性能优化概要(2)数据库时间,监控和优化工具
1.数据库时间
数据库时间,具体来讲优化不仅仅是缩短等待时间 ,而是缩短最终用户的响应时间和(或)尽可能减少每个请求占用的平均资源
有时这些目标可同时实现,而有时则需要进行折衷(例如并行查询) 通常可以认为,优化就是避免以浪费的方式占用或保留资源
对数据库发出的任何请求由两个不同的段组成:
等待时间(数据库等待时间)和服务时间(数据库CPU 时间)
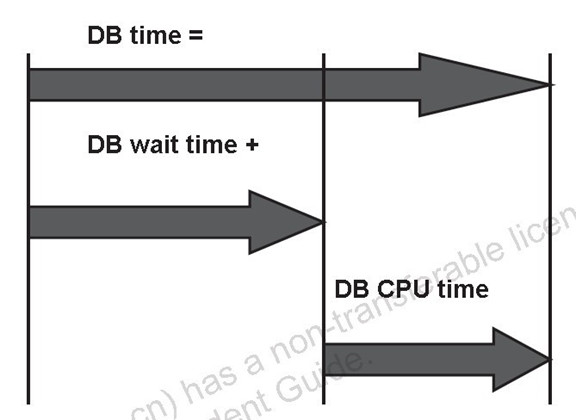
等待时间是各种资源的所有等待时间的总和
CPU 时间是实际处理请求或在OS 队列中等待所用的时间的总和
这些时间不一定由一个等待时间和一个CPU 时间块组成
优化包括缩短或消除等待时间以及缩短CPU 时间 这句话,适用于所有的环境
无论是应用程序类型、还是联机事务处理(OLTP) 或数据仓库(DW)
非常繁忙的系统因为要在运行队列中等待,所以数据库CPU 时间也更长
过载的系统将导致进程在运行队列中等待,从而会增大所有进程的数据库CPU 时间
通过将CPU 时间与等待时间进行比较,可以确定用于有效工作的响应时间,以及用于等待可能由其他进程占用的资源的时间。

通常情况下,等待时间占在系统中占主导地位,可优化的余地就会有很多,而CPU 时间占主导地位的系统需要的优化较少
此外,SQL 语句编写不佳也可能导致高CPU 使用率
虽然随着系统负载的增加,等待时间与CPU 时间的比值会一直增大,但是,等待时间的迅速增加是争用的迹象,必须解决这一问题才能获得良好的可伸缩性
增加的等待时间表明发生争用时,在节点中增加CPU 或在群集中增加节点的作用将非常有限。相反地,CPU 时间的分配比例不会随着负载增大而明显减小的系统,可伸缩性会更好

对于这个等式,我们也可以用这个来看:
系统的响应时间=CPU服务的时间+等待时间
其实系统的响应时间可以理解为上面的数据库时间
Response time = service time + wait time
实例:
厨师烧菜时我们叫service time,他在服务我们,烧的快,菜好吃,说明服务好,客人愿意来
但是,如果厨师炒番茄炒蛋,但是蛋没货了,要等到去菜场把鸡蛋买来,厨师是不是要等待了?
等待时间越长,效率也越低,总的响应时间就长了
那如果等待时间比服务时间长很多,那我们就要优化等待时间,如果服务时间比等待时间长很多,就要先优化服务时间
要减少响应时间,则需要同时减少CPU服务时间和等待时间,显然要减少占时间比例最大的两个组件之一是最正确的,也是最有效的
那我们就需要判断整个数据库系统平均响应时间中服务时间(Service time)和等待时间(Wait time)各占的百分比
假如我是一个厨师,接到菜单,客人需要一碗红烧肉
肉有现存的,那么先得切菜、洗锅,中途还要放盐等,搞好后装盘,端出去
在整个过程中,厨师的炒菜,可以把它看作CPU工作时间(服务时间)
客人确定菜名,传到厨房,然后切菜、洗锅,放盐、装盘、端到客人那里去,这个过程,就是等待时间
等待时间,是相对于cpu的工作而言的
如果厨师是个新手,那么他炒菜可能会很慢。所以在这个阶段会花很长时间,我们需要做的是让厨师的动作快一点
如果传菜的伙计走路也不快,让客人久等了,这个时间,我们调优的重点就不会让到cpu服务时间这里来了而要放到等待时间上去。
先来看下下面的两个图


