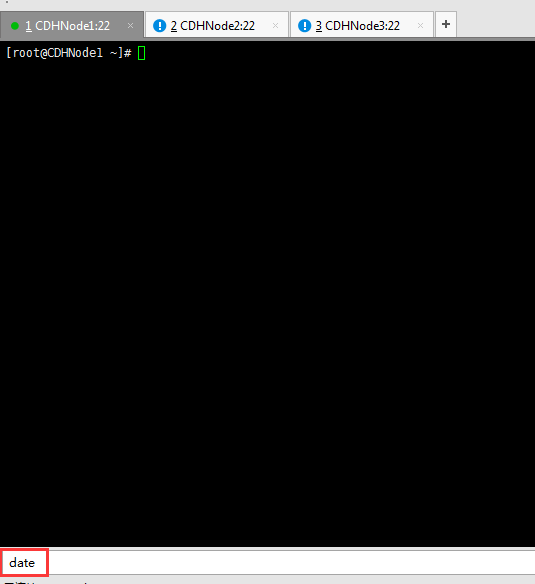
1、我们先使用date命令查看当前系统时间
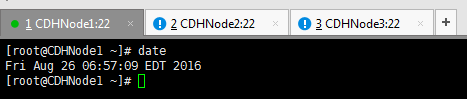


如果系统时间与当前时间不一致,可以按照如下方式修改。
2、查看时区设置是否正确。我们设置的统一时区为Asia/Shanghai,如果时区设置不正确,可以按照如下步骤把当前时区修改为上海。
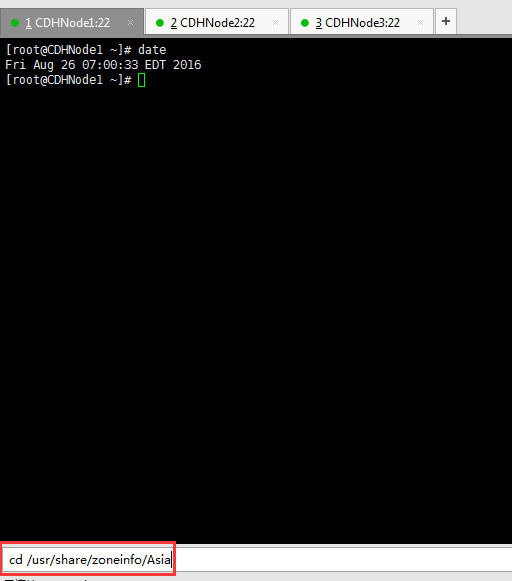

cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime

3、下面我们使用ntp(网络时间协议)同步时间。如果ntp命令不存在,则需要在线安装ntp
4、安装ntp后,我们可以使用ntpdate命令进行联网时间同步。
ntpdate pool.ntp.org
ntpdate pool.ntp.org

5、最后我们在使用date命令查看,时间是否同步成功。


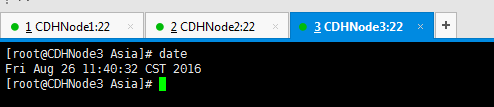
由此可见,我们的时钟同步,完成。
方便操作
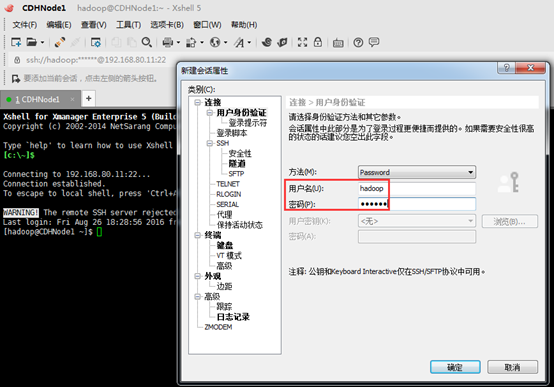
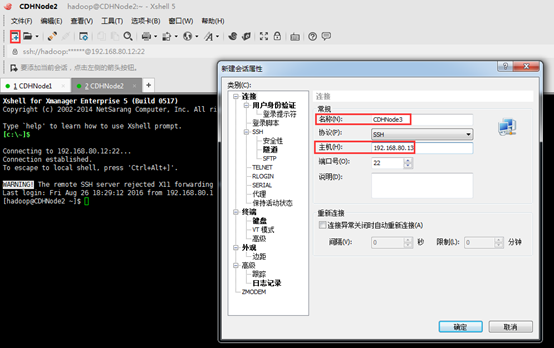
1、 首先点击新建按钮,如下;在新建会话属性对话框中输入名称和需要连接的主机ip地址。

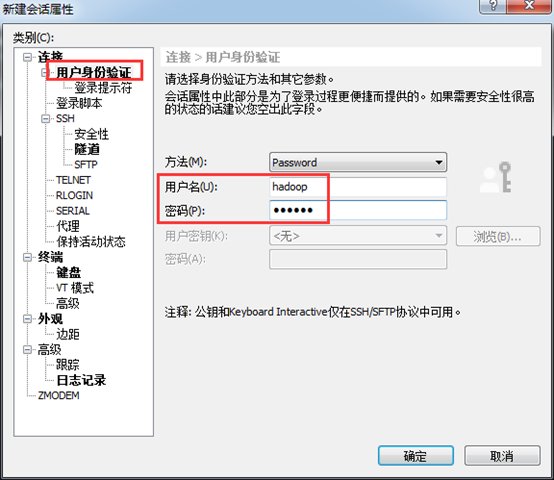
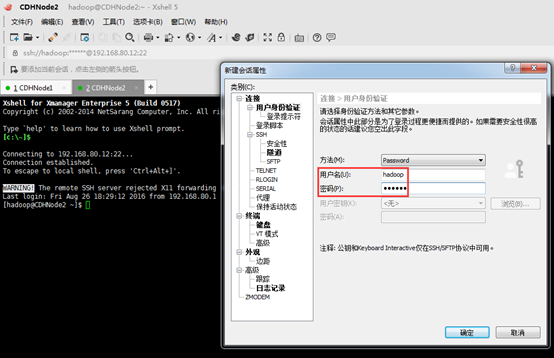
2、 接下来点击左侧的用户身份验证,输入要登录主机的用户名和密码,点击确定,此时创建成功。
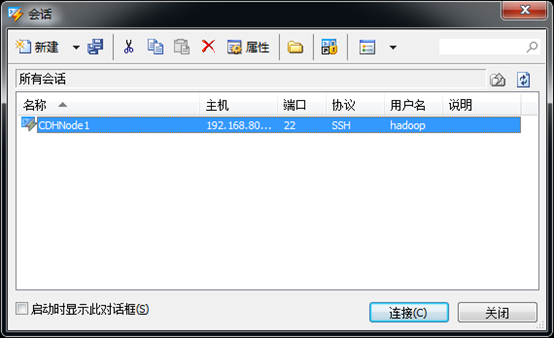
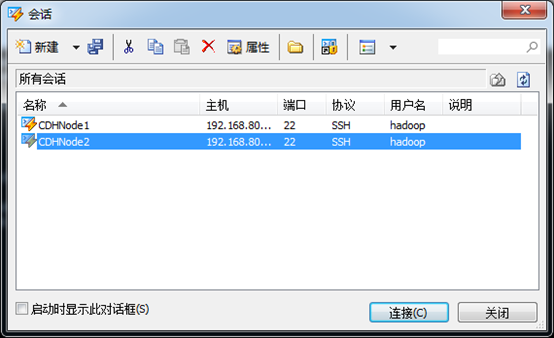
3、 在打开会话对话框中选中刚创建的CDHNode1,然后点击连接
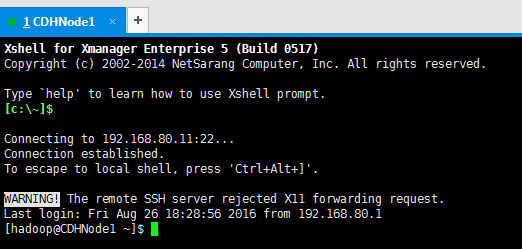
4、 此时连接成功,即可进行远程操作
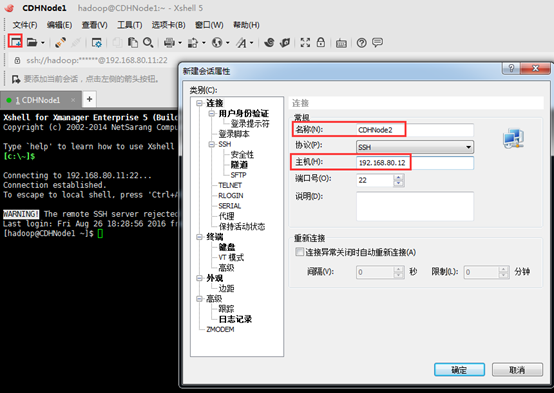
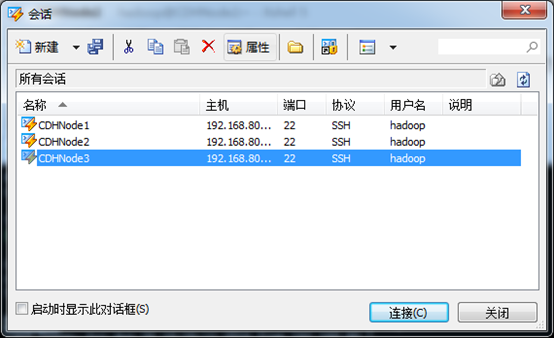
5、为了以后方便打开远程主机,我们可以把当前连接的主机添加到链接栏中,只需点击添加到链接栏按钮即可添加
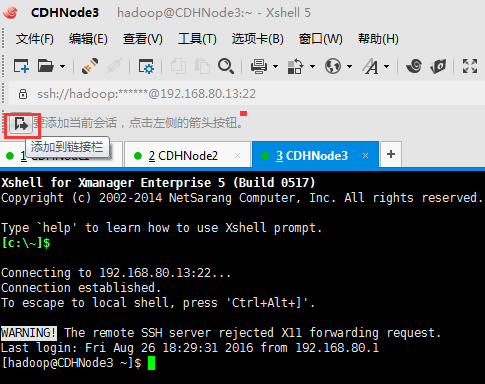

