

scrapy爬虫具体案例步骤详细分析
scrapy爬虫具体案例详细分析
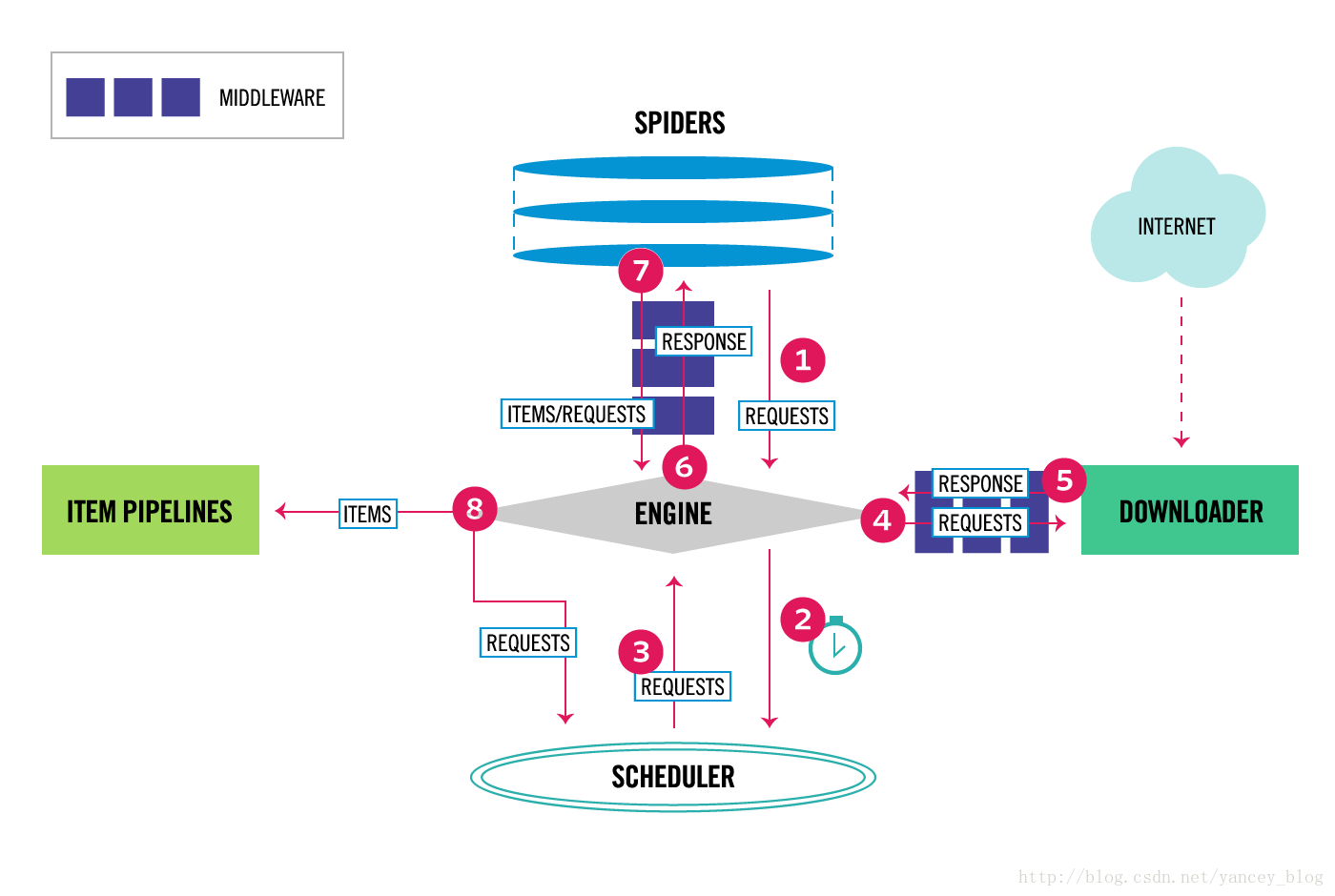
scrapy,它是一个整合了的爬虫框架, 有着非常健全的管理系统. 而且它也是分布式爬虫, 它的管理体系非常复杂. 但是特别高效.用途广泛,主要用于数据挖掘、检测以及自动化测试。
本项目实现功能:模拟登录、分页爬取、持久化至指定数据源、定时顺序执行多个spider
一、安装
首先需要有环境,本案例使用
python 2.7,macOS 10.12,mysql 5.7.19
下载scrapy
pip install scrapy
下载Twisted
pip install Twisted
下载MySQLdb
pip install MySQLdb
二、构建项目
创建项目
*****@localhost:~$ scrapy startproject scrapy_school_insurance
在对应的目录下面就会生成如下目录格式
scrapy_school_insurance/
spiders/
_init_.py
_init_.py
items.py ---- 实体(存储数据信息)
middlewares.py ---- 中间件(初级开发无需关心)
pipelines.py ---- 处理实体,页面被解析后的数据会发送到此(持久化、验证实体有效性,去重)
setting.py ---- 设置文件
scrapy.cfg ---- configuration file
在spiders下创建school_insurance_spider.py 编写具体爬取页面信息的代码
三、spider
首先,要做的是定义items,也就是你需要的数据项,数据存储的地方。
定义Item非常简单,只需要继承scrapy.Item类,并将所有字段都定义为scrapy.Field类型即可。
Field对象用来对每个字段指定元数据。
定义子项目的items.py
# -*- coding: utf-8 -*—
import scrapy
class ScrapySchoolInsuranceItem(scrapy.Item):
# 班级名称
classroom = scrapy.Field()
# 学生身份证
id_card = scrapy.Field()
# 学生姓名
student_name = scrapy.Field()
# 家长姓名
parent_name = scrapy.Field()
# 练习电话
phone = scrapy.Field()
# 是否缴费
is_pay = scrapy.Field()
# 学校名称
school_id = scrapy.Field()
下面进行网络爬取步骤:
school_insurance_spider.py 文件
此类需要继承scrapy.Spider类
先分析一下基本结构和工作流程:
import scrapy
class SchoolInsuranceSpider(scrapy.Spider):
name = "school_insurance"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
pass
这是spider最基本的结构:
