
大数据痛点及问题
大数据实时处理业务架构:
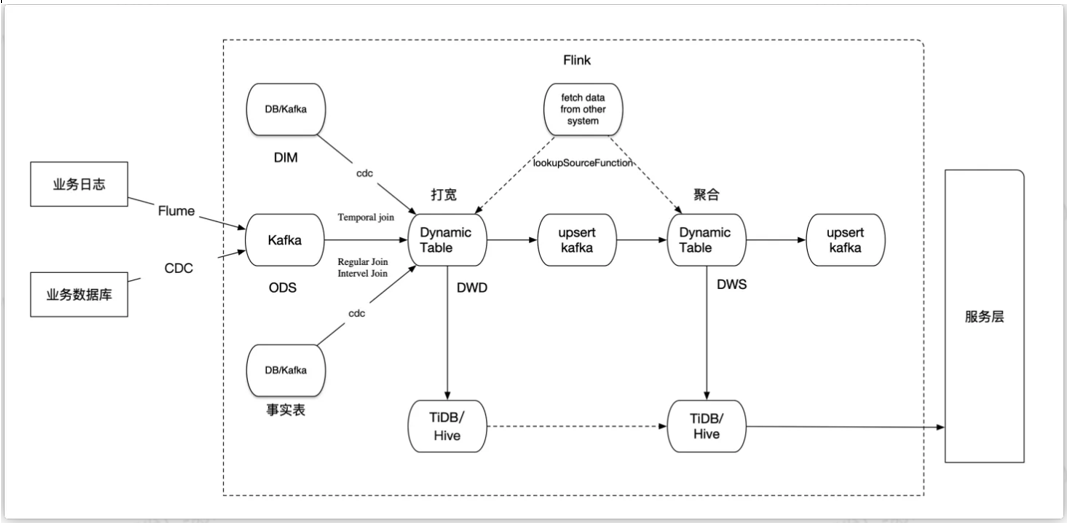
除20%的代码设计问题之外,80%为配置、环境、数据延迟、堆压、丢失、重复问题;
(1)mysql或tidb-FLINK CDC同步kafka延迟
数据库连接数限制:Oracle 数据库通常有连接数限制,如果连接数超过了限制,就会导致同步延迟增加。可以通过修改数据库参数或者调整 Flink CDC 的配置来解决这个问题。
大事务量:如果源数据库中的事务量很大,同步的数据量也会很大,从而导致同步延迟增加。可以通过优化 SQL 或者增加并发度来解决这个问题。
索引问题:索引可以提高数据库的查询效率,但是如果索引过多或者过于复杂,就会导致同步延迟增加。可以通过优化索引或者禁用不必要的索引来解决这个问题。
网络带宽和延迟:网络带宽和延迟也会影响同步延迟。如果网络带宽不足或者存在较大的延迟,就会导致同步延迟增加。可以通过优化网络设置或者使用高速网络来解决这个问题。
(2)flink state默认保留数据为48小时,某些订单极端场景超过48小时,订单状态才更改,导致销售额等指标未被累计计算出现错误
(3) kafka常见问题:
a、数据积压: 分区、线程组不够,数据量太大
b、数据丢失:broker异常丝机,副本节点数据还没来得及备份
或者consume在fetch数据时,还没消费完,就执行commit offset的更改,导致数据丢失
c、kafka重复消费数据
(1)强行kill线程,导致消费后的数据,offset没有提交,partition就断开连接,引起再连接时重复消费;
(2)消费数据,处理很耗时,kafka侧由于服务端处理业务时间长或者网络链接等等原因让kafka认为服务假死,导致超过了kafka的session-timeout时间,就会触发分区re-balance,一定几率offset没提交,会导致平衡后重复消费


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架