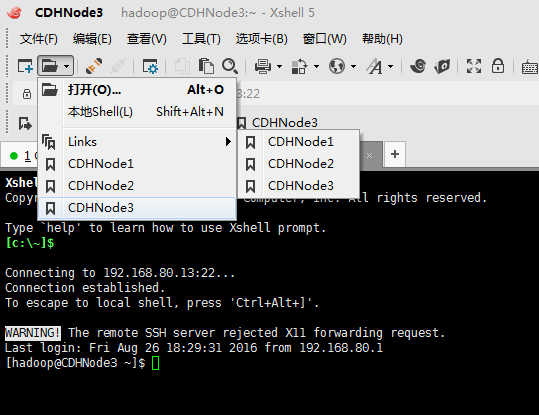
这样以后,就很方便啦。
6、上传hadoop-2.6.0-cdh5.4.5.tar.gz安装包和SSH免密码登录

在master上启动start-dfs.sh,master上启动namenode,在slave1和2上启动datanode。
那这是如何做到的呢?有兴趣,可以看看。这就是要做免密码登录的必要!
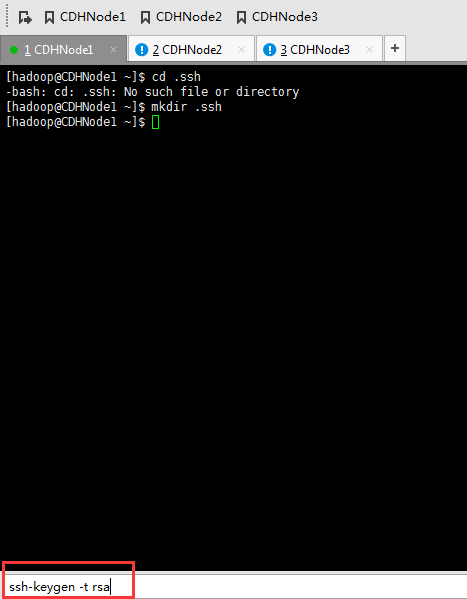
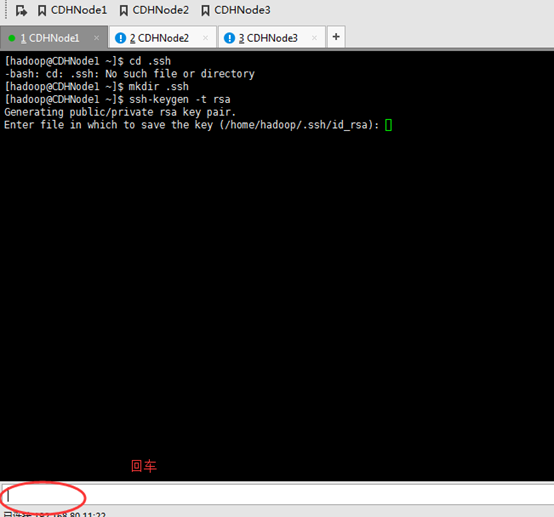

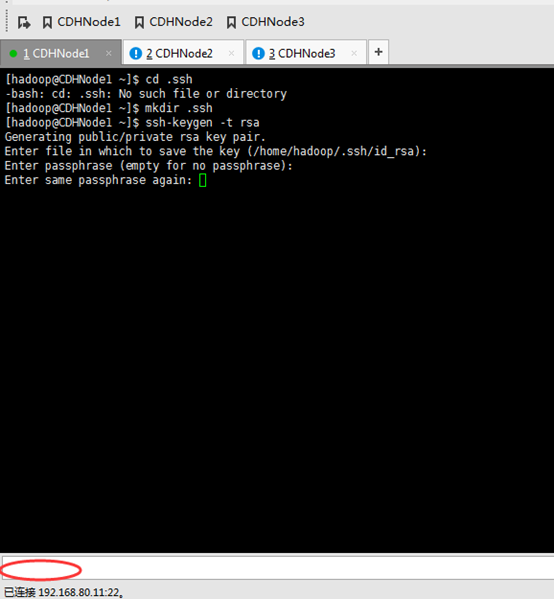
这里,三处都回车。
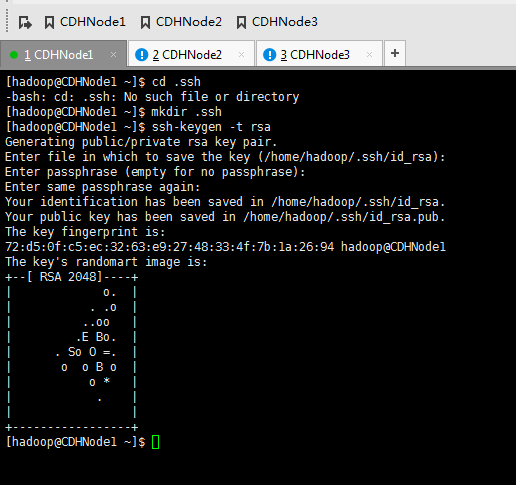