1.1 Service Time
服务时间代表的是" CPU used by this session",是CPU服务会话所花费的所有时间
实例级查看服务时间
|
Select a.value "Total CPU time" from v$sysstat a where a.name= 'CPU used by this session'; |

单位是100万分之1s, 12365说明库都没有什么负载
会话级查看服务时间
先得从v$statname里查'CPU used by this session'的statistic#号,然后再去查v$sesstat视图
|
desc v$statname; select statistic# from v$statname where name = 'CPU used by this session'; |
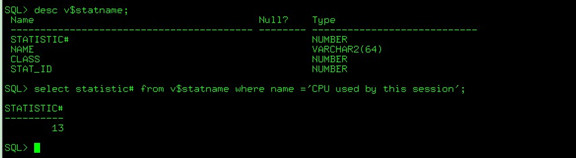
查到的statistic#是13
因为在不同的版本,这个statistic#号可能不同
|
select * from v$sesstat where statistic#=13; |
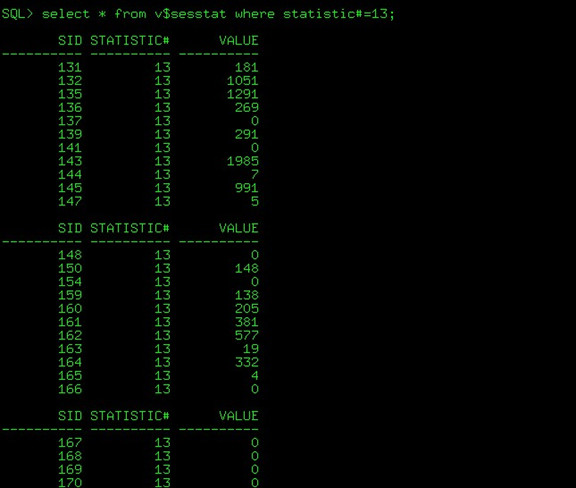
看所有会话的服务时间都查到了,这里再来把服务时间细化一下
Service Time=SQL解析时间+递归调用时间+其它时间
当然某些系统还有OS用户时间和OS系统时间
1.1.1 SQL解析时间
SQL和PLSQL在执行前都要解析 ,解析执行计划,当然包括了硬解析,软解析,软软解析
他们所需要的时间都是不同的,软软解析是性能最好的,也是最节约时间的
SQL/PLSQL等解析时所花的时间,如果解析时间超过总的CPU服务时间20%,那么需要调优应用程序代码
比如绑定变量、SESSION_CURSOR_CACHE等
解析时间也分实例级和会话级 。
1)实例级:
|
select a.value "Total parse Cpu time" from v$sysstat a where a.name = 'parse time cpu'; |

依然会查看实例级动态视图v$sysstat,但是统计名叫parse time cpu,这里注意时间的单位(100万分之1s)
2)会话级:
|
select NAME,statistic# from v$statname where name like '%parse%'; |

统计名仍然是parse time cpu,我这里的统计号是230,然后查询v$sesstat
|
select sid,a.value "Total parse Cpu time" from v$sesstat a where a.statistic# = 344; |

当然,我们也可以只查本会话的统计用到的视图是v$mystat把SID查出来就可以了
1.1.2递归调用时间
递归调用时间是用在语义分析阶段查找数据字典或者PLSQL内部包造成的解析所花的CPU时间。
查找v$sysstat,v$sesstat,我们可以查看到递归调用的时间了
|
select NAME,statistic# from v$statname where name like '%cpu%'; |

|
select a.value "Total recursive Cpu time" from v$sysstat a where a.name ='recursive cpu usage'; |

