Pytorch_第十篇_我对卷积神经网络(CNN)的理解(包含例子)
我对卷积神经网络(CNN)的理解(包含例子)
Introduce
卷积神经网络(convolutional neural networks),简称CNN。卷积神经网络相比于人工神经网络而言更适合于图像识别、语音识别等任务。本文主要涉及卷积神经网络的概念介绍,首先介绍卷积神经网络相比于人工神经网络的优势,其次介绍卷积神经网络的基本结构,最后我们分别介绍神经网络的各个部件从而完整的了解CNN。
以下均为初学者笔记,若有错误请不吝指出。
Advantages of Convolutional Neural Networks
就拿图像举例来说,一张图像的大小为宽X高X通道数(一般是三色通道)。假设有一组图像的大小为n,那么如果我们用传统的神经网络来处理这张图像的画,输入层需要n个神经元,并且若采用全连接结构的话则会有很多很多的权重参数,这对于网络的训练来说是非常难且耗时的。并且如果图像非常复杂,我们不可能通过不断增加隐层的数量来捕获更加高级的图像特征,因为隐层数过多的神经网络在梯度反向传播的时候可能会出问题,比如之前讲过的梯度爆炸和梯度消失问题。因此传统神经网络比较不适合处理图像任务。反观卷积神经网络,其采用了局部连接、权重共享(即卷积核只与一个窗口进行连接,并且该卷积核可由多个窗口共享)以及池化的设计思路,三个策略的叠加使用大大减少了网络中非常多非常多的不必要的权值参数,使得网络训练变得容易。本文余下篇幅将更加全面的介绍CNN,以帮助读者更加通俗地理解CNN相比传统神经网络所具有的优势。
Basic Structure of Convolution Neural Network