name:是你爬虫的名字,后面启动爬虫的时候使用就是这个参数。
start_requests():是初始请求,爬虫引擎会自动调取。
urls:是你定义需要爬取的url,可以是一个也可以是多个。
parse():函数主要进行网页分析,爬取数据。当你的返回没有指定回调函数的时候,默认回调parse()函数;
先来分析一下在迭代器中的这句话:
yield scrapy.Request(url=url, callback=self.parse)
yield 是一个python关键字,代表这个函数返回的是个生成器。
理解yield,你必须理解:当你仅仅调用这个函数的时候,函数内部的代码并不立马执行,这个函数只是返回一个生成器对象。只有当你进行迭代此对象的时候才会真正的执行其中的代码,并且以后的迭代会从在函数内部定义的那个循环的下一次,再返回那个值,直到没有可以返回的。
这里的start_requests函数就会被当做一个生成器使用,而scrapy引擎可以被看作是迭代器。scrapy会逐一获取start_requests方法中生成的结果,并判断该结果是一个什么样的类型。当返回Request时会被加入到调度队列中,当返回items时候会被pipelines调用。很显然,此时迭代返回的是request对象。
引擎会将此请求发送到下载中间件,通过下载中间件下载网络数据。一旦下载器完成页面下载,将下载结果返回给爬虫引擎。引擎将下载器的响应(response对象)通过中间件返回给爬虫。此时request()使用了回调函数parse(),则response作为第一参数传入,进行数据被提取操作。
当你直接使用scrapy.Request()方法时默认是get请求。
而此项目是要爬取一个需要登录的网站,第一步要做的是模拟登录,需要post提交form表单。所以就要使用scrapy.FormRequest.from_response()方法:
def start_requests(self):
start_url = 'http://jnjybx.jnjy.net.cn/admin/login.aspx?doType=loginout'
return [
Request(start_url, callback=self.login)
]
# 模拟用户登录
def login(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': ‘***’, 'password': ‘***’},
meta={'school_id': ***},
callback=self.check_login
)
访问网址后我们直接回调login方法,进行表单提交请求。表单结构需根据不同网站自己分析,此网站只需提交username和password,如果你需要传递自定义参数,可通过meta属性进行定义传递,回调函数中使用response.meta['school_id']就可以获取传递的参数了。一般网站登录成功之后会直接返回,登录后的页面的response,就可以直接回调数据爬取的方法进行爬取了。
但此网站会单独返回一段json来告诉我是否登录成功,并且并不提供下一步的url,所以我这里多了一步check_login()方法,并在判断登录成功后的代码段里重新请求了登录成功后的url。(scrapy是默认保留cookie的!)