如果递归CPU时间消耗较多,则需要优化数据字典CACHE
会话级的查询方法同上,这里就不说了
1.1.3其他CPU时间
这个名字取的很怪,但是它却是用的最多的时间,其它CPU时间通常占绝大多数
它是执行内存BUFFER搜索,索引和全表扫描涉及的IO操作所占有的CPU
|
select a.value "Total CPU", b.value "Parse CPU", c.value "Recursive CPU", a.value - b.value - c.value "Other" from v$sysstat a,v$sysstat b,v$sysstat c where a.name = 'CPU used by this session' and b.name = 'parse time cpu' and c.name = 'recursive cpu usage'; |

分析一下这个语句 ,其实是写得复杂单就是从一个视图里查几个不同的值
other=total cpu-parse cpu -recursive cpu
有时候还有负数,可能因为时间计算有点复杂,而且没有负载的环境里,所以很难算出
1.2 等待时间(Wait Time)
光让厨师烧的快也不能解决问题,还得尽量不要让厨师闲下来 ,ORACLE跟资本主义没有区别
资本家,等待常是由于并发,需要等待别的会话处理完独占的资源后所花的时间,这通常也是最常见的性能问题
如果等待时间(wait time)占响应时间(Pesponse time)的大多数时,我们需要减小等待时间来提高系统性能
等待事件分两类
空闲等待事件,非空闲等待事件
1.2.1非空闲等待事件
大部分空闲等待事件都是客户端相关的消息传输事件
|
Col event for a40 Select event,time_waited,average_wait from v$system_event where event not in ('pmon timer', 'smon timer', 'rdbms ipc message', 'parallel dequeue wait', 'virtual circuit', 'SQL*Net message from client', 'client message', 'NULL event') order by time_waited desc; |
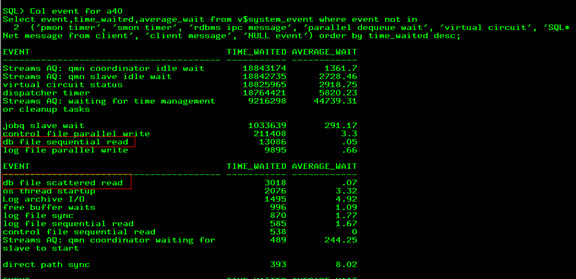
我们看到这个not in里的都是空闲等待事件 所以,这语句是查询所有非空闲等待事件
db file sequential read 连续读的话,一般意思着在读索引
db file scattered read离散读一般意味着是全表扫描
1.2.2空闲等待事件
空闲等待事件我们叫IDEL事件,我们要尽量减少非idel等待时间来提高数据库性能。
减少idel等待时间来提高客户端的性能
如果BS结构,那客户端一般指的都是浏览器(browser)
DB直接连的客户端是应用服务器,是中间层 如Tomcat ,Jboss,weblogic等
所以,如果是大量idle等待事件造成的性能问题,极有可能是应用服务器本身问题,或者网络问题
在调优过程中,我们的重点放在非idle等待事件上
2.监视和优化工具 :概览
2.1 原始数据工具

图中浅色的框表示包含原始数据元的工具
较深的框是已使用原始数据派生出更有用的信息的工具
通常,这些信息使用报表格式,例如活动会话历史记录(ASH) 报表
性能视图是动态性能视图或V$ (v-dollar) 视图的另一个名称,这些视图可展示内存中的原始统计信息
跟踪文件在使用tkprof 实用程序进行格式化之前很难解释
trcsess 实用程序为组合和筛选跟踪文件提供了一种独特的工具,以便提取单个会话、服务或模块的统计信息
"服务"框表示性能监视的指令按服务进行组织
统计信息是按服务汇总的,并可按服务报告多个报表。按服务(而不是按方案、实例或会话)收集的统计信息可以提供独特的应用程序性能视图。

