ElasticSearch 学习记录之集群分片内部原理
ElasticSearch 系列文章
1 ES 入门之一 安装ElasticSearcha
2 ES 记录之如何创建一个索引映射
3 ElasticSearch 学习记录之Text keyword 两种基本类型区别
4 ES 入门记录之 match和term查询的区别
5 ElasticSearch 学习记录之ES几种常见的聚合操作
6 ElasticSearch 学习记录之父子结构的查询
7 ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
8 ElasticSearch 学习记录之ES高亮搜索
9 ElasticSearch 学习记录之ES短语匹配基本用法
10 ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
11 ElasticSearch 学习记录之集群分片内部原理
12 ElasticSearch 学习记录之ES如何操作Lucene段
13 ElasticSearch 学习记录之如任何设计可扩容的索引结构
14 ElasticSearch之 控制相关度原理讲解
分片内部原理
-
分片是如何工作的
- 为什么ES搜索是近实时性的
- 为什么CRUD 操作也是实时性
- ES 是怎么保证更新被持久化时断电也不丢失数据
- 为什么删除文档不会立即释放空间
- refresh, flush, 和 optimize API 作用
-
使文本可被搜索
倒排索引的结构词项 文档列表
Term | Doc 1 | Doc 2 | Doc 3 | ...brown | X | | X | ...
fox | X | X | X | ...
quick | X | X | | ...
the | X | | X | ... -
倒排索引的不变性
- 不需要锁
- 可被内核的文件系统缓存,停留在内存中,大部分请求会直接请求到内存,不会落到磁盘上
- filter缓存,在索引的生命周期始终有效。不需要再每次数据改变时重建
- 写入单个较大的倒排索引使允许数据被压缩
-
如何在索引不变情况下 动态更新索引
-
使用更多的索引,来解决这个问题
-
通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引
-
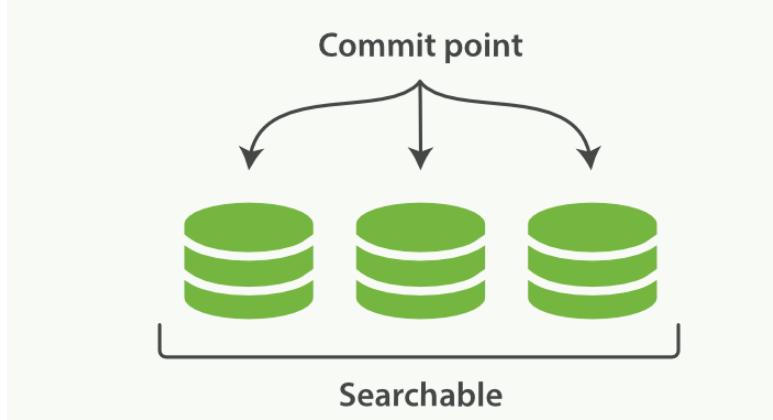
一个 Lucene 索引包含一个提交点和三个段
![]()
-
逐段搜索的流程
- 新文档被收集到内存索引缓存
- 不时地, 缓存被 提交