卷积神经网络包含卷积层(Convolution)、非线性激活层(常用ReLU层)、池化层(pooling)、全连接层(Full-Connected)和Softmax层。卷积神经网络的基本结构如下图所示。

文章余下内容将结合具体例子并且按照上述各个部分具体展开介绍。。
举个梨子: 假设我们要识别下述图片(菱形)是菱形呀还是三角形呀,还是正方形长方形呀等等。人眼一看肯定想都不用想就知道是菱形了。那么,计算机要怎么才能知道这个图片是个菱形呢?其实,计算机识别的具体思路是这样子的: 菱形都有什么特征呀,这种图片上有没有满足菱形的几个特征呀?带着这几个问题呀,计算机首先需要学习菱形具有的几个特征(对应CNN的训练过程),其次计算机需要去图上看是不是能找到菱形的特征,如果都满足了,那么就判定这是个菱形(对应CNN的预测过程)。以下从该例子逐步介绍CNN模型各个部件所做的事情。

卷积层(Convolution)
卷积层是在做什么呢?卷积层就是利用携带某特征的卷积核在图上逐步匹配看看是否具有该卷积核携带的特征。 看了上面对于卷积层的描述(个人理解),我们脑子里肯定还会有两个疑问。第一,卷积核又是啥东西,怎么携带图片的特征的?第二,卷积核在图上逐步匹配(就是卷积运算)寻找是否具有该特征,又是怎么匹配的?首先,我们来看第一个问题,卷积核是什么呢? 其实,卷积核就是一个权值矩阵,每个元素为对应的像素值,卷积核可以表示图片中的边缘特征,如正负斜线,竖直线和横直线等等(这些斜线、直线或者曲线等等就是图片最基本的局部特征,更高阶的全局特征(如正方形,长方形等等)捕获可以通过多层卷积实现)。以下分别展示正斜线、负斜线、竖直线以及横直线的3X3卷积核,以帮助我们更近一步理解卷积核的概念。