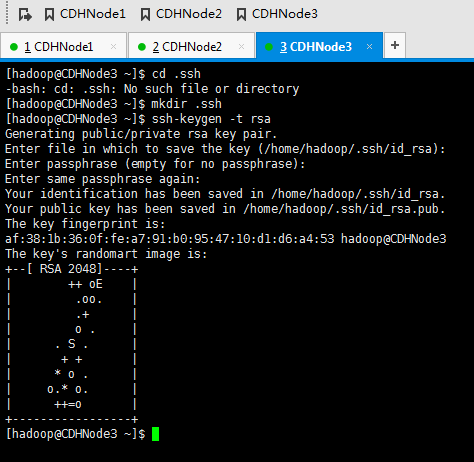
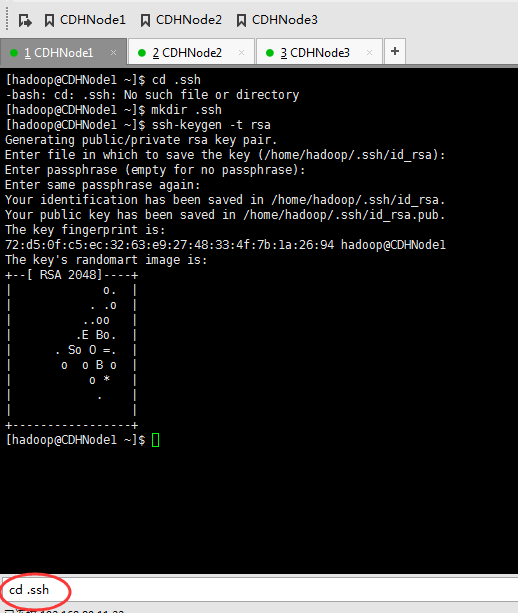
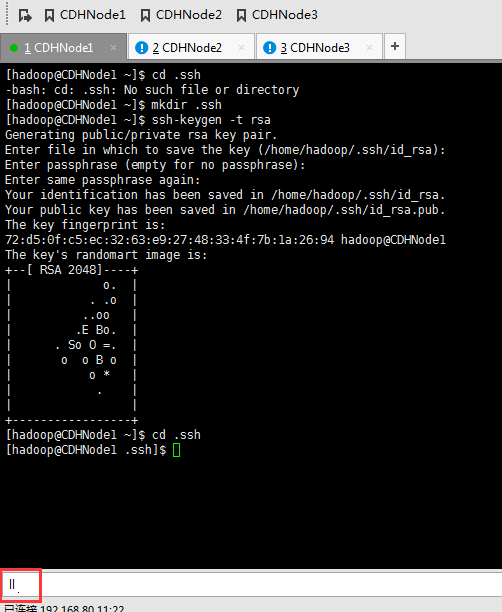
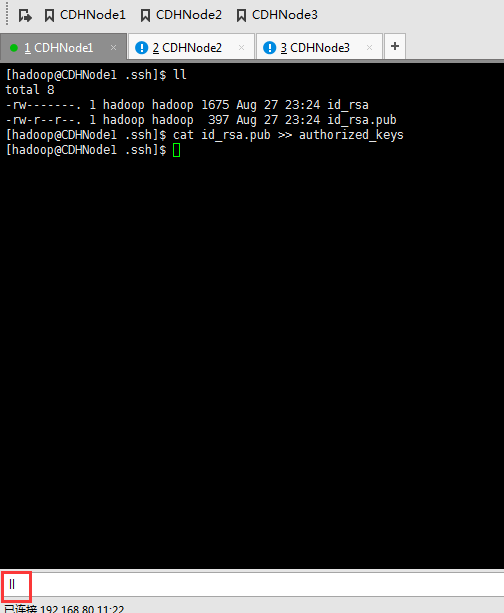
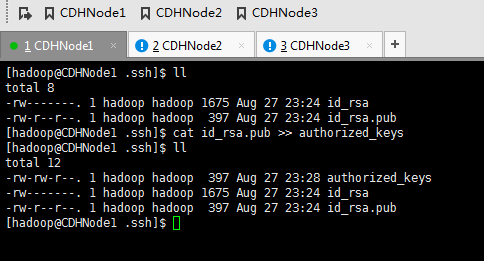
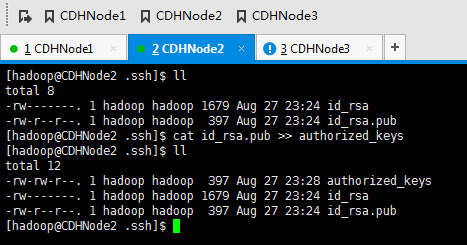
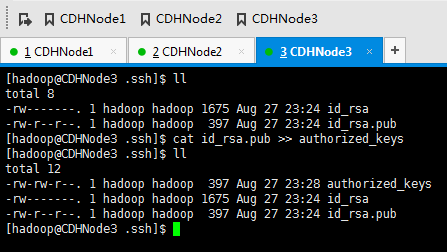
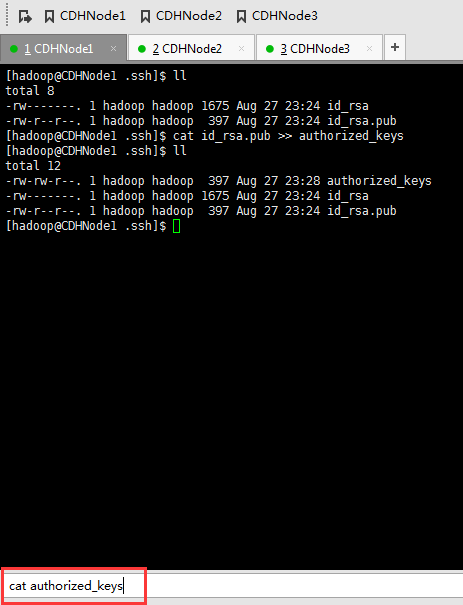

