[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 实验结果
- 参考文献
(1) 解决问题
现有的基于GAN的方法大多都是先假设服从一个高斯分布,然后再来学习节点嵌入(匹配节点嵌入向量服从这个假设的先验分布)。
这可能存在两个问题:
- 一个问题是(由于真实数据是有很多噪声的,所以会为GAN模型学习的分布带来很多噪声)很难从节点向量表示中区分出噪声节点,因为所有节点都是服从高斯分布的,很容易受到噪声节点的影响?也就是噪声容易影响学习的分布,学习的分布对噪声不稳定?
- 第二个问题是,这种思想没有充分利用GAN的本质优势,作者认为GAN的优势在于其对抗学习的机制而不是学习节点向量表示本身(现有的利用GAN方法来做网络嵌入的方式大多目标是后者,为了学习更好的节点向量)。
所以本文的主要思路就是要在表示机制中融入对抗机制,而不是仅仅为了使得嵌入向量的分布要服从先验分布这个目的。基于以上基本思路,本文提出了一个结合自编码器的对抗学习方法用来实现网络嵌入,把对抗学习用在表示(映射)机制上。
(2) 主要贡献
Contribution:个人感觉这篇论文的主要贡献是把对抗学习这个机制运用在映射机制上而不是运用在表示向量本身,基于这个基本思路,提出了一个结合自编码器的对抗学习方法用来实现网络嵌入,利用对抗训练的机制来进一步优化编码器所学习得到的节点嵌入向量。
(3) 算法原理
模型的主要思路: 下图为论文所提出的AMIL模型的总体框架。AMIL的框架,包括三个部分,如下图所示。一个自编码器,一个负样本生成器和一个互信息判别器,整体是一个对抗过程。整体来说,自编码器部分利用网络拓扑聚合节点属性到节点表示中,解码器使用节点嵌入重构网络拓扑。负样本生成器部分这是一个生成对抗网络,包含一个生成器和属性判别器,是用来生成节点的fake属性向量的。互信息判别器识别编码器的映射机制生成的正样本和负样本生成器生成的负样本。

在AMIL模型中(编码器和生成器都要训练)。编码器部分包含两个目标,一个是传统的自编码器的重构损失,还有一个是互信息判别器的对抗训练目标。也就是说编码器部分根据解码器的反馈(带有结构信息)以及互信息判别器D的反馈(带有属性信息)两部分来更新自己的参数。这个负样本生成器也同样包括两个目标:一个是与自身的属性判别器的对抗目标,还有一个是和互信息判别器D的对抗训练目标。也就是说生成器也根据互信息判别器反馈(带有结构信息或者说负样本生成器只是对节点属性的建模?自己的猜测)和属性判别器(带有属性信息)反馈两个部分来更新自己的参数。以上这个对抗过程不断训练,直到收敛,就可以获得包含结构和属性的节点嵌入向量表示了,理论上可以是编码器的输出也可以是生成器的输出。但是生成器部分毕竟是最小化和真实节点属性向量的差异,可能没有包含拓扑结构的信息,所以感觉取编码器的输出作为最终向量可能会更好。
下面分别介绍以上AMIL框架三个部分的具体细节。
(1) 自编码器:
