


关系型数据库-三范式
实体:客观存在并可相互区别的事物称之为实体。常用于表示一个人、地方、某样事物或某个事件。
关系:关系表示一个或多个实体之间的联系。
属性:属性为实体提供详细的描述信息。
主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
码:码也被称作是关键字。它可以唯一标识一个实体。
候选码:如果一组属性集能唯一地标识一个关系中的元组而又不含有多余的属性,则称该属性集为该关系的候选码 。(候选码可能不止有一个)
主码:用户选定的那个候选键称为主键。
外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
元组:除含有属性名所在的行之外的其他行称之为元组。
分量:元组的某个属性值。
关系模式:关系名和其属性集合的组合称之为关系模式。如:课程关系表(课程号,课程名,学时)。
关系模型:关系模式组成的集合。
域:关系模型要求元组的每一个分量都是原子性的,也就是说,它必须属于某种元素类型,如Integer、String等等,不能是列,集合,记录,数组。域就代表着该元组中每个分量的类型。
第一范式(1NF)
每一个属性都不可再分。
所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的设计基本要求,一般设计中都必须满足第一范式(1NF)。
在下面这个例子中,电话这个属性分了,故而不属于第一范式(1NF)。

满足第一范式(1NF)应该是

第二范式(2NF)
关系R是1NF,且每个非主属性都完全函数依赖于R的键。
在1NF的基础上,非码属性必须完全依赖于码,在1NF基础上消除非主属性对主码的部分函数依赖。
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。例如在员工表中的身份证号码即可实现每个一员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。在找不到候选键时,可额外增加属性以实现区分,如果在员工关系中,没有对其身份证号进行存储,而姓名可能会在数据库运行的某个时间重复,无法区分出实体时,设计辟如ID等不重复的编号以实现区分,被添加的编号或ID选作主键。(该主键的添加是在ER设计时添加,不是建库时随意添加)。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。
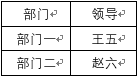
下面这个例子中,员工信息和部门信息。

一个员工属于一个部门,一定属于某个领导,所以有(姓名,部门)—领导,所以(姓名,部门)是一个码,
一个(部门),必定对应一个领导,并不需要依赖姓名,这就是不完全依赖,或者可以说部分依赖,如果员工表离职了,会将部门和领导同时删除。
应该拆分为员工表

和部门领导关系表
第三范式(3NF)
R是2NF,且它的任何非键属性都不传递依赖于任何候选键。
在1NF基础上,任何非主属性不依赖于其它非主属性,在2NF基础上消除传递依赖。
第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性,也就是在满足2NF的基础上,任何非主属性不得传递依赖于主属性。
继续上面的例子,如果一个领导被撤职了,那么他领导的这个部门其实是还在的,那么其实应该还分解出一张部门表。