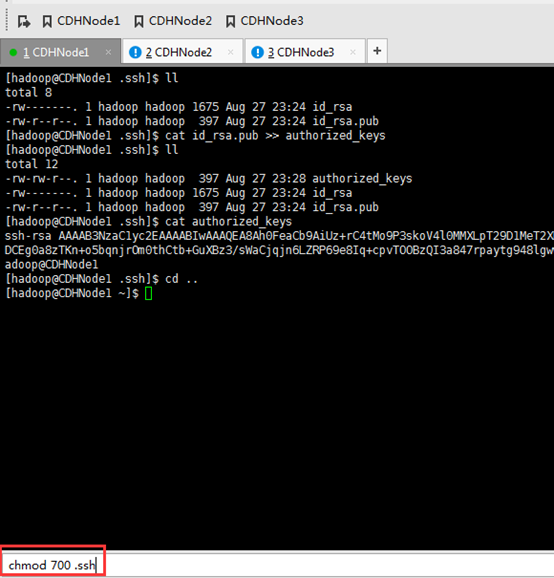

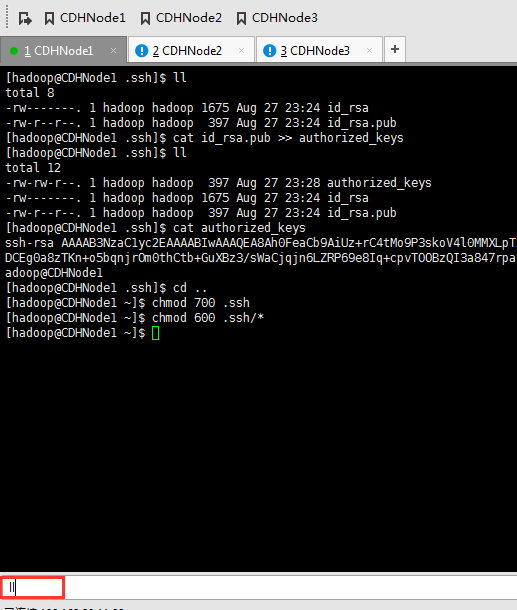
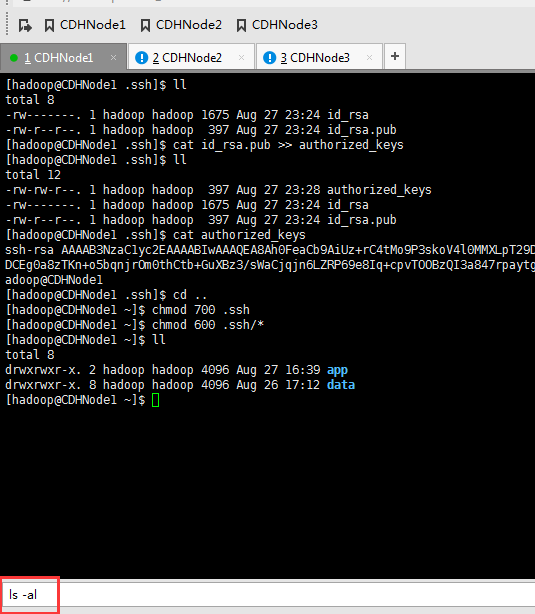
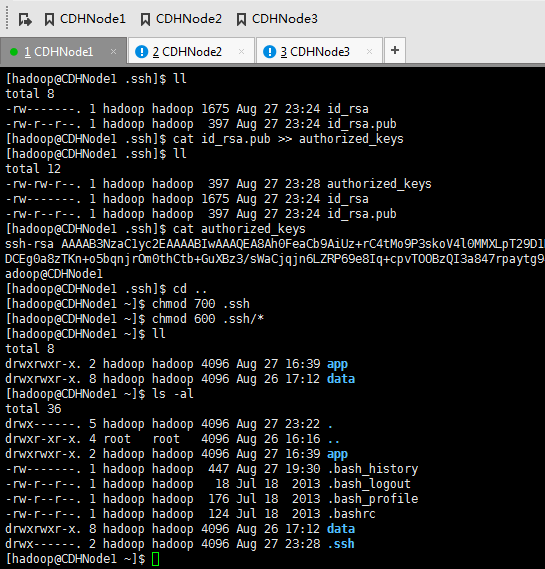
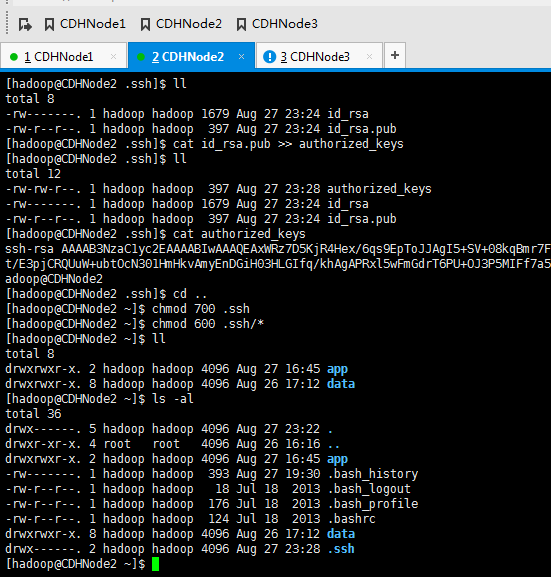
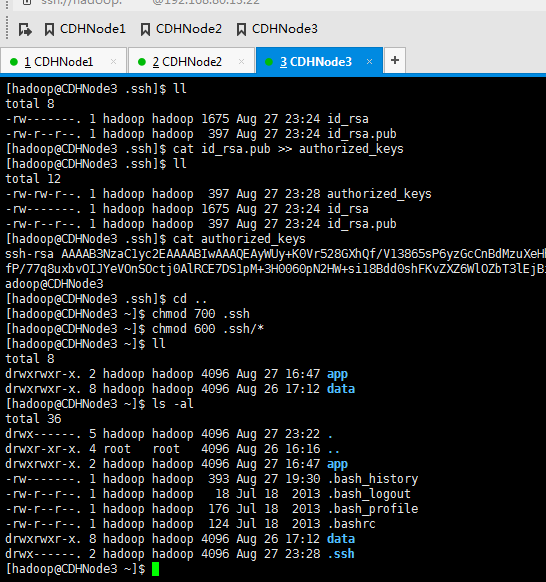
现在,来进入SSH免密码登录的设置。
总的来说:
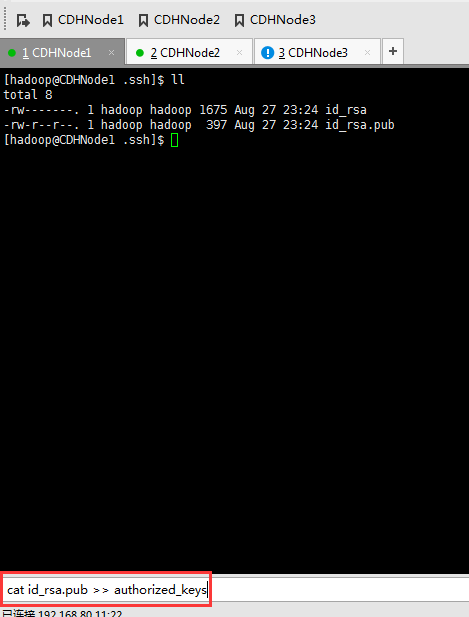
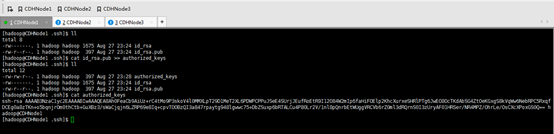
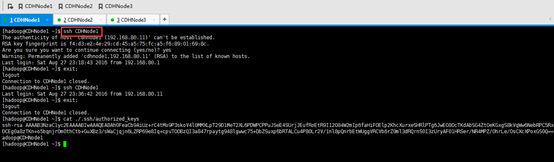
1、 集群里的每台机器自己本身的无密码访问设置
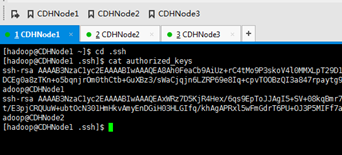
CDHNode1本身、CDHNode2本身、CDHNode3本身
CDHNode1本身
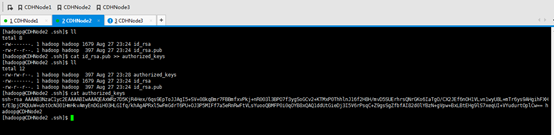
CDHNode2本身

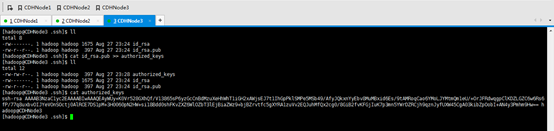
CDHNode3本身
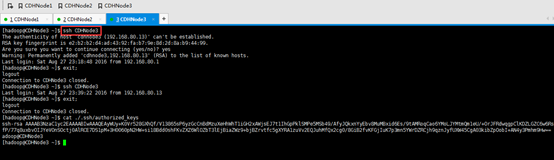
1、 集群里的每台机器自己本身的无密码访问设置
CDHNode2与 CDHNode1、CDHNode3与CDHNode1、然后CDHNode1分发~/.ssh/ authorized_keys
CDHNode2与 CDHNode1