这个图列出的工具可对数据进行格式化,使其成为更有用的信息
其中几种工具可对数据进行分析,从而提供主动的问题检测和建议
这些工具,会在后面讲到一些
对于数据库的优化,大部分是基于被动的、救火式的方式
从10g后,出现主动监控的主动优化方式
先看第一种
当问题出现了,我们就来查问题
2.2 性能优化的三个主要阶段

简单地讲,就是:收集--分析--解决
1)数据收集:
在这个阶段需要确定与诊断性能问题有关的信息,并建立用于定期收集这些信息的基础结构
但是最大的难题是需要能够重放造成所遇问题的工作量,以便对解决方案进行评估
2)数据分析:
此阶段可能是最困难的,因为需要有一位专家来了解并关联所有相关的统计信息
3)解决方案实施:
在这个阶段经常面临的是如何使用多个解决方案解决上一个阶段确定的各种问题
但是需要利用自己的判断,根据影响来确定解决方案的优先级并进行量化
除了以前版本中传统的被动式优化功能(如Statspack、SQL 跟踪文件和性能视图)之外 Oracle Database 10g 还有一些监视数据库的新方法
2.3 10g监控数据库的新方法

简单介绍一下这个图里涉及到这么几个工具:
statspace,ash,alerts,addm,awr,statspack
除了alerts外,其他的都涉及到报表
其中statspack(9I前)报表和awr(9I后)报表的内容有好些是相同的
所有这些组件的数据来源最终是从这里来的 IN-memory statistics中

看自动部分,实际主要是addm,大致是这个样子
addm,是oracle所推荐的,EM中也有

这是oracle指出的
如果没有用addm,那么调优的过程就是左边这些
1. 接到用户的电话,抱怨系统很慢。
2. 检查服务器计算机,看到有充足的可用资源。很明显,速度减慢并不是计算机上的OS 问题导致的。
3. 查看数据库实例,看到许多会话正在等待闩锁释放等待事件。
4. 追溯到闩锁后,看到大多数闩锁释放等待事件是在库高速缓存闩锁和共享池闩锁上。
5. 根据经验并参阅一些有关该主题的书籍,了解到这些闩锁通常与硬分析问题有关。
硬解析,再次检查时,看到已用统计信息分析时间与CPU 分析时间的比值在增大。还观察到已用时间的增加速度要快于CPU 时间。您的怀疑得到确认。
6. 在此阶段,可以通过多种方式继续操作,所有方式均尝试确定偏离的数据分布。
一种方式是查看所有会话的硬解析计数的统计信息,以确定是否存在一个或多个负责大多数硬解析的会话
备选方式是检查共享池,以确定是否存在许多具有相同SQL计划但是包含不同SQL 文本的语句
上面的示例里,采取了后一种方式,并发现存在少量与许多不同SQL 文本关联的计划
7. 复查其中一些SQL 语句时,确定SQL 语句在WHERE 子句中包含文字字符串,所以,必须单独分析每个语句
8. 以前看到过类似的情况,因此现在可以确定,问题的根本原因是未使用绑定变量造成的硬解析,可以继续解决问题。
这就是左边的调优过程示例
右边的话,就两步了:
i. 接到用户的电话,抱怨系统很慢。
ii. 检查最新的ADDM 报表,addm给出了相关建议,第一个建议显示为

