软件设计之美-软件设计之路
重新温习软件设计之路(1)
如果说学习数据结构和常用算法可以帮助我们写出较为高效的代码,那么学习软件设计相关知识则可以帮助我们写出较为高质量的代码,本文是我学习课程《软件设计之美》的学习总结的第一部分。
1 什么是软件设计?
软件设计,是一门关注长期变化的学问,它不是开发者的入门课。作为初级程序员,往往首选的追求是实现一个具体的功能,不能看到一个软件长期的变化。
设计是为了让软件在长期更容易适应变化。
— Kent Beck
以排序算法为例,快速排序的平均复杂度是 O(nlogn),而插入排序是 O(n^2)。所以,一般我们说快速排序比插入排序有优势。但是,这种优势只有在数据规模达到一定程度之后才能体现出来,否则二者差别其实并不明显。因此,对比这两个排序算法的优劣关键在于数据的规模。
所以,我们可以发现算法和软件设计类似,二者对抗的都是规模问题,算法对抗的是数据的规模,而软件设计对抗的是需求的规模。
换句话说,只有在长期的需求积累前提下,规模问题才会凸显,而(好的)软件设计,正是应对需求规模问题的解决方案。

那么,到底什么是软件设计?
是具体技术实现?是框架和中间件?是设计模式?.......
上面说道,软件设计要关注长期变化,需要应对的是需求规模的膨胀,而上面这些提到的误解则都是不断在变的东西,没有直击问题本质。
软件设计其实是在软件开发过程中,建立起一个统一的结构,便于参与这个过程的所有人都能有一个共同的理解,类似于建筑图纸。
而这个统一的结构,我们可以将其理解为一个模型,它是一个软件的骨架,是一个软件之所以是这个软件的核心。
模型的粒度可大可小,小到可以是一个类(class),也可以大到一个系统(system)。
一般好的模型,都是“高内聚,低耦合”的。
模型可以分层,由底层的模型提供接口,构建出上层的模型。因此我们需要做的,其实是 理解模型、建立模型 和 评判模型的优劣 等等。
但是,仅仅有好的模型对于软件设计要解决的问题还不够,还需要软件设计的另一部分,它就是规范。所谓规范,就是限定了什么样的需求应该以什么样的方式去完成。
规范的作用主要在于,维系软件长期的演化。正如我们在实际项目开发过程中,团队成员基础各异,老成员一个没留神,新成员就可能会创造出一种新的写法,我们的项目就会走向不可控。因此,我们会看到无数的规范,如代码规范、开发规范、数据库规范、DevOps规范等等。但是,如果发现规范不符合软件设计原则,那也得修正规范,使之得以匹配才能不拖累演化。正如每个项目由于其业务的不同,需要不同的架构,也由于其业务处于不同的阶段,需要的架构也不同。规范也一样,它依赖于模型的发展,如果模型发展了,规范阻碍了模型的发展,那也需要对规范进行调整。
模型和规范,二者相辅相成,它们构成了软件设计的主体内容。
换句话说,软件设计=模型+规范。

2 软件设计的第一步:分离关注点
对于稍微大一点的软件设计,我们最常用的方法就是分解大问题为一个个的小问题来各个击破再进行组合。如何分解与组合,是软件设计中需要考虑的重要问题。正如当下十分流行的微服务架构风格,就是分解与组合的典型案例。
在软件设计中的第一步,就是要考虑好分解的粒度,不合适的粒度会为软件日后的演化埋下很多坑。因此,我们常常听说软件设计需要首先“分离关注点”。

