Pandas Learning
Panda Introduction
- Pandas 是基于 NumPy 的一个很方便的库,不论是对数据的读取、处理都非常方便。常用于对csv,json,xml等格式数据的读取和处理。
- Pandas定义了两种自己独有的数据结构,Series 和 DataFrame。
Series
-
Series可以理解为竖着的列表。
(Ps:Series中元素可以是任意类型)index | data
---|---
0 | XiaoWang
1 | XiaoLin -
Series比较常用的定义方式有如下几种
-
传入列表定义Series
s = Series([66,'score','scout','fbricate'])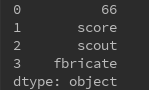
-
传入字典定义Series
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'})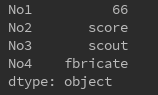
-
-
比较常用的属性和方法
-
S.values 可以显示Series对象的数据值
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'}) print(s.values)
-
S.index 可以显示Series对象的索引
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'}) print(s.index)
-
判断是否为空
- pd.isnull(series对象)
- pd.notnull(series对象)
- Series 对象.isnull()
- Series 对象.index = []
可以重新定义索引的名字s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'}) s.index=['no1','no2','no3','no4'] print(s)
-
-
Series自定义索引机制(索引不仅可以是数字)
-
实际实现:数据值和自定义索引分别对应于两个列表,新索引自动指向于相应旧索引指向的数据值实现“自动对齐”。
-
利用已经生成的Series创建新的Series,并且尝试传入原本不存在的索引
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'}) s1 = Series(s,index= ['No1','No2','No3','No4','No5']) print(s1)
Ps:数据不存在用NaN表示。
-
当旧的索引不在新定义的索引中,则该数据项自动剔除,不进入新的Series中,索引对应可以看成是新的对旧的数据的一种筛选或者添加。
s = Series({'No1':66,'No2':'score','No3':'scout','No4':'fbricate'}) s1 = Series(s,index= ['No1','No2','No4','No5']) print(s1)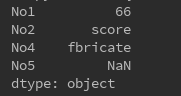
-
-
Series相关运算
-
筛选符合条件的数据,返回一个新的Series
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3}) s1 = s[s > 0] print(s1)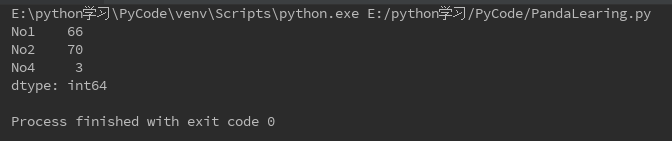
-
对Series进行普通加减乘除以及平方等任何运算都是针对Series里所有数据的
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3}) s1 = s**2 print(s1)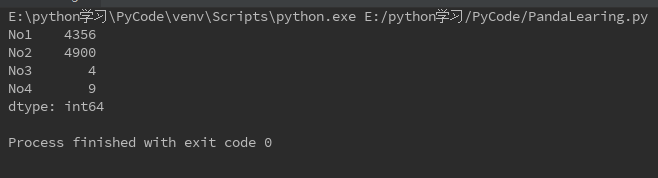
-
用in判断某索引或者数据值是否在Series中
-
判断索引(直接查询对象默认是查询键值)
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3}) print(66 in s) print('No1' in s)
-
判断键值(应在s.values中查找)
s = Series({'No1':66,'No2':70,'No3':-2,'No4':3}) print(66 in s.values)
-
-
两个Series之间的运算(只把具有相同索引的值进行运算,而不是共有的索引都赋值为NaN)
s1 = Series({'No1':66,'No2':70,'No3':-2,'No4':3}) s2 = Series({'No1':4,'No2':0,'No5':-2,'No4':67}) print(s1 + s2)
-
DataFrame
-
DataFrame 是一种二维的数据结构,与电子表格非常像,竖行为columns,横行为index。每一列可以理解为由一个Series构成。如下:
None column0 column1 index0 index1 -
定义方式
-
传入字典定义DataFrame
data = {"name":["Mark","Mike","Michel"],"age":[21,22,23],"favorite":["basketball","game","computer"]} df = DataFrame(data) # df = DataFrame(data,columns=['age','name','favorite']) 可以规定显示键(columns)的顺序 print(df)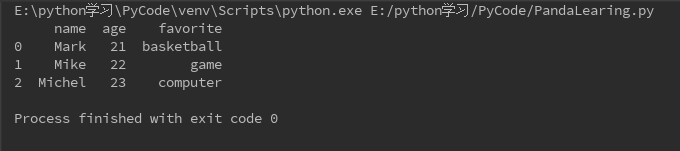
