[论文阅读笔记] Large-Scale Heterogeneous Feature Embedding
[论文阅读笔记] Large-Scale Heterogeneous Feature Embedding
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
- 综合考虑网络中节点的各种信息来源,从而学习到一个统一的节点表示能够提高下游任务的精度。然而,异构特征信息限制了现有属性网络表征算法的可扩展性。(比如特征的类型、数目和维度非常庞大)
(2) 主要贡献
Contribution 1: 定义了大规模异构特征表征的问题。(异构特征应该指的是不同类型的特征吧)
Contribution 2: 提出一个有效的框架 FeatWalk 来融合节点的高维的并且具有多种类型的特征到节点表示中。
Contribution 3:
设计了一个有效的算法来避免计算节点相似度,并且提供了一个可替代的方式来模拟基于相似度的随机游走来建模节点局部相似度(论文中证明了这种可替代的方式和基于节点属性相似度(向量点积)的随机游走在结果上是等价的)。
(3) 算法原理
FeatWalk可以适用于某个网络有多个网络拓扑图以及多个异构特征矩阵的情况(即可以联合多个异构信息源)。
以下以一个单个网络拓扑和单个特征矩阵举例说明。
FeatWalk算法的主要的框架如下图所示:
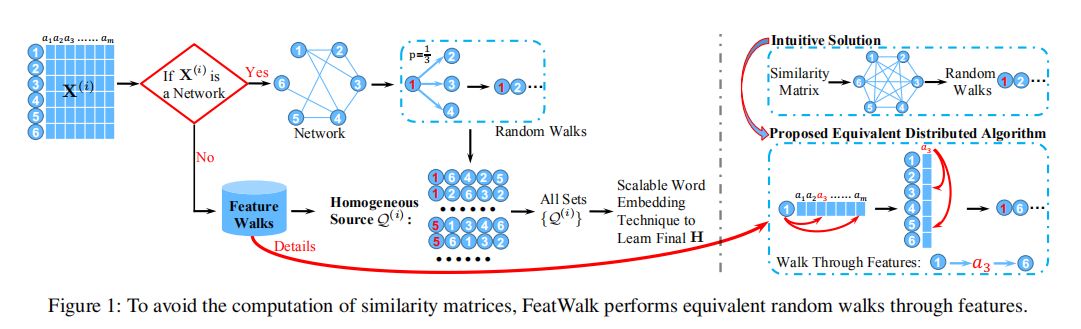
由图中可以看出FeatWalk算法主要包括三个部分:
-
第一步,拓扑结构随机游走采样网络拓扑结构信息: 类似于DeepWalk的随机游走,完全随机,不再赘述。
-
第二步,特征随机游走采样网络特征信息: 传统的基于属性相似度的随机游走,需要计算每个节点对之间的属性相似度来构造属性图,从而在属性图上进行随机游走。然而上述这种直观的方法有几个问题。第一,随着网络规模N的增大,属性相似度矩阵S的大小成指数增长。对S的计算存储和操作的开销会变大。第二,新构造的属性图S是相当稠密的,随机游走在这种图上效果不好且开销很大。因此本论文提出一种不计算属性相似度还能得到与基于属性相似度的随机游走类似结果的基于节点特征的随机游走,而且还适用于具有多种不同类型的特征矩阵。 由上图中可以我们很容易可以总结出特征游走的主要思想:即每次在特征矩阵依概率选择当前节点中具有较大值的属性,并且在该属性对应的属性列中依概率再选择在该属性上具有较大值的节点作为下一跳节点。这就是本文所提出的特征游走。 论文中证明上述设计特征游走的输出等价于基于属性相似度矩阵随机游走的输出(这边不赘述)。此外,论文中还提出了根据节点自身复杂度计算每个节点为始点的游走长度,如下公式所示。
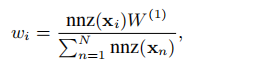
W(1) 是给这个特征矩阵X分配的总的游走次数 (拓扑结构图就以邻接矩阵为特征矩阵)。那怎么分配这个总的预期到每个节点呢。如上述公式所示,如果节点的特征向量中非零元素越多的话,表明这个节点越复杂,需要越多次的游走才能充分捕获其信息。论文设计该公式基于以下两个假设, 第一,节点的特征向量的非零元素越多的话,表明其再属性图中有越多的边,假设为m条,那么至少遍历m次他才能捕获其与所有邻居的关系。第二,网络中具有更多边的节点往往更加重要。为了使得这些节点的局部相似度更好被保留下来,我们为他们采样更多序列。 -
第三步,训练Skip-Gram学习节点表示向量(不再赘述)。
(4) 参考文献
Huang X, Song Q, Yang F, et al. Large-scale heterogeneous feature embedding[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33: 3878-3885.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号