图片来源《软件设计之美》
多多关注非功能性需求
对于一个系统来说,它的软件设计不应该只考虑功能性需求,还需要考虑它的非功能性需求。郑晔老师强调道,我们需要主动去发现和挖掘这些非功能性需求。这也让我联想到过往的一些架构设计,它们很多时候都是由很多非功能性如数据一致性要求、响应速度要求、可用性要求等等。
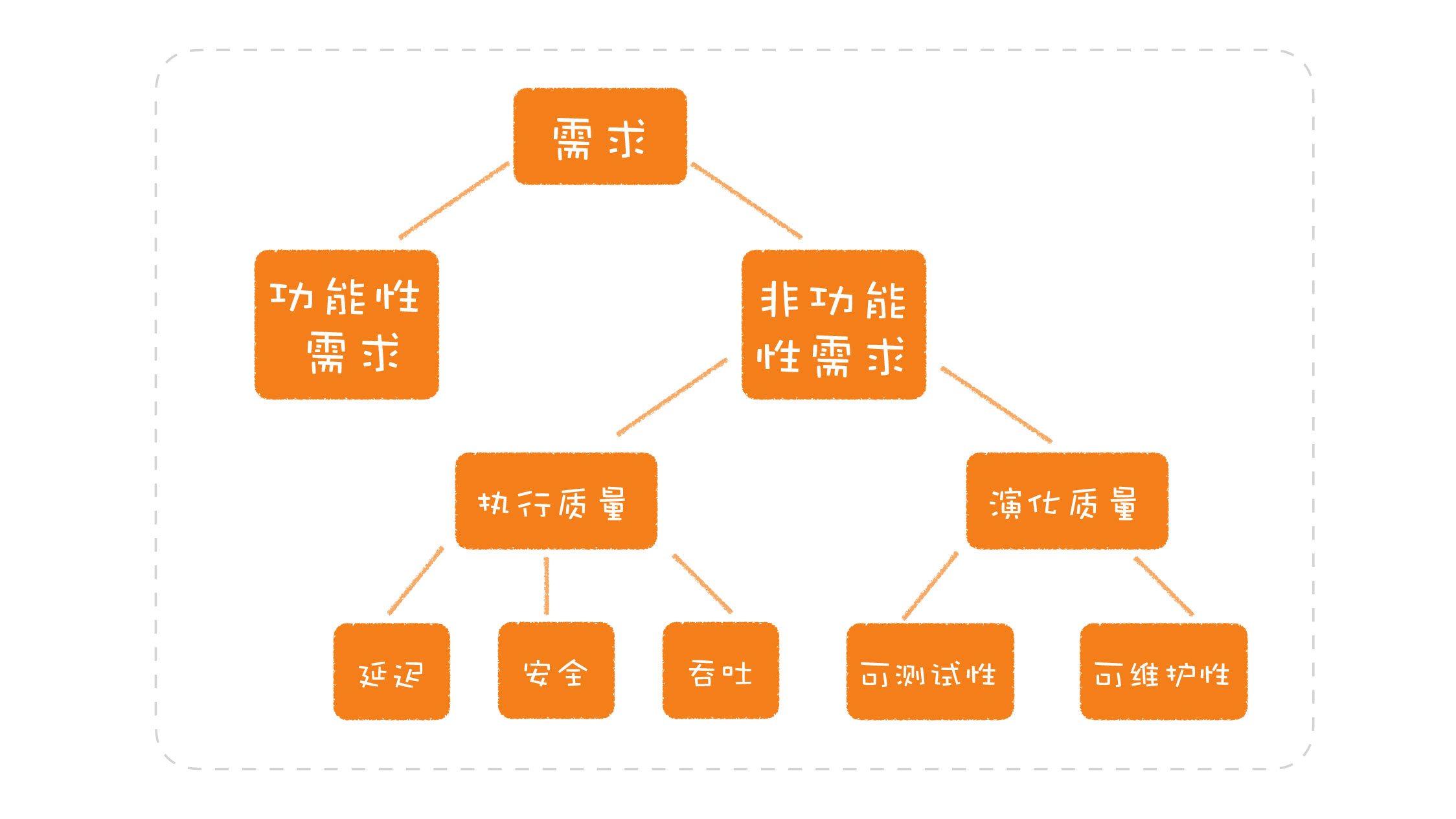
图片来源《软件设计之美》
分离关注点的常见问题
(1)将业务处理和技术实现混淆在一起
在分离关注点的常见问题中,最典型的一个问题就是将业务处理和技术实现两个关注点混淆在一起。
比如,常见的将业务代码和多线程处理放在一起,但是不加以限制地去修改代码会容易引发多线程的相关问题如资源竞争、数据同步等。又如,我们可能会涉及到需要分布式事务、分库分表的场景,但是我们是不是该想想我们的业务真的需要分布式事务吗?是不是业务划分没有做清楚,才造成了DB的压力?很多大佬都说,分布式事务的最好解决方案其实是 能不上分布式事务就不上分布式事务。
我们程序员往往喜欢认为所有的问题都是技术问题,试图用技术问题解决所有问题。但是,郑晔老师强调道,任何试图用技术去解决其关注点的问题,只能是越陷越深。
(2)不同的数据变动方向引起的混淆
在分离关注点的常见问题中,另一个典型问题就是不同的数据变动方向。
比如,在一个.NET应用里边,做数据库访问是用EF好,还是Dapper或者SqlSugar好,又或者直接原生ADO.NET好?对于普通的增删查改,使用ORM如EF这类会快速又省事,但是对于一些复杂场景,我们又会担心自动生成的SQL有性能问题,还是觉得自己手写SQL优化来得直接和实在,感觉挺纠结的。而之所以出现工具选择的困难,很多时候可能都是由于我们将两种使用频率不同的场景混在了一起,比如将前台访问(CRUD)和后台访问(统计报表)混在了一起,如果将其分开,那是不是也就不纠结了?
又如,我们常听说的动静分离,其实就是将变的和不变的内容分开;数据库读写分离,就是将读操作和写操作从数据库层面分开;CQRS,就是将命令和查询操作从代码层面分开。......
因此,不同的数据变动方向,就是一起可以分离的关注点。
分离关注点的目的
分离关注点,一来可以避免后续演化过程可能会发生的许多相关问题,二来可以帮助我们发现不同模块间的共性,更好地进行设计。
因此,我们在软件设计的第一步,就是要发现和分离关注点,发现的关注点越多越好,粒度越小越好。
3 被忽略的重要因素:可测试性
分离关注点是软件设计的第一步,它常被我们所忽略。此外,还有另一个常被人忽略的因素:可测试性。我们可以看到,可测试性,其实是属于非功能型需求中的一个需求点,但是这个点往往不被我们所重视,因而常常被忽略。
图片来源《软件设计之美》
郑晔老师说道,我们在开发过程中欠下的许多技术债,从本质上来说都是因为忽略了“可测试性”这个需求。因为,我们将软件拆分后,它们就是一个一个的小模块,如果不仅可能保证每一个小模块的正确性,是很难从最外围的整体系统的角度去验证正确性的。我们都知道,Bug Fix的成本在软件开发过程中是逐步升高的,如果能在前面尽可能的发现更多的Bug,所花费的成本是要比在线上排查修复低很多的。因此,尽早暴露问题而不要总是等到集成测试才暴露其实早已是我们的共识,而可测试性就是利于我们尽早暴露问题的解决方案之一。
那么,如何考虑可测试性,简而言之,就是我们在设计的时候问一下自己,这个 方法/模块/系统 怎么测试?将每一个小模块做了足够的测试,就会有足够稳定的模块,进而才有高效的集成测试。
举个例子,我们在开发.NET应用程序时一般都会借助依赖注入和接口设计来将外部依赖项进行隔离,再使用一些Mock框架(如Moq、NSub等)对这些外部依赖项进行模拟,然后根据这些模拟对象来进行单元测试的编写。又或者针对数据访问层的单元测试,我们也往往会使用Mock框架将DB用内存来模拟,我们要做的就只是保证模拟出来的内存模拟实现 和 接口定义的行为保持一致即可。
下面是一段常见的不具有和具有可测试性的.NET代码:
(1)服务层调用数据库访问层的代码,不考虑可测试性