模拟登录完整代码:
# -*- coding: utf-8 -*-
import scrapy
import json
import logging
from scrapy.http import Request
from scrapy_school_insurance.items import ScrapySchoolInsuranceItem
class SchoolInsuranceSpider(scrapy.Spider):
name = "school_insurance"
allowed_domains = ['jnjy.net.cn']
# 在这里定义了登录成功后的url,供再次请求使用
target_url = 'http://jnjybx.jnjy.net.cn/admin/index.aspx'
def __init__(self, account, **kwargs):
super(SchoolInsuranceSpider, self).__init__(**kwargs)
self.account = account
def start_requests(self):
start_url = 'http://jnjybx.jnjy.net.cn/admin/login.aspx?doType=loginout'
return [
Request(start_url, callback=self.login)
]
# 模拟用户登录
def login(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': '***', 'password': '***'},
meta={'school_id': ***},
callback=self.check_login
)
# 检查登录是否成功
def check_login(self, response):
self.logger.info(response.body)
body_json = json.loads(response.body)
# 获取参数
school_id = response.meta['school_id']
self.logger.info(school_id)
if "ret" in body_json and body_json["ret"] != 0:
self.logger.error("Login failed")
return
else:
self.logger.info("Login Success")
# 这里重新请求了一次
yield scrapy.Request(self.target_url, meta={'school_id': school_id}, callback=self.find_student_manager)
因为主页并不是我需要的页面,所以find_student_manager()方法作用是找到我需要的那个链接,进行请求后再进行分页爬取。
# 检验登录成功后 跳转 学生管理连接
def find_student_manager(self, response):
self.logger.info(response.url)
school_id = response.meta['school_id']
self.logger.info(school_id)
next_page = response.css('a[href="studentManage.aspx"]::attr(href)').extract_first()
logging.info(next_page)
if next_page is not None:
self.logger.info("next_url:" + next_page)
next_page = response.urljoin(next_page)
self.logger.info("next_url:" + next_page)
yield scrapy.Request(next_page, meta={'school_id': school_id})
else:
self.logger.error("not find href you needed")
解析html是需要选择器的,和编写css时给页面加样式的时候操作类似。
scrapy提供两种选择器xpath(),css();
XPath是用来在XML中选择节点的语言,同时可以用在HTML上面。CSS是HTML文档上面的样式语言。
css选择器语法请参考:https://www.cnblogs.com/ruoniao/p/6875227.html
我这里使用css选择器来获取a标签的herf,分析一下这句话:
next_page=response.css('a[href="studentManage.aspx"]::attr(href)').extract_first()
简单来讲,.css()返回的是一个SelectorList对象,它是内建List的子类,我们并不能直接使用它得到数据。.extract()方法就是使SelectorList ——> List,变为单一化的unicode字符串列表,我们就可以直接使用了。.extract_first()顾名思义,就是取第一个值,也可写为 .extract()[0],需要注意的是list为空的时候会报异常。
再看看这句话:
next_page = response.urljoin(next_page)
通过选择器获取到是一个href的字符串值,是相对url,需要使用.urljoin()方法来构建完整的绝对URL,便于再次请求。
进入需要爬取的页面,开始分页爬取:
# 爬取 需要 的数据
def parse(self, response):
school_id = response.meta['school_id']
counter = 0
# id_cards = response.css('tr[target="ID_CARD"]::attr(rel)')
# i = 0
view_state = response.css('input#__VIEWSTATE::attr(value)').extract_first()
view_state_generator = response.css('input#__VIEWSTATEGENERATOR::attr(value)').extract_first()
page_num = response.css('input[name="pageNum"]::attr(value)').extract_first()
num_per_page = response.css('input[name="numPerPage"]::attr(value)').extract_first()
order_field = response.css('input[name="orderField"]::attr(value)').extract_first()
order_direction = response.css('input[name="orderDirection"]::attr(value)').extract_first()
self.logger.info(page_num)
for sel in response.css('tr[target="ID_CARD"]'):
counter = counter + 1
item = ScrapySchoolInsuranceItem()
item['classroom'] = sel.css('td::text').extract()[0]
item['id_card'] = sel.css('td::text').extract()[1]