CDHNode3与 CDHNode1
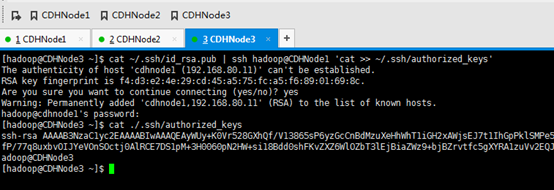
cat ~/.ssh/id_rsa.pub | ssh hadoop@CDHNode1 'cat >> ~/.ssh/authorized_keys'
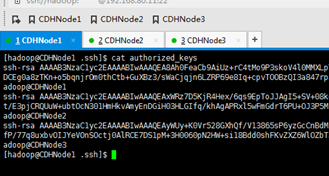
将CDHNode1的~/.ssh/ authorized_keys,分发给CDHNode2
知识点:用自己写好的脚本,也可以,或者,用scp命令

scp -r authorized_keys hadoop@CDHNode2:~/.ssh/

将CDHNode1的~/.ssh/ authorized_keys,分发给CDHNode3

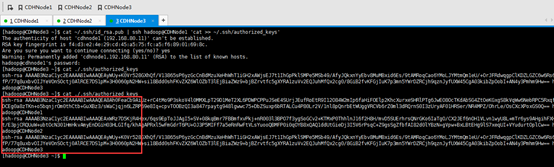
至此,集群间机器完成SSH免密码登录。
7、上传jdk-7u79-linux-x64.tar安装包和jdk环境变量配置
若是有自带的java,一定将其卸载。
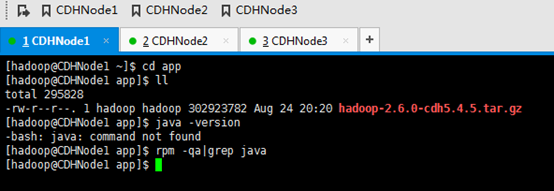

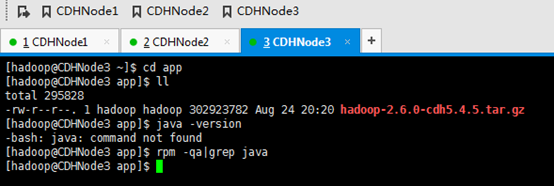
rpm -qa|grep java命令查出没有
注意:
一般在生产上,部署一个集群时候,我们的用户是很多的,比如有hadoop用户、hbase用户、hive用户、zookeeper用户等。。。
这样,我们若将jdk安装到hadoop用户的主目录下,则出现其他的用户无法使用,很麻烦,
强烈建议,安装在/usr/local 或 /usr/share

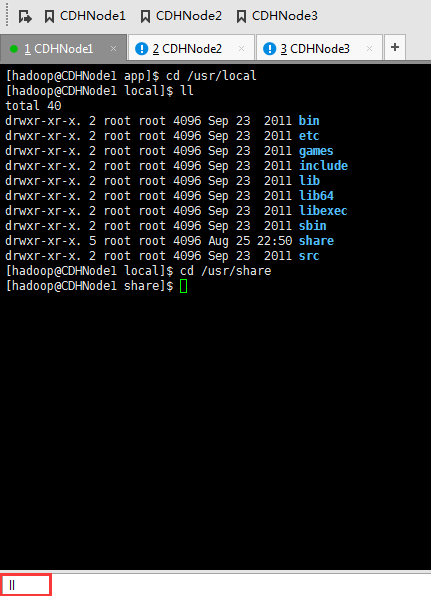

实际上,jdk自带的它默认就是安装在这个目录底下,嘿嘿
而我这里,没自带,所以,没对应的java目录。
好,现在开始上传jdk-7u79-linux-x64.tar.gz
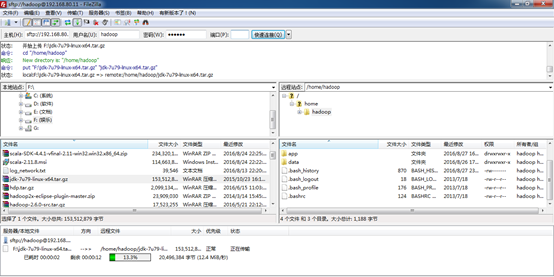
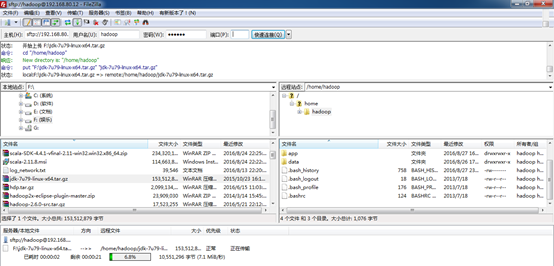


在生产环境里,一般jdk安装在/usr/local或/usr/share。这里,我们选择/usr/share

这里要注意,知识点,必须是root用户才可以。
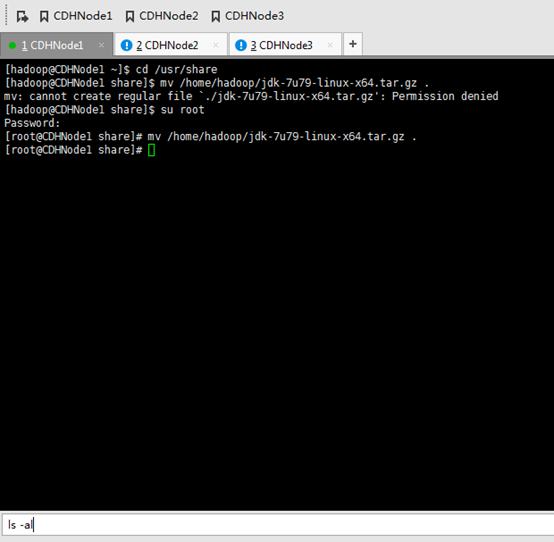
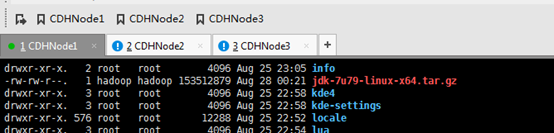
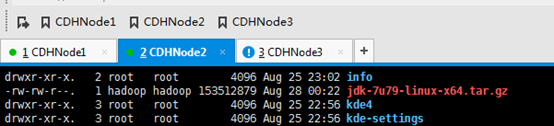