对于第二个问题,怎么判断图上是否存在如卷积核所描述的特征呢?即怎么判断图上有正斜线、负斜线呢? 其实这是通过在图上移动窗口(窗口大小=卷积核大小),并且每次都将窗口与卷积核进行卷积运算实现的(其实就是两个矩阵对应位置相乘求和再取平均!!!)。这样解释可能有点抽象,我们结合具体例子来看。假设我们要在上述菱形图中寻找正斜线(如上图中3X3的卷积核),那要怎么找呢?首先用3X3的窗口遍历整个图,每次都将对应卷积核与窗口进行卷积运算并将所得值依次按序填入新矩阵中,这个新的矩阵我们称之为特征图(feature map)。特征图用来判断原始图中对应位置与卷积核的匹配程度,越大则表明原始图中的这个位置越可能具有该卷积核所携带的特征。 现在我们通过代表正斜线特征的卷积核与原始图片中第一个窗口进行卷积运算来说明卷积运算的过程,一个简单的卷积示例如下:
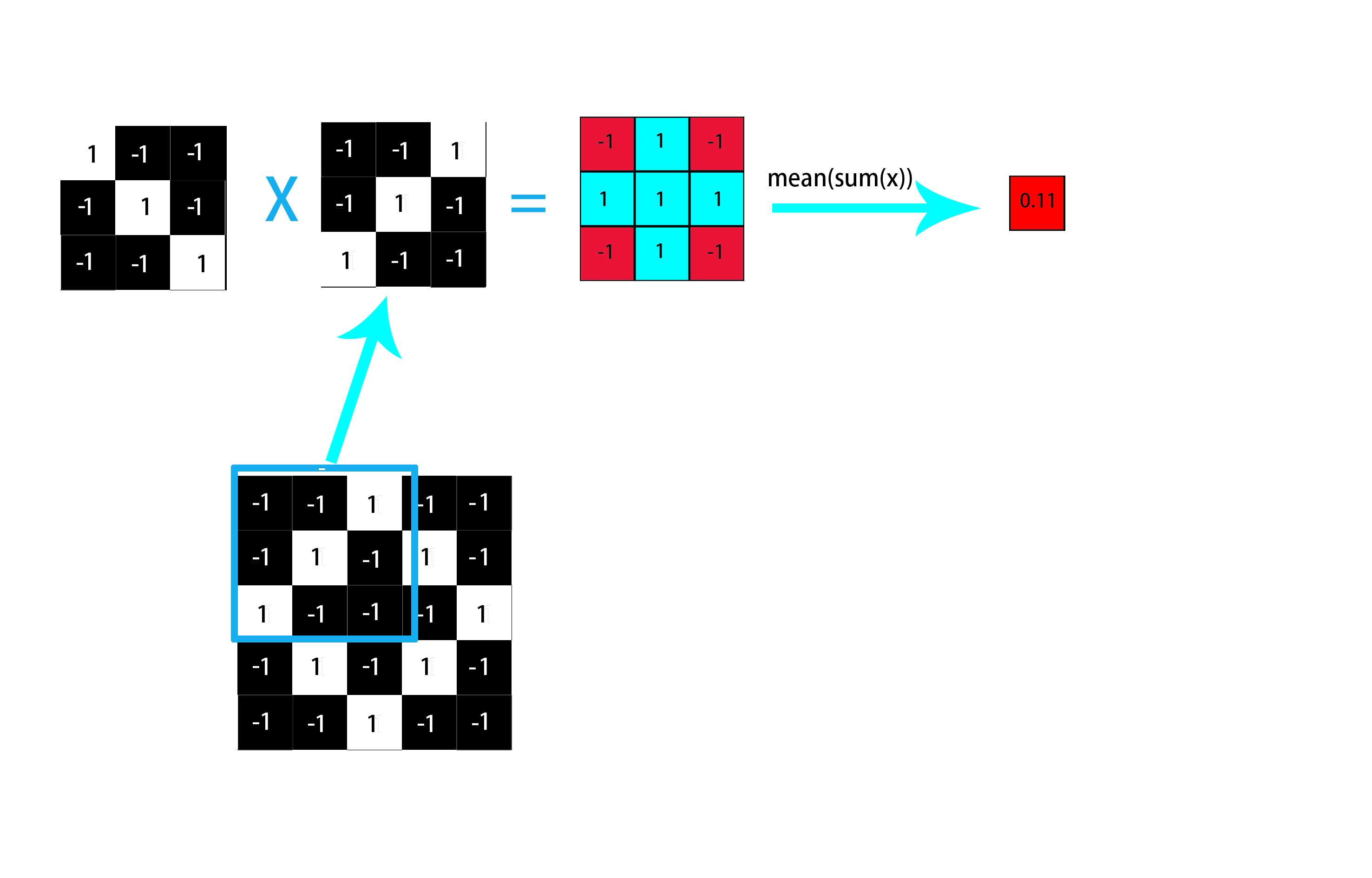
如上图所示我们选取原始图片中的第一个窗口与正斜线卷积核进行卷积运算,首先两个矩阵对应位置相乘得到一个新的矩阵(其实我们可以发现,如果对应位置的两个像素越相近,那么对应相乘起来的值也就越大),再对新的矩阵求和取平均之后可以得到一个代表匹配程度的数值(同理,如果整个窗口与卷积核相似的像素越多,则得到的该数值也就越大),这个数值稍后将填入特征图的第一行第一列元素,代表原始图中第一个窗口与卷积核的匹配程度为0.11。
理解了卷积运算之后,我们从左到右,从上到下移动窗口分别与选定卷积核做卷积运算(这边请注意,窗口的移动步长是可以设置的,这边默认步长为1),最后可以得到关于该卷积核的特征图(特征图中的元素描述图片对应窗口与该卷积核的匹配程度)。最终得到的特征图(feature map)如下(可以理解成是一个特征提取过程图片压缩过程,作为后续卷积层的输入):