item['student_name'] = sel.css('td::text').extract()[2]
item['parent_name'] = sel.css('td::text').extract()[3]
item['phone'] = sel.css('td::text').extract()[4]
item['is_pay'] = sel.css('span::text').extract_first()
item['school_id'] = school_id
yield item
self.logger.info(str(counter)+" "+num_per_page)
if counter == int(num_per_page):
yield scrapy.FormRequest.from_response(
response,
formdata={'__VIEWSTATE': view_state, '__VIEWSTATEGENERATOR': view_state_generator,
'pageNum': str(int(page_num) + 1), 'numPerPage': num_per_page,
'orderField': order_field, 'orderDirection': order_direction},
meta={'school_id': school_id},
callback=self.parse
)
分析页面:
我所需要的数据是的结构,且每页的结构都相同, 其中一小段html:
<tr target="ID_CARD" rel='1301*******0226'>
<td >初中二年级7班(南京市***中学)</td>
<td >130**********226</td>
<td >李**</td>
<td >蒋**</td>
<td >139******61</td>
<td ><span style='color:green'>已支付</span></td>
</tr>
所以只需要使用选择器进行循环爬取付值给item,然后回调自己就可以把所有数据爬取下来了。
看Chrome的请求状态,发现是post请求且有两个陌生的参数。分析页面发现有两个隐藏参数__VIEWSTATE,__VIEWSTATEGENERATOR,且每次请求都会改变。
<input type="hidden" name="__VIEWSTATE" id="__VIEWSTATE" value="***" />
<input type="hidden" name="__VIEWSTATEGENERATOR" id="__VIEWSTATEGENERATOR" value="CCD96271" />
ViewState是ASP.NET中用来保存WEB控件回传时状态值一种机制。__EVENTVALIDATION只是用来验证事件是否从合法的页面发送,只是一个数字签名。
对于我们爬虫而需要做的就是,获取本页面的这两个值,在请求下一页面的时候作为参数进行请求。分页爬取需要不断回调自己进行递归,此时请求并不是get请求,而是url不变的post请求,我这是使用一个计数器counter防止其无限递归下去。
这里你会仔细发现,一开始自定义的school_id也被加入了item中。
前面提到,爬虫引擎会检索返回值,返回items时候会被pipelines调用,pipelines就是处理数据的类。
四、持久化操作
pipelines.py
# -*- coding: utf-8 -*-
import MySQLdb
class ScrapySchoolInsurancePipeline(object):
def process_item(self, item, spider):
db_name = ""
if item["school_id"] == '1002':
db_name = "scrapy_school_insurance"
elif item["school_id"] == '1003':
db_name = "db_mcp_1003"
if db_name != "":
conn = MySQLdb.connect("localhost", "root", "a123", db_name, charset='utf8')
cursor = conn.cursor()
# 使用cursor()方法获取操作游标
# 使用execute方法执行SQL语句
sql = "insert into `insurance_info` " \
"(classroom,id_card,student,parent,phone,is_pay,school_id) " \
"values (%s, %s, %s, %s, %s, %s, %s)" \
"ON DUPLICATE KEY UPDATE is_pay = %s;"
params = (item["classroom"], item["id_card"],
item["student_name"], item["parent_name"],
item["phone"], item["is_pay"], item["school_id"], item["is_pay"])
cursor.execute(sql, params)
、conn.commit()
cursor.close()
conn.close()
process_item()方法,是pipeline默认调用的。因为需要根据school_id进行分库插入并没有进行setting设置,而是使用MySQLdb库动态链接数据库。执行sql操作和java类似。sql使用“ON DUPLICATE KEY UPDATE”去重更新。
此时我们已经完成了三步,定义items,编写spider逻辑,pipeline持久化。
下一步就是如何让程序正确的跑起来。
五、运行
谈运行,首先要说一下本案例setting.py的书写,它设计运行的方方面面。
# -*- coding: utf-8 -*-
BOT_NAME = 'scrapy_school_insurance'
SPIDER_MODULES = ['scrapy_school_insurance.spiders']
NEWSPIDER_MODULE = 'scrapy_school_insurance.spiders'
# 编码格式
FEED_EXPORT_ENCODING = 'utf-8'
# Obey robots.txt rules 不遵循网络规范
ROBOTSTXT_OBEY = False
EXTENSIONS = {
'scrapy.telnet.TelnetConsole': None
}
# 设置log级别
# LOG_LEVEL = 'INFO'
# 本项目带登陆需要开启cookies,一般爬取不需要cookie
COOKIES_ENABLED = True
'scrapy_school_insurance.middlewares.ScrapySchoolInsuranceSpiderMiddleware': 543,
# 开启 后pipelines才生效 后面的数字表示的是pipeline的执行顺序
ITEM_PIPELINES = {
'scrapy_school_insurance.pipelines.ScrapySchoolInsurancePipeline': 300,
}
完成如上操作后,在终端中到达此项目根目录下运行:
scrapy crawl school_insurance
想生成json文件:
scrapy crawl school_insurance -o test.json -t json
现在我有多个账号存在数据库中,想分别登入读取信息该如何操作?