- 一个新的段----一个追加的倒排索引--被写入磁盘
- 一个新的包含新段名字的 提交点 被写入磁盘
- 磁盘进行 同步 — 所有在文件系统缓存中等待的写入都刷新到磁盘
- 新的段被开启,让它包含的文档可见以被搜索
- 内存缓存被清空,等待接收新的文档
-
一个在内存缓存中包含新文档的 Lucene 索引
-
![]()
-
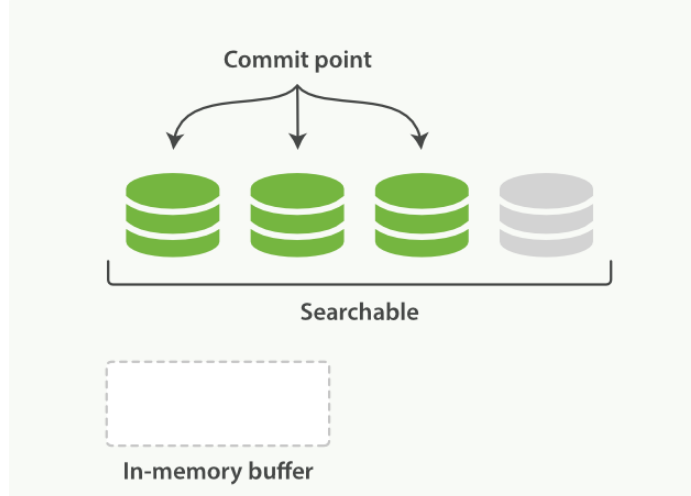
在一次提交后,一个新的段被添加到提交点而且缓存被清空
-
![]()
-
-
删除和更新文档
- 段是不可改变的,每个提交点都会有一个.del文件。在这个文件中能列出这些删除文档的短信息
- 当文档被删除时不是删除,只是在.del文件中被登记
- 文档的更新也是这样的,先将更新的文档标记为删除。然后文档的新版本被索引到一个新的段中

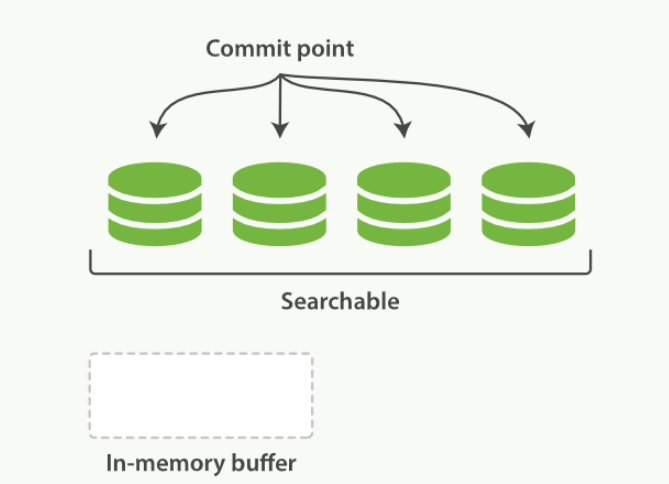
近实时搜索
-
提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是每次提交的一个新的段都fsync 这样操作代价过大。可以使用下面这种更轻量的方式
-
在内存缓冲区中包含了新文档的 Lucene 索引
-
![]()
-
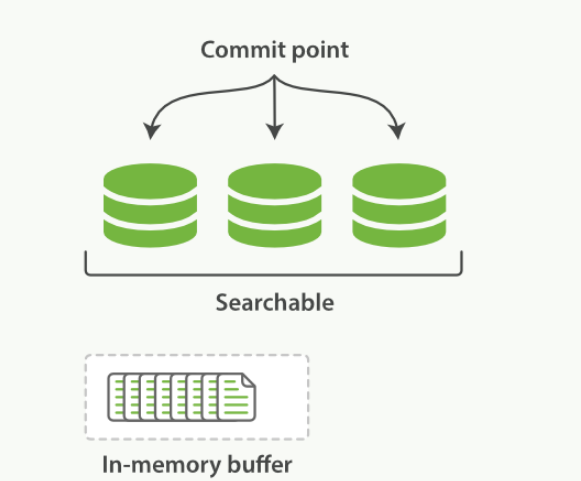
Lucene 允许新段被写入和打开--使其包含的文档在未进行一次完整提交时便对搜索可见
-
-
缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交
-
![]()
-
这里新段会被先写入到文件系统缓存--这一步代价会比较低,稍后再被刷新到磁盘--这一步代价比较高
-
-
默认情况下每个分片会每秒自动刷新一次
- 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见
- POST /_refresh // 刷新Refresh 所有的索引
- POST /blogs/_refresh // 只刷新Refresh blogs 索引
可以在settings 设置对定时刷新频率的大小
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" //30秒刷新一次
"refresh_interval": "-1" //关闭自动刷新
"refresh_interval": "1s"//每秒自动刷新
}
}
持久化变更
在没有 fsync 把数据从内存刷新到硬盘中,我们不能保证数据在断电或程序退出时之后依然存在
