
GitLab CI/CD
CI/CD
- 持续集成CI(尽快发现错误、减少集成问题,避免复杂问题)
- 合并开发人员正在开发编写的所有代码的一种做法
- 一天内进行多次合并和提交代码
- 从存储库或生产环境中进行构建和自动化测试,以确保没有集成问题并及早发现任何问题
- 持续交付CD(每次更改都可发布,降低每次发布风险,更加频繁交付价值,快速频繁客户反馈)
- 通常可以通过将更改自动推送到发布系统来随时将软件发布到生产环境中
- 持续部署会更进一步,并自动将更改推送到生产中
代码版本管理 - Gitlab
- 代码审查
- 问题跟踪
- 动态订阅
- 易于扩展
- 项目wiki
- 多角色项目管理
- 项目代码在线预览
- CI工具集成
Gitlab内置持续集成
持续集成CI
- 集成团队中每个开发人员提交的代码到代码存储库中
- 开发人员在Merge或者Pull请求中合并拉取新代码
- 在提交或者合并更改到代码存储库之前,会触发构建,测试和新代码验证的管道
- CI可在开发周期的早先发现并减少错误
持续交付CD
- 可通过结构化的部署管道确保将经过CI验证的代码交付给应用程序
- CD可将通过验证的代码更快的部署到应用程序
Gitlab CI/CD工作原理
- 将代码托管到Gitlab
- 在项目根目录创建ci文件 .gitlab-ci.yml,在文件中指定构建、测试和部署脚本
- Gitlab将检测到它并使用名为GItLab Runner的工具运行脚本
- 脚本被分组作业,他们共同组成了一个管道
GitLab 对比Jenkins
1、分支的可配置型
- 使用GitLab CI,新创建的分支无需任何进一步配置即可立即使用CI管道中已定义作业。
- Jenkins 2 基于Gitlab的多分支流水线可以实现,相对配置来说Gitlab更加方便。
2、定时构建
- 使用Jenkins可以立即使用,可以再应执行作业或管道的那一刻已cron语法定义
- GitLab CI没有此功能,只能通过调用WebAPI去调用cronjob触发作业和管道
3、拉取请求支持
- Jenkins没有与源代码管理系统进一步集成,需要管理员自行写代码或者插件实现
- GitLab与其CI平台紧密集成,可以方便查看每个打开和关闭拉动请求的运行和完成管道。
4、权限管理
- 由于GitLab与GitLabCI的深度整合,权限可以统一管理
- 由于Jenkins没有内置的存储库管理器,因此权限无法做合并。
5、存储库交互
- GitLab CI是Git存储库管理器GitLab的固定组件,因此在CI/CD流程和存储库功能之间提供了良好的交互
- Jenkins与存储库管理器是松散耦合的,因此在选择版本控制系统时非常灵活。
6、插件管理
- 扩展Jenkins的本机功能是通过插件完成的,插件的维护、保护和升级成本很高。
- GitLab是开放式的,任何人都可以直接向代码库贡献更改,一旦合并,它将自动测试并维护每个更改。
安装GitLab
https://about.gitlab.com/install/#centos-8
GitLab Runner(最好与GitLab版本一直,避免版本差异化)
介绍:GitLab Runner,go语言编写,类似Jenkins的Agent,执行CI持续集成,构建任务的脚本
特点
- 作业运行控制:同时执行多个作业
- 作业运行环境:(Docker、Shell、K8s执行器)
- 在本地、使用Docker并通过SSH执行作业
- 使用Docker容器在不同的云和容器化管理程序上自动缩放
- 连接到远程的SSH服务器
- 支持Bash、Windows Batch和Windows Powershell
- 允许自定义作业运行环境
- 自动重新加载配置,无需重启
- 易于安装、可作为Linux,MacOS和Windows的服务
GitLab Runner类型与状态
- 类型
- shared共享类型,运行整个平台项目的作业(Gitlab)
- group项目组类型,运行特定Group下的所有项目作业(group)
- specific项目类型,运行指定的项目作业(project)
- 状态
- locked:锁定状态,无法运行项目作业
- paused:暂定状态,暂时不会接受新的作业
.gitlab-ci.yml配置文件示例
before_script:
- echo "before-script"
variables:
- DOMAIN: example.com
stages:
- build
- test
- codescan
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
script:
- echo "123"
- echo "456"
- echo "$DOMAIN"
after_script:
- echo "after script in buildjob"
unittest:
stage: test
script:
- echo "run test"
deploy:
stage: deploy
script:
- echo "hello deploy"
- sleep 2;
codescan:
stage: codescan
script:
- echo "codescan"
- sleep 5;
after_script:
- echo "after-script"
before_script
before_script失败导致整个作业失败,其他作业将不再执行,作业失败不会影响after_script运行。
after_script