自编码器的编码器部分论文中采用两层的GCN来搭建,输入邻接矩阵A和属性矩阵X,GCN通过邻接矩阵A反应的图拓扑结构来聚合节点属性从而学习节点表示,每层GCN聚合一跳节点,两层可以聚合两跳节点。解码器部分简单重构网络拓扑,利用编码器得到的嵌入向量内积的sigmoid来重构邻接矩阵,采用交叉熵函数来计算重构损失,具体公式详见原始论文。
(2) 负样本生成器:
负样本生成器部分是一个普通的生成对抗网络(GAN),包含一个生成器和一个判别器。生成器采用三层全连接层的神经网络实现(判别器也是),以一个高斯噪声作为输入,生成节点的fake属性向量,以欺骗判别器。判别器部分目标是去识别真属性和假属性向量。通过迭代训练,生成器生成的节点属性会更加接近真实。GAN具体目标函数详见原始论文。
(3) 互信息判别器:
前面说到模型的核心在于应用对抗学习策略在表示机制上而非表示向量本身,目标是为了学习一个更加有效的嵌入机制。这个核心思路的具体体现就在互信息判别器这一部分。互信息可以表示两个变量之间的依赖关系,越大则两个变量互相依赖(理解为相似?)程度越大。利用这一点,作者使用输入向量和输出向量的互信息来定量表示一个嵌入机制(将输入向量映射到输出向量)的质量,互信息越大表示嵌入质量越好。互信息可以用一些不同的方式定义,但是为了简便和学习效率,作者简单将输入向量和输出向量的拼接定义为互信息的近似。
既然这是一个判别器那么就需要定义正样本和负样本。对于互信息判别器的正样本和负样本定义,我们将编码器生成的节点表示Z和属性信息X的互信息作为正样本(就是编码器的输入和输出嘛)。并且把生成器的输入(噪声高斯分布Z’)和输出(假属性向量X’)的互信息作为负样本。然后互信息判别器的目标就是去区分这对样本了,对正样本输出1,对负样本输出0。互信息判别器的损失详见原始论文。
结合以上三个部分来看AMIL整体框架结构图,其实整个AMIL框架就是一个包含两个竞争对手(指的是映射机制GAN和自编码器)的全局的对抗学习过程,该模型联合训练一个编码器和一个生成器。 AMIL总的目标函数详见原始论文,并且最终使用基于梯度的优化方法来做优化。
(4) 实验结果
- 节点分类
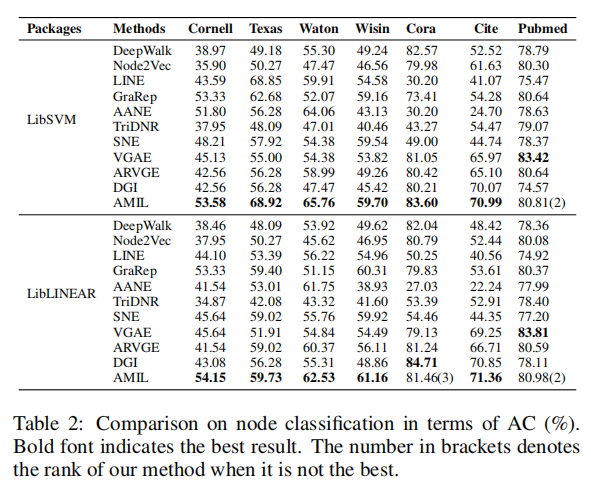
- 节点聚类
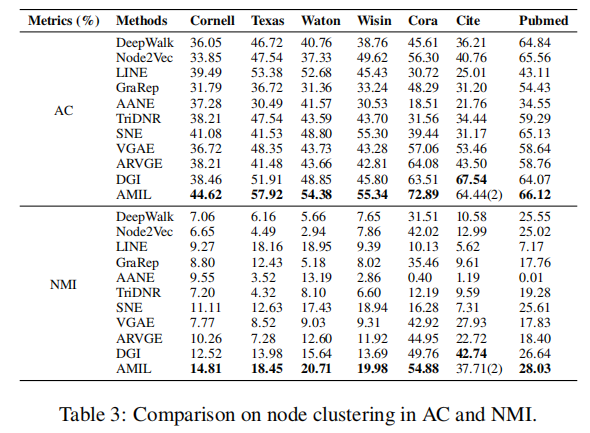
- 参数实验
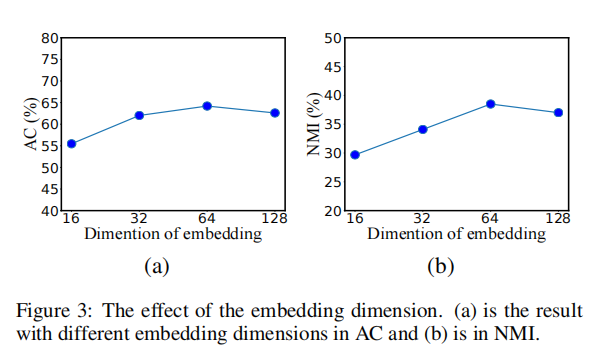
- Citeseer 数据集的可视化结果
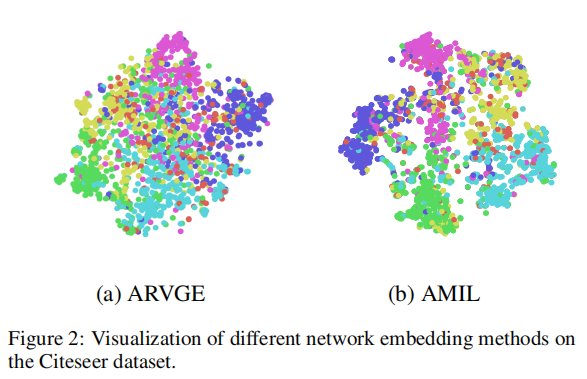
(5) 参考文献
He D, Zhai L, Li Z, et al. Adversarial Mutual Information Learning for Network Embedding[C]//Proceedings of IJCAI. 2020: 3321-3327.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号