Scrapyd+Gerapy部署Scrapy爬虫进行可视化管理
Scrapy是一个流行的爬虫框架,利用Scrapyd,可以将其部署在远程服务端运行,并通过命令对爬虫进行管理,而Gerapy为我们提供了精美的UI,可以在web页面上直接点击操作,管理部署在scrapyed上的爬虫,本文介绍Scrapyd与Gerapy的基本安装与使用方法
一、Scrapyd简介:
Scrapyd是一个服务,允许用户将爬虫部署在服务端,并通过HTTP JSON的方式控制爬虫,并且可以通过web页面监控爬虫状态
二、Scrapyd安装部署:
在向服务器部署爬虫时,我们需要下载2个模块
1、scrapyd(安装在服务端,运行服务)
2、scrapy-client(安装在客户端,用于将自己的爬虫部署到服务器上)
- 服务端安装部署:
首先在远程的Ubuntu服务器上安装scrapyd:
pip install scrapyd
安装完毕后,查看scrapyd的配置文件,scrapyd会在如下位置依次查找配置文件,并以最后一个找到的配置文件为准进行配置
/etc/scrapyd/scrapyd.conf (Unix)
c:\scrapyd\scrapyd.conf (Windows)
/etc/scrapyd/conf.d/* (in alphabetical order, Unix)
scrapyd.conf
~/.scrapyd.conf (users home directory)
查看scrapyd的安装目录 */site-packages/scrapyd,发现有一个default_scrapyd.conf默认配置文件,打开该文件,显示如下内容
这里有一个名为bind_address的选项,默认值为127.0.0.1,我们将其改为0.0.0.0( 在服务器中,0.0.0.0指的是本机上的所有IPV4地址,如果一个主机有多个IP地址,并且该主机上的一个服务监听的地址是0.0.0.0,那么通过多个ip地址都能够访问该服务。)

配置完毕后输入Scrapyd &启动后台服务
此时输入netstat -an | grep 6800查看,发现6800端口已经启动监听

随后,打开浏览器,输入 服务端地址:6800,显示如下页面,配置成功![]()
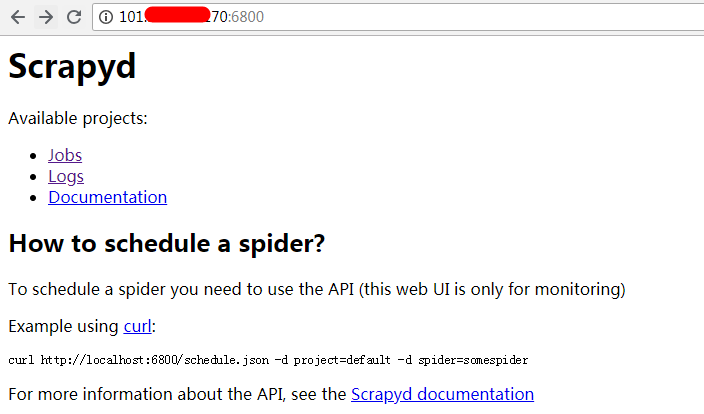
不过,此时,我们发现页面中的Available projects一行为空,这是因为我们还没有部署任何Scrapy爬虫项目,接下来,我们要将客户端的Scrapy项目部署到服务器上运行
- 客户端安装部署:
pip install scrapy-client
执行完毕后,找到scrapy-client的安装目录,发现一个名为scrapyd-deploy的文件,我们把它复制到scrapy项目中与scrapy.cfg同级的目录中(不复制也可以,但这样操作会方便一点)
打开scrapy.cfg文件,有如下内容,需要做的就是把[deploy]改为[deploy:target]的形式,target名称自拟,然后再把url前的注释去掉,并且将地址改为scrapyd的服务器地址。
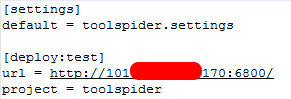
修改完毕后,我们需要用刚刚复制来的scrapyd-deploy来部署爬虫,打开scrapyd-deploy文件,找到如下部分,给出了scrapyd-deploy可以接收的参数以及相应的作用

我们发现输入-l可以列出所有可用的target,由于scrapyd-deploy本身是一个python文件,因此我们输入
python scrapyd-deploy -l来查看target的配置情况

查看结果与刚才在scrapy.cfg文件中的配置相同。
随后输入python scrapyd-deploy -L test来查看名为test的target下可用的爬虫项目

同样与配置相符
随后我们输入python scrapy-deploy test -p toolspider 将test中的toolspider项目部署到scrapyd服务端