在每个作业(包括失败的作业)之后运行的命令
stages
用于定义作业可以使用的阶段,并确实全局且顺序的。
.pre&.post
.pre始终是整个管道的第一个运行阶段,.post始终是整个管道的最后一个运行阶段,顺序无法更改,如果仅包含.pre或.post阶段作业,则不会创建管道。

codescan:
stage: .pre
tags:
- build
only:
- master
script:
- echo "codescan"
stage
如果同意阶段有多个任务,是并行执行的,数量可以通过修改runner配置文件中的concurrent的数量来决定。
tags
用于从允许运行该项目的所有Runner中选择特定的Runner(对应的标签-Tags)
allow_failure允许失败
默认值为false,启用后,如果作业失败,该作业将在用户界面中显示橙色警告,但是pipeline不会被阻塞。
when-控制作业运行
- on_success 前面阶段中的所有作业都成功时才执行作业,默认值。
- on_failure 当前面阶段出现失败时执行
- always 总是执行
- manual 手动执行作业
- delayed 延迟执行作业
when: delayed
start_in: '30'
retry - 重试
当作业失败并配置了retry,将再次处理该作业,直到达到retry关键字指定的次数
# 这里when失败的类型有很多种,具体用到可以再查。
retry:
max: 2
when:
- script_failure
timeout - 超时
作业级别的超时可以超过项目级别超时,但不能超过Runner特定的超时
timeout: 3h 30m
parallel - 并行作业
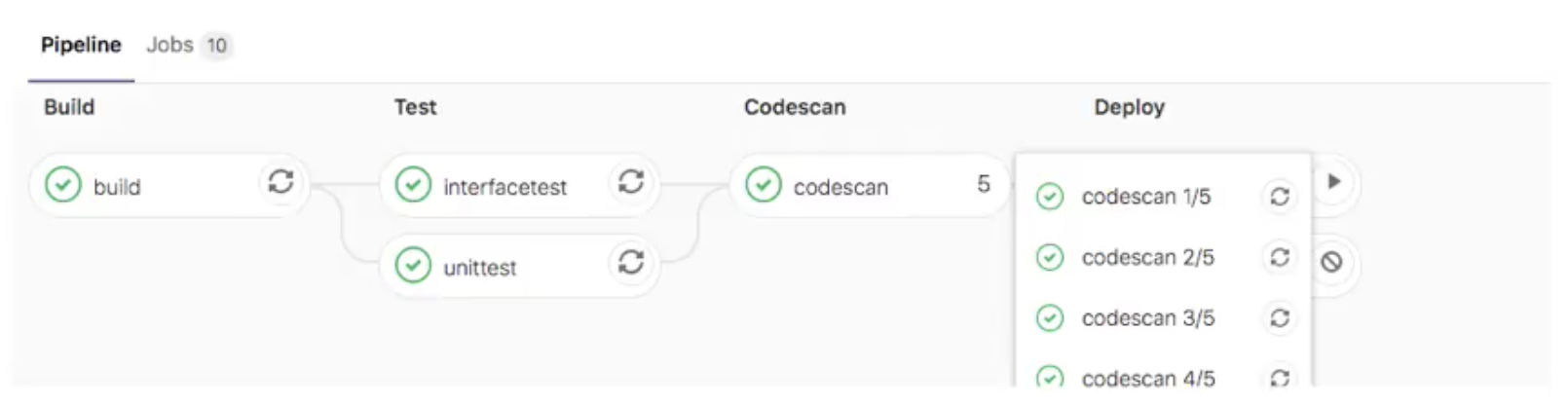
- 配置要并行运行的作业实例数,此值必须>=2并且<=50
- 将创建N个并行运行的同一作业实例,他们从job_name1/N到job_name N/N依次命名
parallel: 5
![]()
only&except(过时了。。后续都建议使用rules)
job:
only:
# 只允许已issue-开头的分支
- /^issue-.*$/
except:
# 排除fff分支
- fff
rules - 构建规则
- rules允许按顺序评估单个规则,知道匹配并为作业动态提供属性
- rules不能与only/except组合使用
可用的规则
- if(如果条件匹配)
- changes (指定文件发生变化)
- exists (指定文件存在)
rules-if-条件匹配
- 如果DOMAIN的值匹配,则需要手动运行
- 不匹配on_success.
- 条件判断从上到下,匹配即停止
- 多条件匹配可以使用&& ||.
variables:
DOMAIN: example.com
codescan:
stage: codescan
tags:
- build
script:
- echo "code scan"
- sleep 5;
rules:
- if: '$DOMAIN == "example.com"'
when: manual
- if: '$DOMAIN == "xxx.com"'
when: delayed
start_in: '5'
- when: on_success
changes
build:
script:
- echo "xxx"
rules:
- changes:
- Dockerfile
when: manual
- when: on_failure
exists
build:
script:
- echo "xxx"
rules:
- exists:
- Dockerfile
when: manual
- when: on_failure
allow_failure
build:
script:
- echo "xxx"
rules:
- if: '$DOMAIN == "xxx.com"'
when: manual
alow_failure: true
workflow,是否创建Pipeline
workflow:
rules:
- if: '$DOMAIN == "example.com"'
when: always
- when: never
cache - 缓存
- 存储编译项目所需的运行时依赖项,指定项目工作空间中需要在job之间缓存的文件或目录
- 全局cache定义在job之外,针对所有job生效,job中cache优先于全局
- 在job build中定义缓存,将会缓存target目录下的所有.jar文件
- 挡在全局定义了cache: paths会被job中覆盖,一下实例将缓存target目录。
- 由于缓存是再job之间共享的,如果不同的job使用不同的路径就出现了缓存覆盖的问题,通过设置不同的cache:key来解决该问题。不同的cache:key会为每个job分配一个独立的cache
######
build:
script: test
cache:
paths:
- target/*.jar
######
cache:
paths:
- my/files
build:
script: echo "hello"
cache:
key: build
# key: ${CI_COMMIT_REF_SLUG} # 按照分支设置缓存
paths:
- target/
######

 浙公网安备 33010602011771号
浙公网安备 33010602011771号