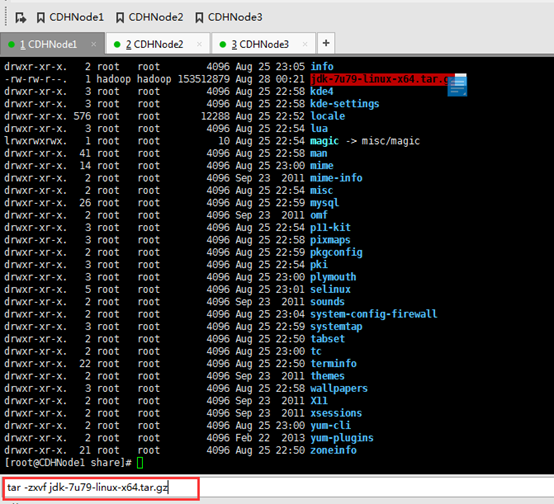


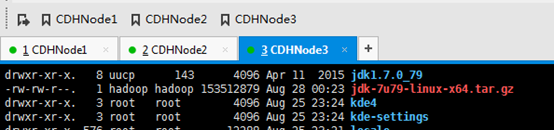
改下,uucp。并删除,jdk压缩包
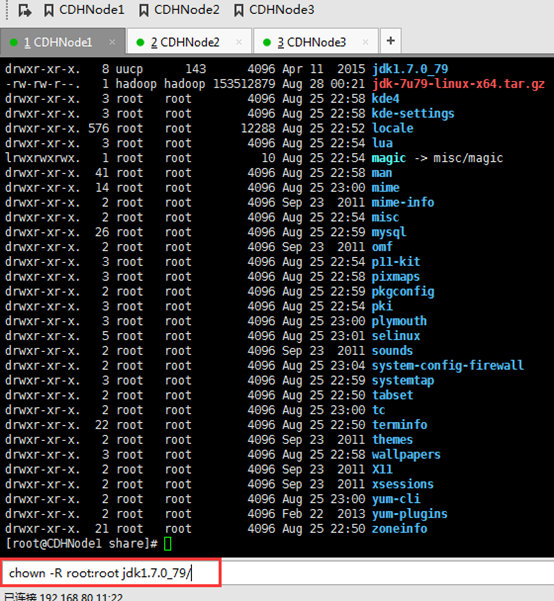
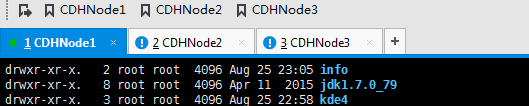
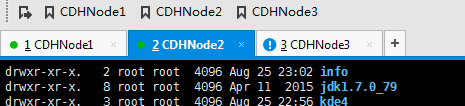
退回到hadoop用户
总结,在实验里,就没分那么多用户了,hadoop用户、hive用户、zookeeper用户、、、
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。


#java
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
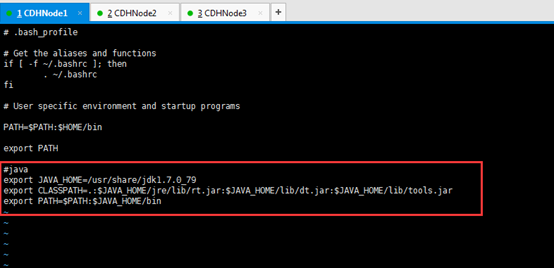
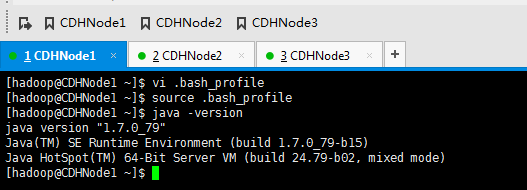
为了偷懒,

scp -r .bash_profile hadoop@CDHNode2:~
scp -r .bash_profile hadoop@CDHNode3:~

8、HDFS核心配置文件的配置和exclueds文件创立
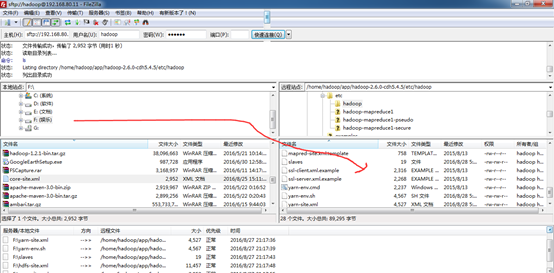
学会技巧,一般,先在NotePad++里写好,
直接传上去。
删除压缩包,留下压缩后的文件夹。

其他两个一样
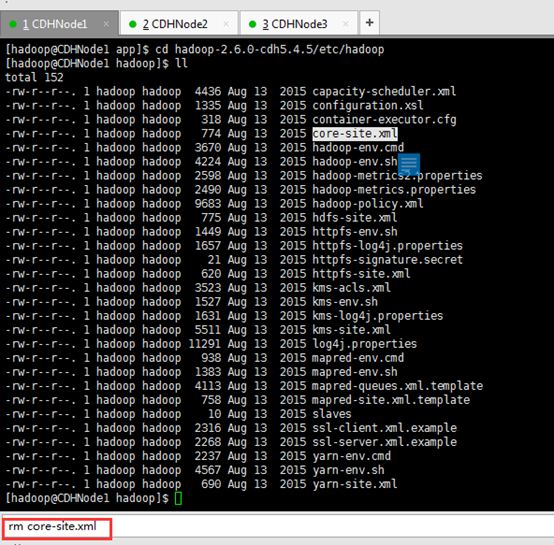
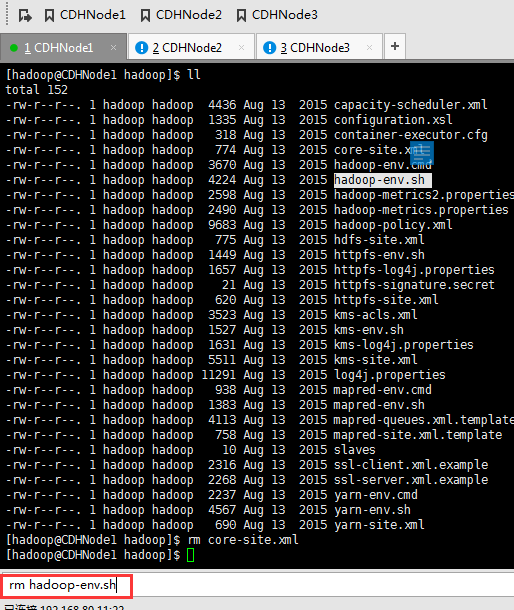
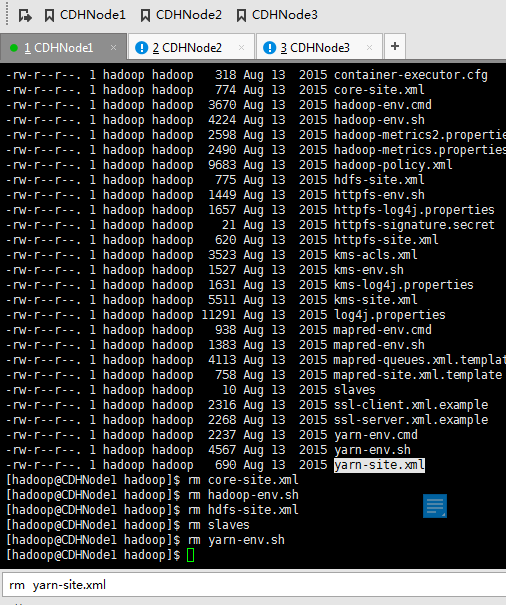
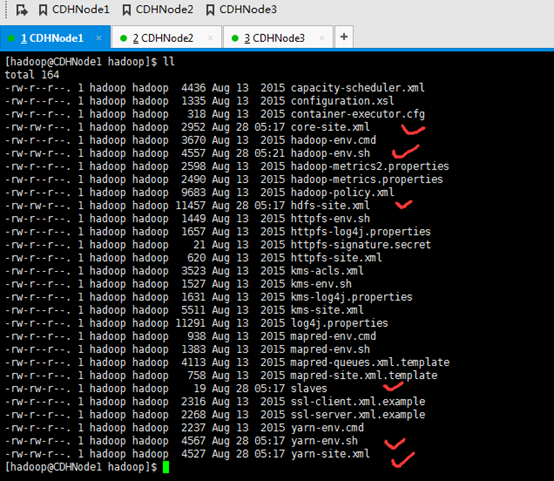
cd hadoop-2.6.0-cdh5.4.5/etc/Hadoop