出现以上信息,代表部署成功,此时打开 服务器地址:6800 这个页面,发现Available projects中已经有了我们刚刚部署的toolspider项目
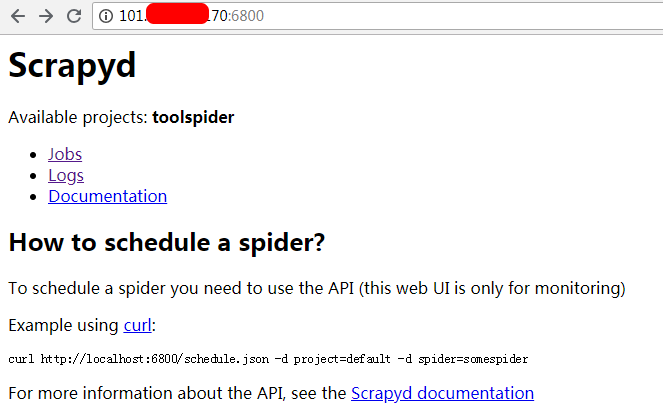
三、使用Scrapyd管理爬虫
Scrapyd采用http与json的方式管理爬虫,下面来看一下具体的用法
1、执行爬虫
执行爬虫用到的是schedule.json,通过向http://localhost:6800/schedule.json提交post请求并附带项目名以及爬虫名参数完成
在服务端输入curl http://localhost:6800/schedule.json -d project=toolspider -d spider=toolspider执行刚才部署的爬虫(d表示data,即post请求提交的数据),执行完毕后返回如下结果

此时再查看浏览器,Scrapyd页面,点击Jobs,出现如下信息,爬虫执行完毕

2、查看项目
查看项目用到的是listprojects.json,此方法采用get方式提交,不接受参数,可以直接在浏览器端提交并查看返回结果

同样,在服务端输入curl http://localhost:6800/schedule.json也可以得到结果

查看项目中的爬虫,用到的是listspider.json,同样也是get方法,接受一个project参数,即具体项目名,效果如图

3、删除项目
删除项目用到的是delproject.json,采用post方法,提交一个项目名称的数据
在服务端输入curl http://localhost:6800/schedule.json -d project=toolspider即可删除
4、其他
除此之外还有daemonstatus.json,addversion.json,listversions.json,delversion.json,cancel.json,listjobs.json,具体使用方法可以查看scrapyd官方文档https://scrapyd.readthedocs.io/en/stable/
四、采用Gerapy管理爬虫
scrapyd采用命令行的形式,通过http与json对爬虫进行管理,操作显得有些繁琐,对爬虫的状态展示也不直观,而Gerapy为我们提供了精美的UI与简介的操作方式,只需要用鼠标在浏览器上点击操作便可以完成对爬虫的管理,需要注意的是,Gerapy只为我们提供了操作界面,真正的爬虫还是部署在服务器的Scrapyd上,
1、Gerapy下载
pip install gerapy
下载完成后在命令行中输入gerapy,出现如下信息说明安装成功

2、Gerapy初始化
gerapy init
cd gerapy
gerapy migrate
在命令行中输入gerapy init,执行完毕后在当前目录下会生成一个名称为gerapy的文件夹,随后进入该文件夹,下输入gerapy migrate ,成功后在gerapy目录下生成一个sqlite数据库
3、运行Gerapy
gerapy runserver
出现如下信息表示执行成功

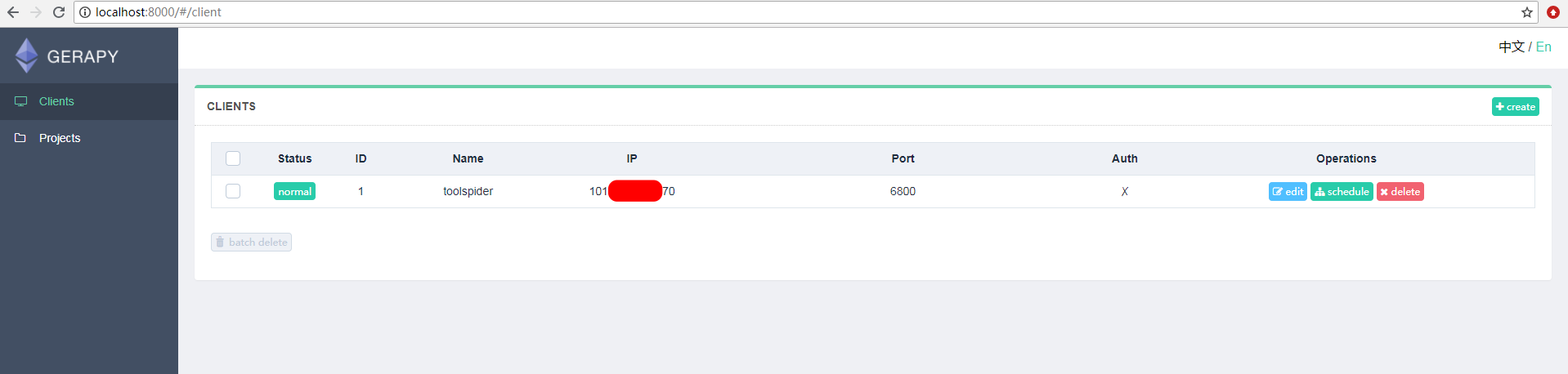
随后在浏览器中输入127.0.0.1:8000打开gerapy界面如图,我这里已经配置了一台远程服务器,因此normal显示为1

点击左侧的Client,随后在Client界面的右上角点击create创建远程主机

输入Scrapyd服务器的ip与端口(6800),自己随便起个名字,完成配置,结果显示如下
要执行爬虫,直接点击右侧的schedule便可以显示出当前项目中的所有爬虫信息,点击run按钮便可直接运行爬虫,并实时在页面上显示状态


 浙公网安备 33010602011771号
浙公网安备 33010602011771号