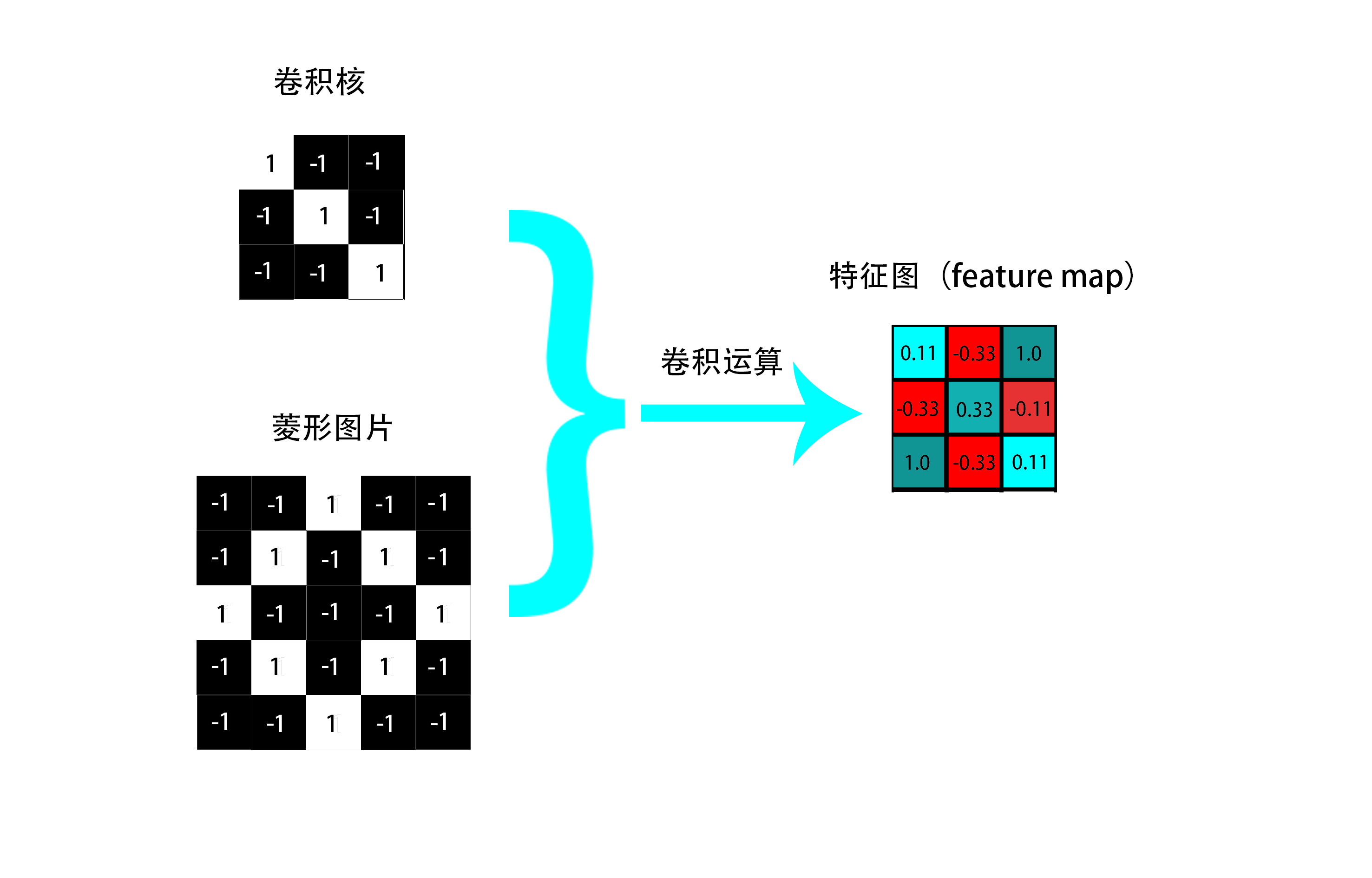
值得说明的一点是:feature map上的每个元素代表卷积核与原始图种对应位置特征的匹配程度,值越大原始图中对应位置与卷积核携带的特征越相似。并且,
每一个卷积核与原始图片进行卷积运算都能得到一个对应的特征图(feature map),卷积核有多少个,经过卷积层运算之后得到的特征图就有多少个。
非线性激活层(ReLU)
与传统神经网络一样,卷积神经网络也需要使用激活函数来融入非线性特征(我觉得卷积运算应该是线性的,而且纯做线性变换的也没什么意思)。而卷积神经网络中现在比较常用的是ReLU激活函数(其实ReLU函数就是>=0的值不变,小于0的值变为0),ReLU激活函数的介绍可以参考我上一篇博客Pytorch_第九篇_神经网络中常用的激活函数。那卷积神经网络中的非线性激活层是怎么作用的呢?我们还是通过上述例子来进行说明:
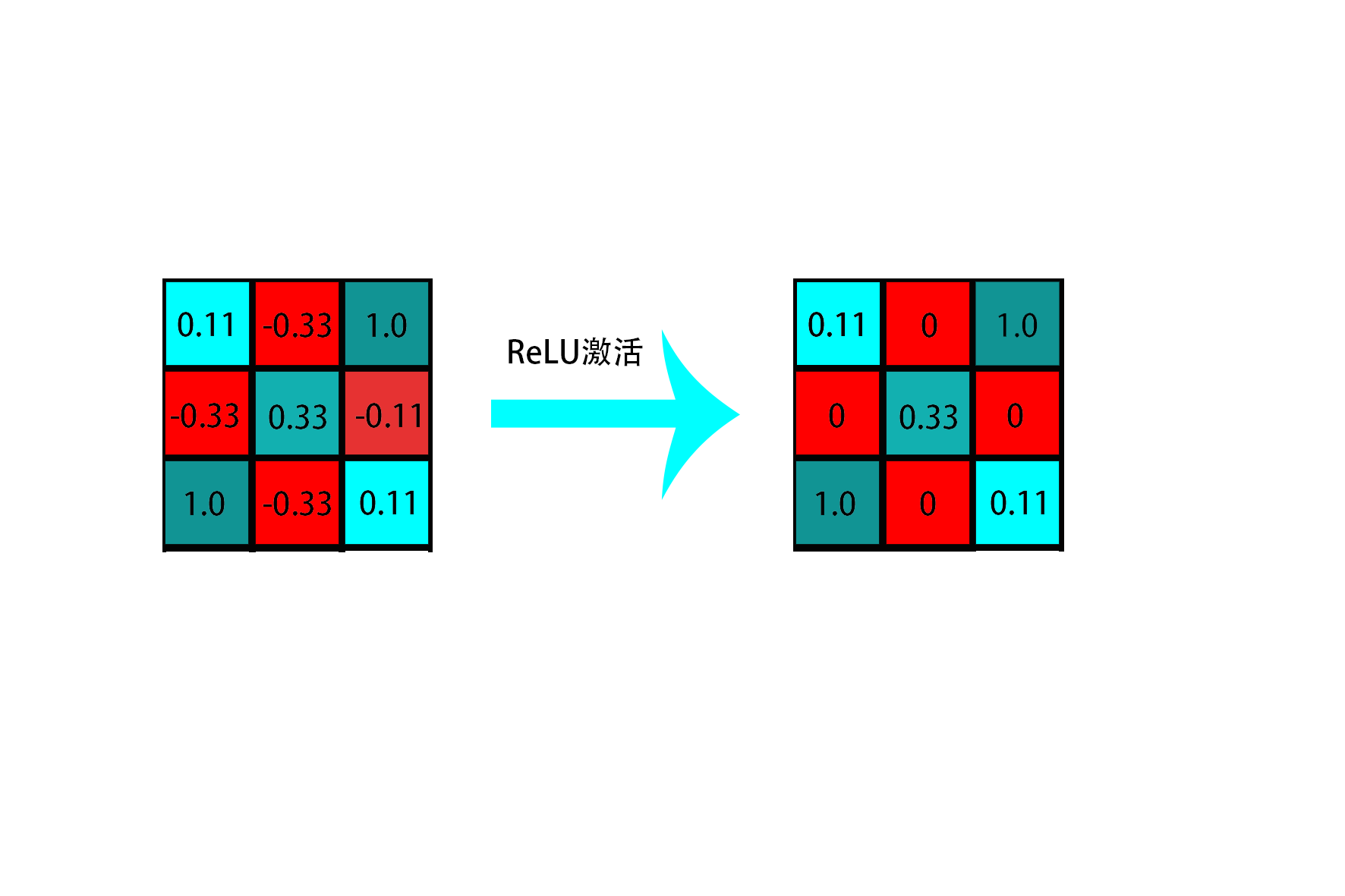
如上图所示,对特征图中每个元素进行ReLU激活,可以得到右图中特征图。我们可以发现多了很多0(需要注意的是,ReLU激活之后的数据量比原始图少了很多很多,后面可以通过池化层进一步削减数据量,毕竟深度学习图片领域的训练数据都是又大又多的,因此时间效率还是比较重要的),即我们通过ReLU激活将负相关的数据舍弃了,使得矩阵变成了一个更加稀疏的矩阵,操作起来也更加方便。(并且若是在大规模网络中,对稀疏矩阵的处理也更加快速,有效率!!)