public class ProductService
{
private DBProductRepository repository = new DBProductRepository();
public Product GetProduct(long id)
{
return repository.GetProduct(id);
}
}
(2)服务层调用数据库访问层的代码,考虑了可测试性
public class ProductService
{
private readonly IProductRepository _repository;
public ProductService(IProductRepository repository)
{
_repository = repository;
}
public Product GetProduct(long id)
{
return _repository.GetProduct(id);
}
}
在实际项目中,我们也往往会碰到一些遗留系统的维护,这些系统的设计往往没有考虑可测试性,因此很难做单元测试。这时,我们可以采用一些强力的Mock框架,比如JustMock(要收License费用),它可以帮助我们模拟如静态函数、.NET基本函数库、日期对象等开源Mock框架如Moq等所无法模拟的对象,进而帮助提高模块的可测试性。当然,使用强力的Mock框架只是术,还是需要在设计时就考虑可测试性才是道。
关于在.NET应用中编写单元测试,我也有写一个小系列的文章介绍,欢迎阅读。传送门:点击这里。

图片来源:JustMock官网
4 小结
本文我们学习了什么是软件设计,一句话概括,软件设计=好的模型+适合的规范。软件设计的第一步是分离关注点,分离的关注点越多越好,粒度越细越好。在软件设计时不要忘记可测试性,只有将一个个的小模块做了足够的测试,才会有稳定的构造块,便于后续的集成测试。
最后感谢郑晔老师的《软件设计之美》课程,让我获益良多,我也将它推荐给各位园友,值得订阅!
转载自: https://www.cnblogs.com/edisonchou/p/edc_relearn_software_design_part1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号