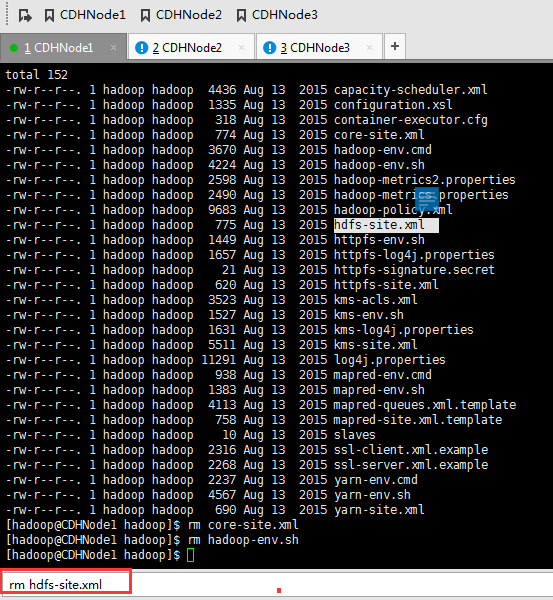
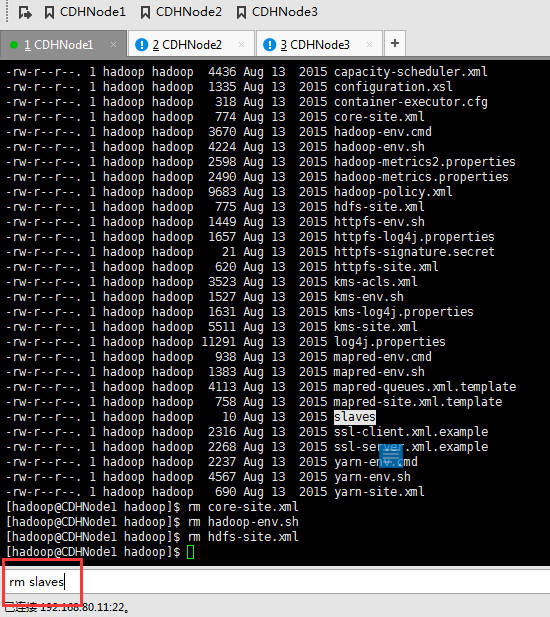
rm core-site.xml
rm hadoop-env.sh
rm hdfs-site.xml
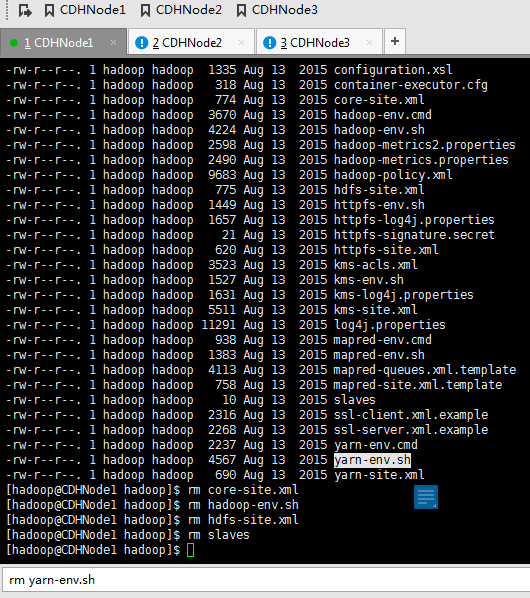
rm slaves
rm yarn-env.sh
rm yarn-site.xml
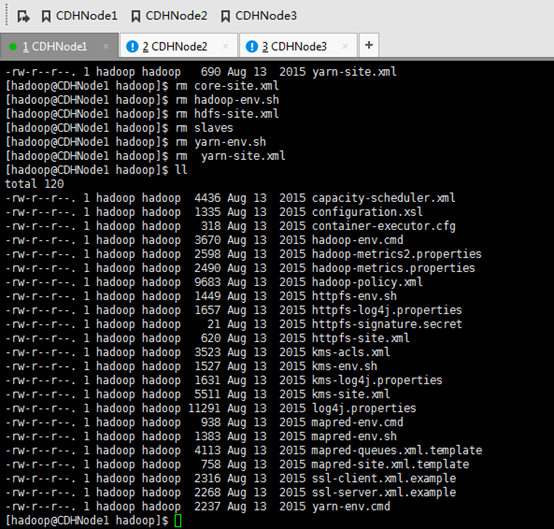
其他两个一样
接下来,将在NotePad++里写好的,直接上传。
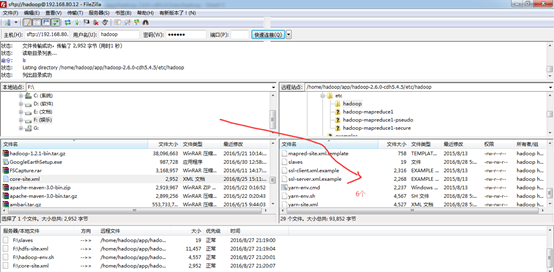
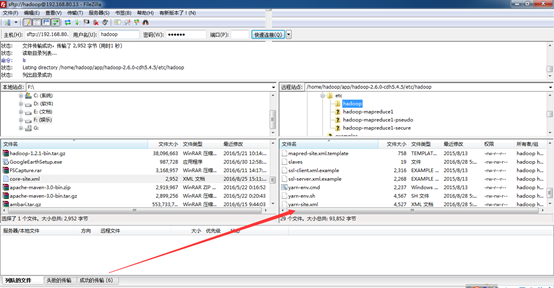
其他两个一样
至此,HDFS核心配置文件的配置完成!
在,
现在,该是创建这个文件的时候了
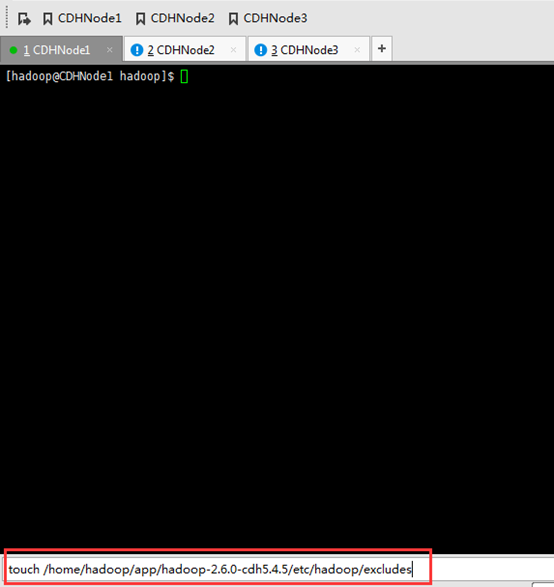
touch /home/hadoop/app/hadoop-2.6.0-cdh5.4.5/etc/hadoop/excludes
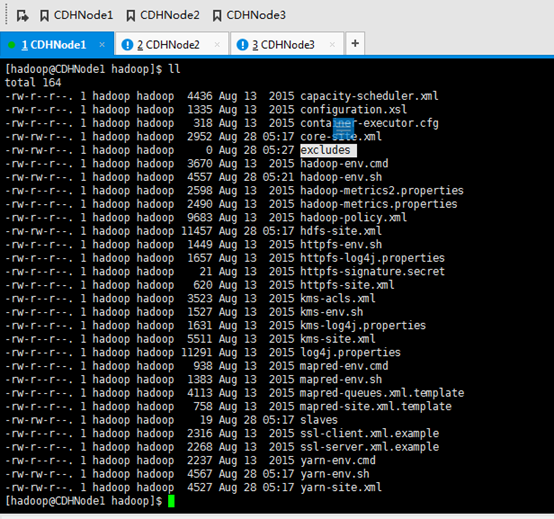
其他两个一样
9、zookeeper-3.4.5-cdh5.4.5.tar.gz的安装、环境变量配置和hadoop-2.6.0-cdh5.4.5的环境变量配置
Zookeeper-3.4.5-cdh5.4.5.tar.gz
注意:hadoop-2.6.0-cdh5.4.5.tar.gz与Zookeeper-3.4.5-cdh5.4.5.tar.gz保持一致。
安装在/home/hadoop/app/下,
CDHNode2和3的一样
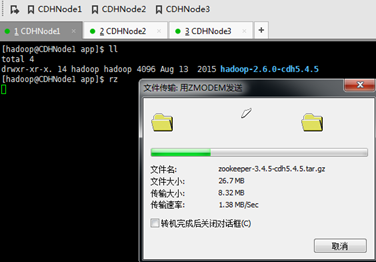
CDHNode2和3的一样