构思了两个方案:
1.读取所有账号,存入一个spider中,每次用一个账号爬取完后退出登录,清除cookie,再拿第二个账号登入,进行爬取工作。
2.动态配置spider,每个账号对应一个spider,进行顺序执行。
仅从描述上看,第二个方案就比第一个方案靠谱,可行。
采用第二个方案,需要动态配置完之后告诉spider要运行了,也就是使用编程的方式运行spider:Scrapy是构建于Twisted异步网络框架基础之上,因此可以启动Twisted reactor并在reactor中启动spider。CrawlerRunner就会为你启动一个Twisted reactor。 需先新建一个run.py:
#!/bin/env python
# -*- coding: utf-8 -*-
import logging
import MySQLdb.cursors
from twisted.internet import reactor
from scrapy.utils.project import get_project_settings
from scrapy.utils.log import configure_logging
from scrapy.crawler import CrawlerRunner
import sys
sys.path.append("../")
from scrapy_school_insurance.spiders.school_insurance_spider import SchoolInsuranceSpider
if __name__ == '__main__':
settings = get_project_settings()
configure_logging(settings)
db_names = ['scrapy_school_insurance', 'db_mcp_1003']
results = list()
for db_name in db_names:
logging.info(db_name)
db = MySQLdb.connect("localhost", "root", "a123", db_name, charset='utf8',
cursorclass=MySQLdb.cursors.DictCursor)
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# 使用execute方法执行SQL语句
cursor.execute("select * from school_account")
# 使用 fetchone() 方法获取一条数据
result = cursor.fetchone()
logging.info(result)
results.append(result)
db.close()
logging.info(results)
runner = CrawlerRunner(settings)
for result in results:
runner.crawl(SchoolInsuranceSpider, account=result)
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
logging.info("all findAll")
需要注意的是数据库
获取账号信息,启动reactor,启动spider
runner = CrawlerRunner(settings)
for result in results:
runner.crawl(SchoolInsuranceSpider, account=result)
这句话在spider时,将账号信息作为参数传递过去了,所以我们的spider需要修改一下接收参数
加入构造器,供内部调用:
def __init__(self, account, **kwargs):
super(SchoolInsuranceSpider, self).__init__(**kwargs)
self.account = account
此时login()可修改为:
def login(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': self.account['username'], 'password': self.account['password']},
meta={'school_id': self.account['school_id']},
callback=self.check_login
)
完成后在终端运行run.py即可:
@localhost:~/project-workspace/scrapy_school_insurancescrapy_school_insurance/$ python run.py
此时会报 not import SchoolInsuranceSpider,但是已经明明import了,因为路径的问题,run.py启动时并找不到它,需在import前加 sys.path.append("../")python才可以通过路径找到它
最后需要做的就是定时启动python脚本:
使用crontab
详细语法参考:https://blog.csdn.net/netdxy/article/details/50562864
主要是两步
crontab -e
添加定时任务,每天3点执行python脚本,wq,ok
* */3 * * * python ~/project-workspace/scrapy_school_insurance/scrapy_school_insurance/run.py
六、梳理
Scrapy架构组件、运行流程,结合实例理解一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号