通过这些信息,可以立即了解到超过30% 的时间用在了分析上
超过20%就应该关注硬解析

addm提供了解决这种情况的建议操作
请注意,结果中还包含可疑的计划散列值,使您可以快速检查一些示例语句

这个示例的意思很明显,就是addm能找到问题并提出解决问题的建议。
下面简单的介绍下ADDM的方式
1).使用自动数据库诊断监视程序(ADDM) 进行主动式监视:
此组件是Oracle 数据库优化的最终解决方案。ADDM 自动确定Oracle 数据库内部的瓶颈。此外,ADDM 与其他易管理组件配合使用,可推荐消除这些瓶颈的可用选项
自动数据库诊断监视程序这是10g的一个自动化的工具
当然,还有被动式的监视:
- 服务器生成的预警:
Oracle 数据库服务器可以自动检测有问题的情况。检测到问题后,Oracle 数据库服务器会向您发送预警消息,其中包含可能的补救措施
- Oracle 数据库服务器拥有强大的新数据源和性能报告功能。Database Control 提供一个集成的性能管理控制台,该控制台可使用所有相关的数据源。使用追溯方法,只需单击几下鼠标即可人工方式确定瓶颈
包含数据源是为了获取有关数据库运行状况的重要信息,例如内存统计信息(用于当前诊断)以及自动工作量资料档案库(AWR) 中存储的统计信息历史记录
这里,自动工作量资料档案库(AWR) 又出现了
AWR 可以简化性能数据的收集,具有很高的易管理性、自动化程度和数据收集效率,并且对收集的数据量进行认真的分析
AWR 以及自动数据库诊断监视程序(ADDM) 等其他功能是数据库诊断包的一部分
ADDM 通过使用AWR 收集的数据自动诊断性能,从而简化性能的诊断
2).自动数据库诊断监视程序(ADDM) 会在内部执行常规优化会话的步骤

1. 查看ADDM 报表。
A. 收集当前的统计信息;与以前的统计信息集进行比较。
B. 与性能问题知识库进行比较。
C. 定义问题并提供建议。
2. 复查建议。
D. 制定试用解决方案。
3. 实施建议。
E. 实施并度量更改。
4. 复查下一个ADDM 报表。
F. 决定:"该解决方案是否达到目标?"
还有一些软件件包

这些软件包中的功能可以通过Oracle Enterprise Manager
Database Control、Oracle Enterprise Manager Grid Control 和随Oracle 数据库软件提供的API
进行访问
3).Oracle 数据库诊断包提供自动性能诊断功能以及高级系统监视功能。以下是此软件包的部分内容:
- DBMS_WORKLOAD_REPOSITORY 程序包
- DBMS_ADVISOR 程序包,条件是将ADDM 指定为ADVISOR_NAME 参数的值,或为TASK_NAME 参数的值指定任何以ADDM 前缀开头的值
- V$ACTIVE_SESSION_HISTORY 动态性能视图
- 以DBA_HIST_ 前缀开头的所有数据字典视图及其基础表
- 具有DBA_ADVISOR_ 前缀的所有数据字典视图,条件是对这些视图的查询返回在ADVISOR_NAME 列中包含ADDM 值的行,或者在TASK_NAME 列或对应的TASK_ID 中包含ADDM* 值的行
- ORACLE_HOME 目录的/rdbms/admin/ 目录中的下列报表属于此软件包:
awrrpt.sql、awrrpti.sql、addmrtp.sql、addmrpti.sql、awrrpt.sql、awrrpti.sql、addmrpt.sql、addmrpti.sql、ashrpt.sql、ashrpti.sql、awrddrpt.sql 和awrddrpi.sql
这些都是awr的
4).Oracle 优化包为Oracle 数据库环境提供专家级的性能管理,包括SQL 优化和存储优化。Oracle 诊断包是Oracle 优化包的必备产品。因此,要使用优化包,必须同时拥有诊断包
以下是此软件包的部分内容:
- DBMS_SQLTUNE 程序包
- DBMS_ADVISOR 程序包,条件是ADVISOR_NAME 参数的值为SQL Tuning Advisor 或SQL Access Advisor
- ORACLE_HOME 目录的/rdbms/admin/ 目录中的sqltrpt.sql 报表
5). Oracle Configuration 管理包会自动完成耗时并且经常易出错的软件配置过程,软件和硬件库存跟踪、修补、克隆和策略管理等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号