-
自定义索引(默认为0,1,2等整数)
df = DataFrame(data,index=["No1","No2","No3"])
-
-
采用“字典套字典”的方式定义DataFrame
data = {"name":{"No1":"Mark","No2":"Mike","No3":"Michel"},"age":{"No1":21,"No2":22,"No3":23},"favorite":{"No1":"basketball","No2":"game","No3":"computer"}} df = DataFrame(data) print(df)
-
-
属性方法和常用操作
-
DataFrame.columns,能够显示素有的 columns 名称。
print(df.columns)
-
DataFrame.index,获得行索引信息
-
DataFrame.shape,获得df的size
-
DataFrame.shape[0],获得df的行数
-
DataFrame.shape[1],获得df的列数
-
DataFrame.values,获得df中的值
-
得到某竖列(可以理解为一个Series)的全部内容。
print(df['name'])
-
索引某几行
#索引前3行 df[:3] -
可利用loc/iloc/ix索引函数进行索引
-
del df[0] 删除第0列
-
df.drop(0) 删除第0行
-
给某一列统一赋值
# 添加某一新列并且赋初始值: df1['NewColumn'] = 0data = {"name":{"No1":"Mark","No2":"Mike","No3":"Michel"},"age":{"No1":21,"No2":22,"No3":23},"favorite":{"No1":"basketball","No2":"game","No3":"computer"}} df = DataFrame(data) # 新增一行No4,一列 ID 和 Status。 df1 = DataFrame(df,columns=["ID","name","age","favorite","Status"],index=["No1","No2","No3","No4"]) # 为Status统一赋值yes。 df1["Status"]="yes" print(df1)
-
利用Series点对点添加数据(DataFrame每一列是一个Series)
# 创建ID列并且赋值 IDSeries = Series(['001','002','004'],index=["No1","No2","No4"]) df1['ID'] = IDSeriesPs:Series的索引会与DataFrame的索引自动对齐,以此为依据定向添加数据。
-
DataFrame也可以单点精确的修改数据(仿照字典dict操作),比如:
df1['name']['No3'] = 'MICHEL' print(df1)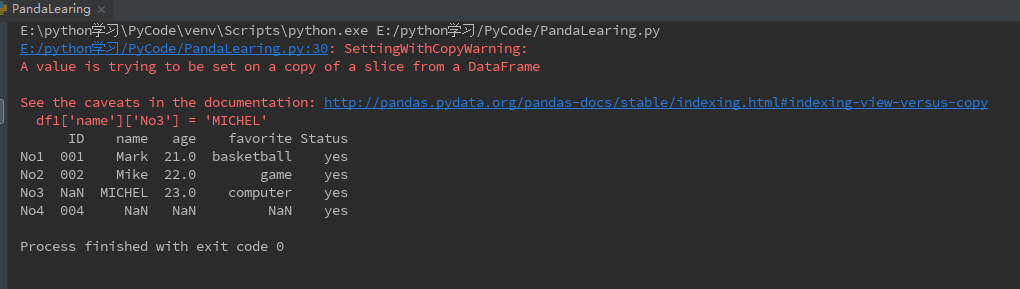
可见数据虽然是成功修改过来了,但是却报了一个SettingWithCopyWarning,其中原因是说“在DataFrame的一个切片上进行赋值操作”,虽然我也不理解在切片上进行数据处理有什么不妥,而且使用给定的索引工具loc创建新的df并进行相同操作也会报如上警告。最后看了网上找了一个比较好的解决方案是:先生成正确的Series再将整个Series插入DataFrame会更加有效。
-
DataFrame选择某些列或者行进行输出,生成新的DataFrame。
# 筛选 name列和age列 df2 = DataFrame(df1,columns=["name","age"]) print(df2) # 筛选No1,No2行 df3 = DataFrame(df1,index=["No1","No2"]) print(df3)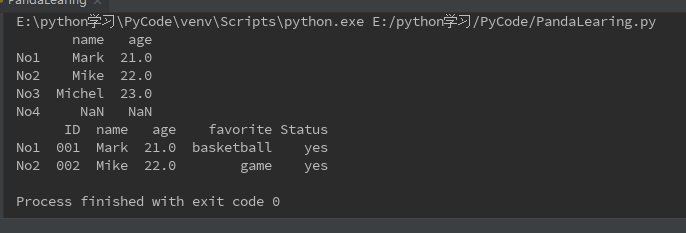
-
根据某列sort排序
# 按照age递减排序 print(data.sort_values(["age"],ascending=False))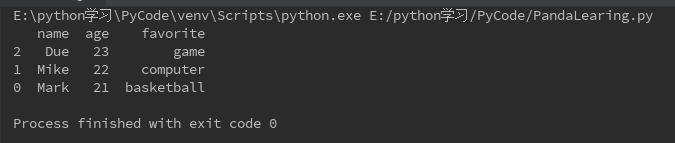
-
map(function)运算 传入一个函数,应用在dataframe的每一个元素上,返回一个dataframe。
-
apply(function,axis)运算 对dataframe的每一列或行进行运算,返回一个Series索引为原先的columns,数据值为函数值(ps:不指定axis对列操作,指定axis=1,对行操作)。
-
Group by操作
-
可以将dataframe导出到csv文件,to_csv方法。
df.to_csv(file_path, encoding='utf-8', index=False) # index为False表示不导出dataframe的index数据
-
Summary
- 这篇博客是根据自己学习pandas库的使用过程中使用过的操作记录下来的,可能不够全面,排序也有点乱,但是后面进一步学习之后会进行补充和修改并且如果文章中有错误希望指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号