并删除压缩包,
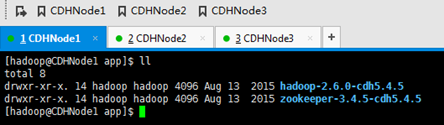
CDHNode2和3的一样


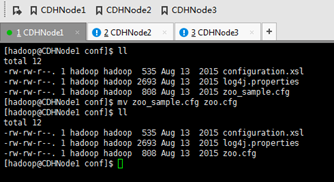
CDHNode2和3的一样
为此,现在需要,对zookeeper-3.4.5-cdh5.4.5/下的zoo.cfg进行,修改配置。

修改地方是
dataDir=/home/hadoop/data/zookeeper
server.1=CDHNode1:2892:3892
server.2=CDHNode2:2892:3892
server.3=CDHNode3:2892:3892
分析:

因为,用到了目录/home/hadoop/data/zookeeper,所以,我们得新建好它。


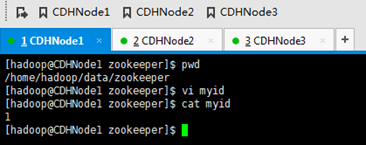
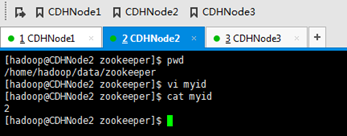
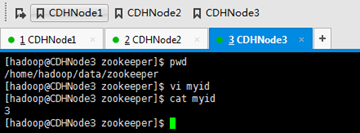
下面,将zookeeper的安装目录放到环境变量里去,以便在任何路径下
这里是~/.bash_profile
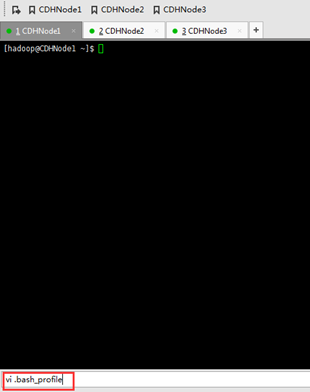

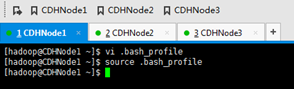
CDHNode2和3,都一样
这里,是,把hadoop-2.6.0-cdh5.4.5的环境变量配置好了,算是补的!
10、初始化hdfs(一次性操作)

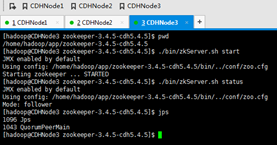
a) 先启动zookeeper,在安装zookeeper的机器上执行./bin/zkServer.sh start
这里安装zookeeper的机器是,CDHNode1、2和3。
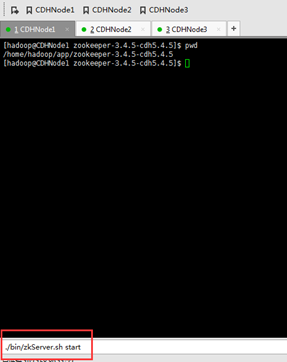
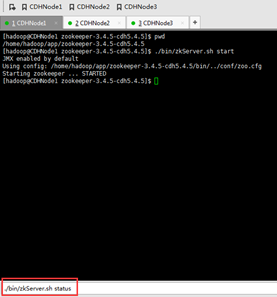
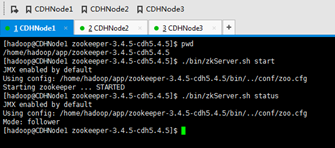
CDHNode1为F,
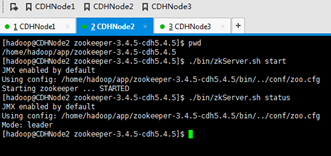
CDHNode2为L,

CDHNode3为F,
总结,初始化一次,就可以了。以后启动,会自带启动。
Zookeeper以后还是要自己启动。
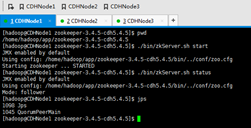
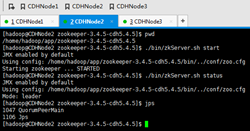
b) 在hadoop-2.6.0-cdh5.4.5启动journalnode(所有journalnode节点都得起)
./sbin/hadoop-daemon.sh start journalnode
这里,CDHNode1、2和3都要做。

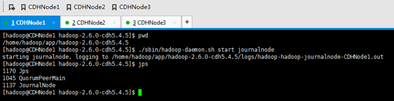
CDHNode2和3一样
c) 主节点(CDHNode1)的hadoop-2.6.0-cdh5.4.5执行
./bin/hdfs namenode -format
./bin/hdfs zkfc -formatZK
./bin/hdfs namenode

接着,会出现下面问题
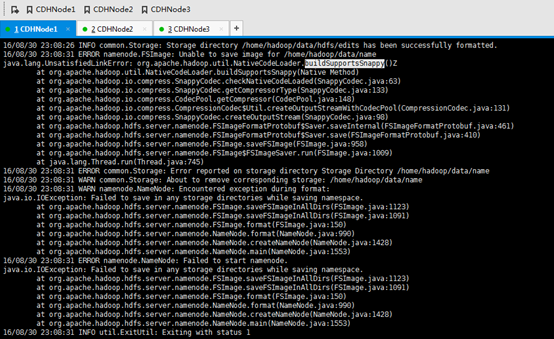
buildSupportsSnappy()Z问题,解决链接:
知识点,CDH默认是没有提供native库的,需要我们自己去编译。
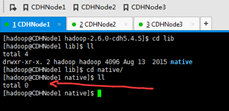
提供的是32位,我们需要的是64位。编译过程很复杂,
这里如何去编译呢?这里是个知识点,我就在网上,找个别人已经编译好了的64位。具体见链接: http://download.csdn.net/detail/tongyuehong/8524619
编译好之后的native放到/home/hadoop/app/hadoop-2.6.0-cdh5.4.5/lib/
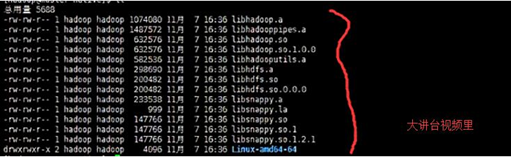

所以呀,看到了,最好还是自己要掌握!!!加油
通过hadoop-2.6.0-cdh5.4.5.src.tar.gz来编译,安装snappy并生成hadoop native本地库。
(大牛的教导:特地开设一个节点,专门来玩玩如apache、cdh这样的hadoop源代码编译,来提升自己的横向能力!并写于博客。)
去吧,开启一个新的节点,新的起点。
快照恢复
CDHNode2、3一样。
先去制作native库吧!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号