池化层(pooling)
在介绍池化层之前,我们先捋一捋到现在我们做了什么。卷积层通过卷积运算提取特征,得到比原始图更小的特征图,之后我们再通过ReLU层将特征图中的负相关的数据置为0,得到了一个更加稀疏的特征矩阵,数据量进一步减少了,但是这还不够,我们这儿通过池化层进一步削减数据量。
首先,我们需要先了解一下池化的概念。有两种池化方式,分别是最大池化(Max Pooling)、平均池化(Average Pooling)。顾名思义,最大池化就是取最大值,平均池化就是取平均值。其次我们通过上述同样的例子来理解以下池化层具体做了什么操作。 假设池化窗口我们设置为2X2,类比于卷积层在滑动窗口上不断做卷积运算,池化层就是在滑动窗口上不断做池化运算,那池化运算怎么做呢(最大池化,取窗口内的最大值;平均池化,取窗口内的平均值)?以最大池化为例,如下图所示:

(看着上面这个图,应该很容易理解最大池化怎么做了吧?)
由于最大池化保留了每个小窗口内的最大值,因此可以认为最大池化相当于保留了窗口内的最佳匹配结果。现在从图片压缩角度来看看从卷积层、ReLU层到现在的池化层,我们原始的输入大小是怎么变化的。原始输入是5X5的一个矩阵(先假设通道为1,即不算三原色),经过卷积层、ReLU层之后变为3X3稀疏矩阵,再经过池化层之后变为了2X2矩阵,是我们肉眼可见的压缩啊!!其实每一层也可以理解成是在做特征提取,只是最开始提取的可能是比较局部的特征(比如边缘啊,斜边啊啥的),而层层叠加之后提取的可能是比较全局的一个特征,比较形状啊啥的,对于CNN各层(卷积、ReLU、池化),我个人大概是这么理解的。(以上各层是可以反复使用的,取决于我们的具体需求)
全连接层(Full-Connected)
在讲全连接层之前,我们需要知道全连接层之前的所有操作都是在做一个特征提取,提取出来的特征输入全连接层,利用全连接层来判定该图片是属于哪一个类型的图片(其实就是分类,如菱形、正方形、长方形等等)。之前在pytorch_第四篇_使用pytorch快速搭建神经网络实现二分类任务(包含示例)我们学习过利用神经网络来进行分类,那卷积网络中的全连接层与传统神经网络是类似的。接受样本的特征作为输入,输出样本所属各个类的概率,这是全连接层所做的事情。那卷积神经网络中的特征怎么来呢?别忘了,全连接层之前都是在做特征提取,如上述例子所示,假设我们最终得到了一个2X2的特征图,我们把特征图摊开来排成一排,也就意味着我们提取了原始图片的4个特征,这4个特征值输入全连接层可以帮助我们进行图片的分类。该层的结构就和传统的神经网络类似(全连接),这里不再赘述。
Softmax层
假设每个样本有一个隶属向量V,长度为类数,元素值代表该样本属于对应类别的概率,我们可以利用softmax函数来进行一个概率归一化。softmax函数如下所示(对v中第i个向量做归一化操作,即该元素的指数,与向量中所有元素指数和的比值):
由于多分类任务中模型输出样本对多个类的隶属概率,因此我们再最后一层加入Softmax函数来进行一个概率归一化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号