- 即时每秒刷新,也不能实现近实时搜索。我们任然有另外的方法确保从失败中回复数据
- ES 增加一个translog,或者叫做事务日志。在每次操作是均进行日志记录
- 整个流程是如下的操作
-
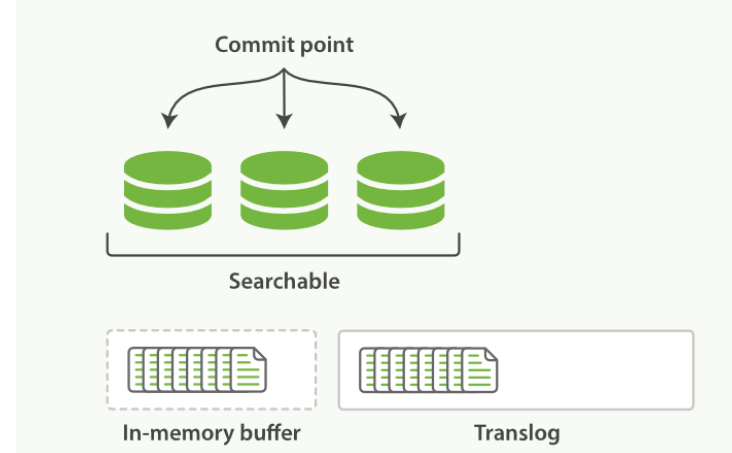
一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
-![]()
-
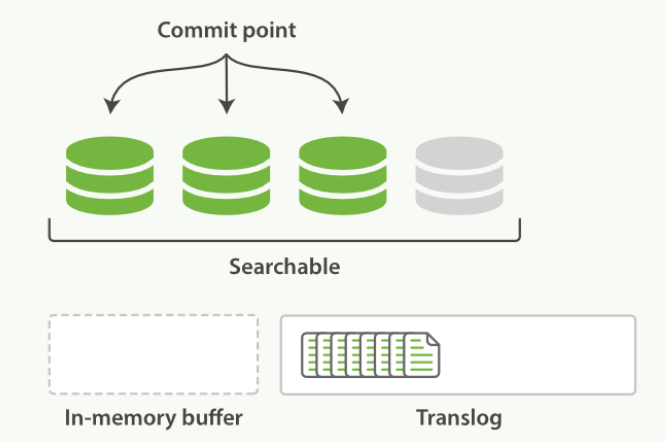
刷新(refresh)使分片处于缓存被清空,但是事务日志不会的状态
- 内存缓冲区的文档被写入新的段中,但是没有进行fsync
- 段被打开,且可被搜索到
- 内存缓冲区被清空
![]()
-
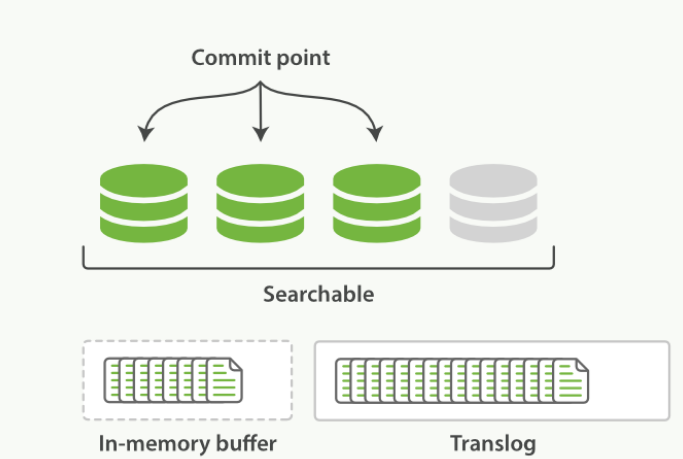
进程继续进行,更多的文档被添加到内存缓冲区和追加的事务日志中
-
每隔一段时间,translog太大 或 索引被刷新。一个新的translog被创建,并且被全量提交
-![]()
- 所有内存缓冲区的文档都被写入一个新的段中
- 缓冲区内清空
- 一个提交点被写入硬盘
- 文件系统缓存通过fsync被刷新
- 老的translog 被删除
-
- translog 提供所有没有被刷新到磁盘操作的一个持久化记录。当ES启动时,会根据最后一个提交点去恢复已知的段
- translog 也可供用来提供实时的CRUD。但我们进行一些CRUD操作时,它会首先检查translog任何最近的变更。
- flush API ** 执行一次提交,并截断translog**的操作
-
分片默认每30M自动flush一次。translog太大也会自动flush
-
可通过自己执行flush API操作
POST /blogs/_flush //刷新索引
POST /_flush?wait_for_ongoing //刷新索引并等待所有的刷新结果返回
-

段合并
-
段合并的时候会将那些旧的已删除的文档从文件系统中删除,被删除或者被更新的文档不会被复制到新的大段中
-
段合并的流程
-![]()
- 当索引的时候,刷新(refresh)操作会创建新的段
- 合并的时候会选择一部分大小相似的段,并且将其合并到更大的段中
- 段的合并结束,老的段就要被删除
![Alt text]()
-
optimized API 的作用
- optimize API大可看做是 强制合并 API 。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号